由南洋理工大学、新加坡国立大学、腾讯、北京工业大学与北京航空航天大学联合研发,Mini-Omni-Reasoner 正式推出——这是一次将推理能力引入大型语音模型(Large Speech Models, LSMs)的前沿探索。
当前阶段,该模型聚焦于数学推理任务,但它提出了一种全新的交互范式:“边说边思考”(thinking-in-speaking)。不同于传统模型必须完成全部推理后才开始输出语音,Mini-Omni-Reasoner 能在说话过程中同步进行内部推理,实现真正意义上的实时语音智能交互。
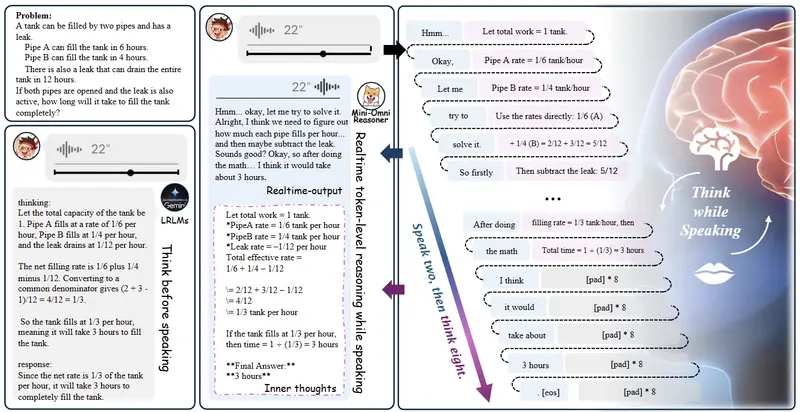
这一设计不仅显著降低响应延迟,还使回答更简洁自然,为未来语音助手、教育机器人等实时对话系统提供了新的技术路径。
“先想完再说”为何不适合语音交互?
在典型的语音生成流程中,模型通常遵循“先思考后说话”(thinking-before-speaking)模式:
- 接收问题;
- 完成完整推理链;
- 生成最终答案文本;
- 合成为语音输出。
这种方式虽然保证了逻辑完整性,但在实际对话中带来明显问题:
- 高延迟:用户需等待数十秒才能听到第一句话;
- 冗长重复:模型倾向于复述整个推理过程;
- 缺乏临场感:不符合人类“一边组织语言一边表达”的交流习惯。
Mini-Omni-Reasoner 的目标,就是打破这种静态流程,让语音模型像人一样,在发声的同时完成思维演进。
核心技术:如何实现“边说边思考”?
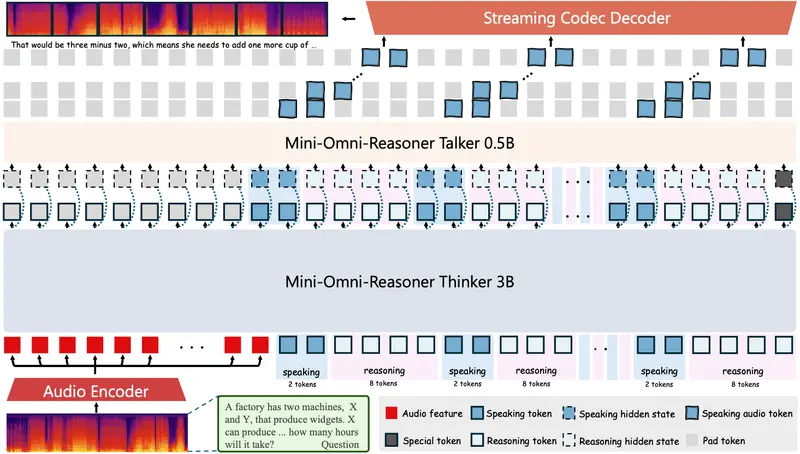
Mini-Omni-Reasoner 的核心在于构建一个支持推理与语音交错生成的架构。它不依赖事后补全或后期剪裁,而是从生成源头就实现动态穿插。
1. 交错式 token 生成机制
模型在输出序列中交替生成两类 token:
- 回答 token:用于构成最终语音输出的内容;
- 推理 token:仅参与内部计算,不会被合成语音。
例如,默认比例设置为 2:8(每生成 2 个回答 token,插入 8 个推理 token),确保深层推理不受影响,同时维持语音流畅度。该比例可根据应用场景灵活调整。
类比人类表达:我们在说“A 等于 B”之前,大脑可能已默默完成了多步推导,但这些中间步骤并不需要说出来。
2. 控制机制保障稳定性
为防止长对话中出现语义漂移或节奏失控,Mini-Omni-Reasoner 引入带填充的控制 token,显式标记推理块边界,实现:
- 精确调控推理密度;
- 维持生成节奏一致性;
- 提升行为可预测性。
3. 流式处理支持实时交互
得益于交错生成结构,模型可在接收到语音输入后立即启动响应流程,无需等待完整上下文解析完毕。即使推理尚未结束,也能提前输出初始语句,实现接近“零等待”的交互体验。
数据支撑:Spoken-Math-Problems-3M 数据集
要训练具备语音推理能力的模型,首先需要匹配的数据。团队发布了 Spoken-Math-Problems-3M——一个包含 300 万条口语化数学问答对的大规模数据集。
数据来源涵盖 Orca-Math、MetaMath、GSM8K 和 SimpleOP 等高质量文本资源,经过四阶段处理构建而成:
