
在视觉和文本领域大模型持续突破之后,音频理解也开始迎来新的里程碑。英伟达近日发布了 Audio Flamingo 3(AF3),这是目前最先进的开源大型音频语言模型(Large Audio Language Model, LALM),不仅能够“听”,还能理解和推理声音内容,包括语音、环境音、音乐等,标志着向真正的音频通用智能迈出了重要一步。
- GitHub:https://github.com/NVIDIA/audio-flamingo
- audio-flamingo-3:https://huggingface.co/nvidia/audio-flamingo-3
- audio-flamingo-3-chat:https://huggingface.co/nvidia/audio-flamingo-3-chat
- Demo:https://huggingface.co/spaces/nvidia/audio-flamingo-3
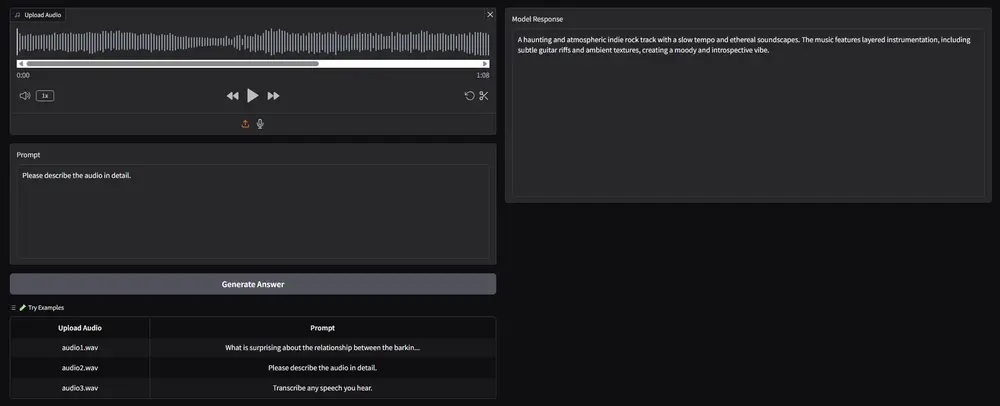
从“听见”到“听懂”:Audio Flamingo 3 的突破
传统音频模型大多只能完成基础任务,例如语音识别或音频分类。而 AF3 则完全不同——它不仅能转录音频内容,还能:
- 理解音频语境
- 进行多轮对话
- 推理长时间音频信息
- 支持语音到语音交互
- 实现按需思维链式推理
这一切使得 AF3 成为了目前最接近人类听觉理解能力的 AI 模型之一。
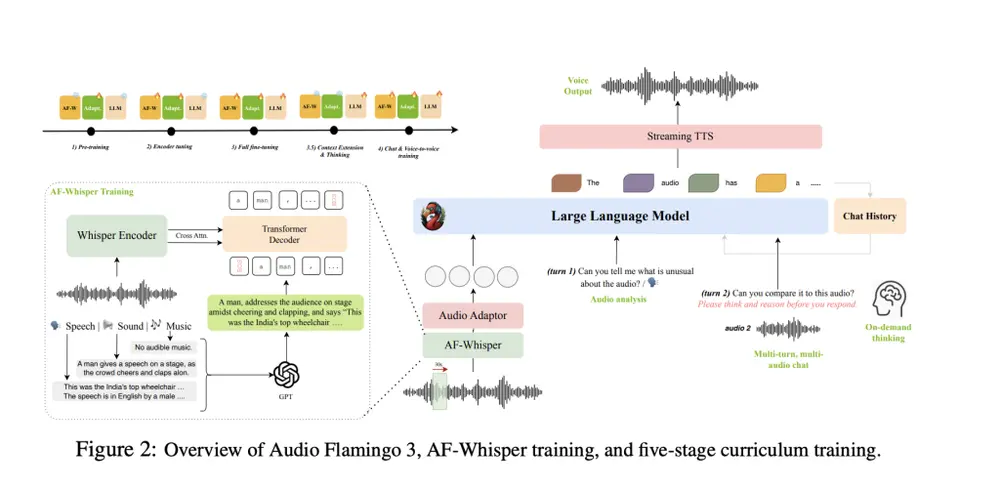
核心技术创新
AF-Whisper:统一音频编码器
AF3 使用基于 Whisper-v3 改进的新编码器 AF-Whisper,首次实现了对语音、环境音和音乐的统一建模。相比以往需要不同编码器处理不同类型音频的方式,AF-Whisper 构建了一个统一的嵌入空间(1280 维),使模型能更准确地将音频与文本对齐。
音频的“思维链”:按需推理能力
通过训练数据集 AF-Think(含 25 万个示例),AF3 能在用户提示下进行“思考”,以思维链方式解释其推理过程,实现更透明、可信的音频理解系统。
多轮、多音频对话支持
借助 AF-Chat 数据集(7.5 万条对话),AF3 能够模拟真实场景中的多音频输入对话行为,例如根据之前听到的内容回答后续问题,实现更具逻辑性的交互体验。
此外,AF3 还集成了流式文本转语音模块,支持完整的语音到语音对话流程。
长音频理解能力
AF3 是首个完全开源、支持长达 10 分钟音频输入的模型。通过 LongAudio-XL 数据集(125 万个示例)训练,AF3 可胜任会议摘要、播客分析、讽刺检测、时间定位等复杂任务。

性能领先多个基准测试
AF3 在超过 20 个主流音频相关基准测试中表现优异,部分关键指标如下:
| 基准 | AF3 得分 | 对比模型 |
|---|---|---|
| MMAU(平均) | 73.14% | Qwen2.5-O: 71.00% |
| LongAudioBench(GPT-4o 评估) | 68.6 | Gemini 2.5 Pro: 66.2 |
| LibriSpeech(词错误率) | 1.57% | Phi-4-mm: 1.72% |
| ClothoAQA | 91.1% | Qwen2.5-O: 89.2% |
在语音生成方面,AF3 的生成延迟仅为 5.94 秒(Qwen2.5 为 14.62 秒),且相似性评分更高,展现了出色的实时响应能力。
数据驱动:构建音频理解的基础
为了支撑 AF3 的强大能力,英伟达还开发并开源了一系列高质量训练数据集:
| 数据集 | 规模 | 功能 |
|---|---|---|
| AudioSkills-XL | 800 万 | 环境音、音乐、语音联合推理 |
| LongAudio-XL | 125 万 | 支持长音频建模 |
| AF-Think | 25 万 | 实现短思维链推理 |
| AF-Chat | 7.5 万 | 多轮多音频对话 |
这些数据集连同训练代码、推理工具一并开源,极大促进了音频理解和多模态研究的发展。
完全开源:开放科研与应用的可能性
AF3 不仅仅是一个模型发布,而是一整套开源解决方案,包括:
- ✅ 模型权重
- ✅ 训练配方
- ✅ 推理代码
- ✅ 四大数据集
这种高透明度的开源策略,使其成为当前最容易获取的先进音频语言模型,也为未来的研究者和开发者提供了坚实的基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