- 问题采集:从多个公开数学 QA 数据集中筛选多样化题目;
- 口语化改写与拆分:将标准答案转化为自然口语表达,并分离出“推理轨迹”与“简明回答”;
- 语音合成与 token 对齐:使用高保真 TTS 生成语音,按 2:8 比例交错插入推理与回答 token;
- 语义一致性验证:通过 GPT 进行自动校验,剔除逻辑错乱或不匹配样本。
这一流程确保了数据在规模、质量和逻辑连贯性上的统一,为“边说边思考”模型提供了坚实基础。
特别感谢吴长桥在技术方案与工程实现中的关键贡献。
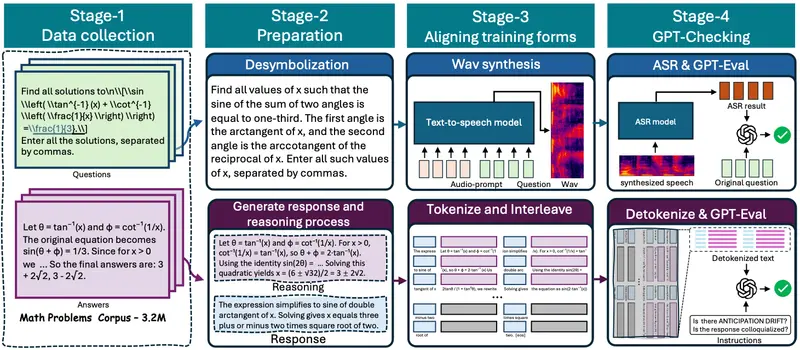
训练策略:分阶段迁移推理能力
Mini-Omni-Reasoner 基于 Qwen2.5-Omni-3B 构建,采用五阶段渐进式训练方法,逐步实现从文本推理到语音推理的能力跃迁:
| 阶段 | 目标 |
|---|---|
| 🔹 对齐训练 | 微调音频适配器,统一特殊 token 表示,弥合架构差异 |
| 🔹 数学混合预训练 | 在文本与语音数学数据上联合训练,强化基础推理能力 |
| 🔹 文本“边说边思考” | 训练 LLM 在文本序列中实现推理/回答 token 交错生成 |
| 🔹 语音“边说边思考” | 将交错机制迁移到语音输入场景,微调音频编码器 |
| 🔹 语音合成优化 | 冻结推理模块,单独训练语音解码器,提升语音自然度 |
这种分阶段策略有效避免了端到端训练中的不稳定问题,同时保证各模块功能解耦、易于调试。
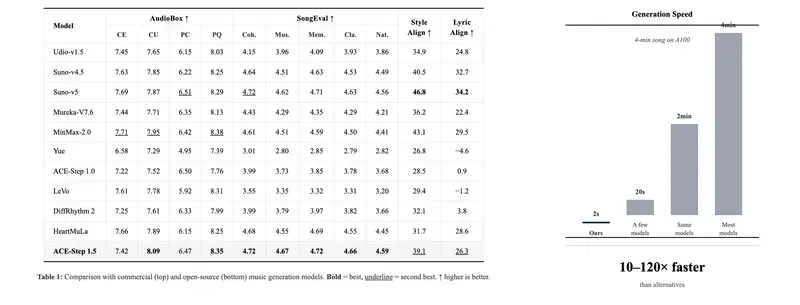
性能表现:更快、更短、更准
在自建基准测试集 Spoken-MQA 上,Mini-Omni-Reasoner 展现出全面优势:
| 指标 | 结果 |
|---|---|
| ✅ 算术推理准确率 | 从 64.9% → 77.25%(+12.35pp) |
| ✅ 上下文推理准确率 | 从 64.0% → 68.1%(+4.1pp) |
| 📏 平均回答长度 | 从 116.1 词 → 42.9 词(减少约 63%) |
| ⏱️ 端到端响应延迟 | 从 33 秒 → 17 秒(降低近半) |
值得注意的是,其推理能力已接近参数量更大的 Qwen2.5-Omni-7B 模型,而语音输出更为精炼高效。
此外,在真实语音对话测试中,用户普遍反馈其表达更具“临场反应感”,减少了机械背诵式的冗余陈述。
意义与展望
Mini-Omni-Reasoner 并非仅仅是一个性能更强的语音模型,它代表了一种新的人机交互哲学:推理不应是沉默的前置步骤,而应融入表达本身。
尽管目前仅支持数学推理任务,但“边说边思考”范式具有广泛延展潜力:
- 可拓展至常识推理、规划决策等复杂场景;
- 支持多轮持续推理,在对话中动态更新结论;
- 结合视觉输入,发展为多模态实时推理系统。
随着语音接口在车载、家居、教育等场景的普及,具备内生推理能力的 LSM 将成为下一代智能体的核心组件。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...