
随着语音逐渐成为人机交互的核心方式,法国AI初创公司 Mistral 正式发布其首个开源音频模型 Voxtral,标志着其在语音智能领域的重大突破。
Voxtral 是一款面向企业的语音理解模型(Speech Understanding Model),不仅具备高精度的语音转录能力,还支持对音频内容的深度语义理解,如问答、摘要、翻译和功能调用。
- Voxtral-Mini-3B-2507:https://huggingface.co/mistralai/Voxtral-Mini-3B-2507
- Voxtral-Small-24B-2507:https://huggingface.co/mistralai/Voxtral-Small-24B-2507
它的发布旨在打破当前语音系统“封闭、昂贵、部署受限”的格局,为开发者和企业提供一个开放、灵活且成本更低的语音交互解决方案。
为什么是语音理解?
语音是人类最早、最自然的交流方式。随着AI技术的发展,语音正重新成为我们与数字系统交互的首选方式。
然而,目前的语音系统仍存在诸多局限:
- 🧠 仅提供基础转录,缺乏语义理解;
- 🚫 依赖封闭模型,难以定制与部署;
- 💰 成本高昂,尤其在企业级应用中。
Voxtral 的推出,正是为了填补这一空白。
Voxtral 的核心能力
Mistral 提供了两个主要模型变体:
| 模型 | 参数规模 | 适用场景 |
|---|---|---|
| Voxtral Small | 240亿 | 生产级部署,对标 ElevenLabs Scribe、GPT-4o-mini |
| Voxtral Mini | 30亿 | 本地/边缘部署,轻量级语音理解与转录 |
| Voxtral Mini Transcribe | 30亿(精简版) | 仅转录场景,优化成本与速度 |
✅ 主要功能亮点:
- 长音频支持:可处理长达30分钟的音频转录,理解能力扩展至40分钟;
- 内置问答与摘要:无需串联 ASR 与 LLM,直接从语音中提取结构化信息;
- 多语言支持:涵盖英语、西班牙语、法语、葡萄牙语、印地语、德语、荷兰语、意大利语等主流语言;
- 语音触发功能:可直接将语音指令转化为API调用或系统动作;
- 文本理解能力保留:基于 Mistral Small 3.1,具备与当前主流语言模型相当的语义理解能力;
- Apache 2.0 开源许可:支持灵活部署,适用于本地、边缘和云环境。
与现有模型对比:性能更优,成本更低
Mistral 强调,Voxtral 在多个关键指标上超越主流闭源模型,同时保持显著的价格优势:
| 功能 | Voxtral Small | Voxtral Mini | Whisper large-v3 | GPT-4o mini | ElevenLabs Scribe |
|---|---|---|---|---|---|
| 词错率(WER) | 优于开源模型 | 优于 Whisper | 中等 | 低 | 低 |
| 理解能力 | 强(支持问答、摘要) | 中等 | 弱 | 强 | 强 |
| 多语言支持 | 丰富 | 丰富 | 中等 | 丰富 | 丰富 |
| 部署灵活性 | 高(支持本地、边缘) | 高(轻量部署) | 高(但性能有限) | 低(依赖云端) | 低(闭源) |
| 价格 | 不到 ElevenLabs Scribe 一半 | 不到 Whisper 一半 | 开源免费 | 高 | 高 |
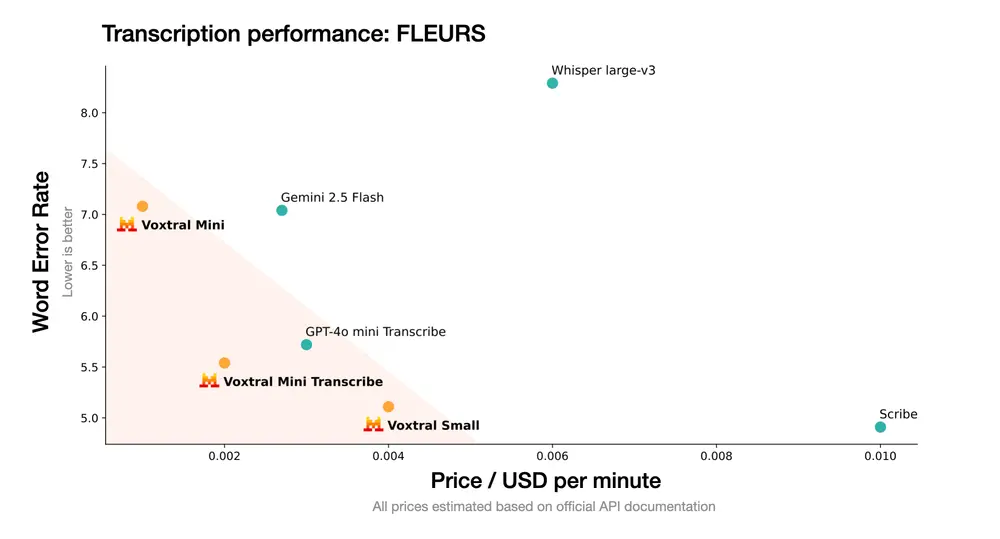
在多个基准测试中,Voxtral 全面超越 Whisper large-v3,并在英语短篇和多语言任务中达到当前开源模型的最先进水平。
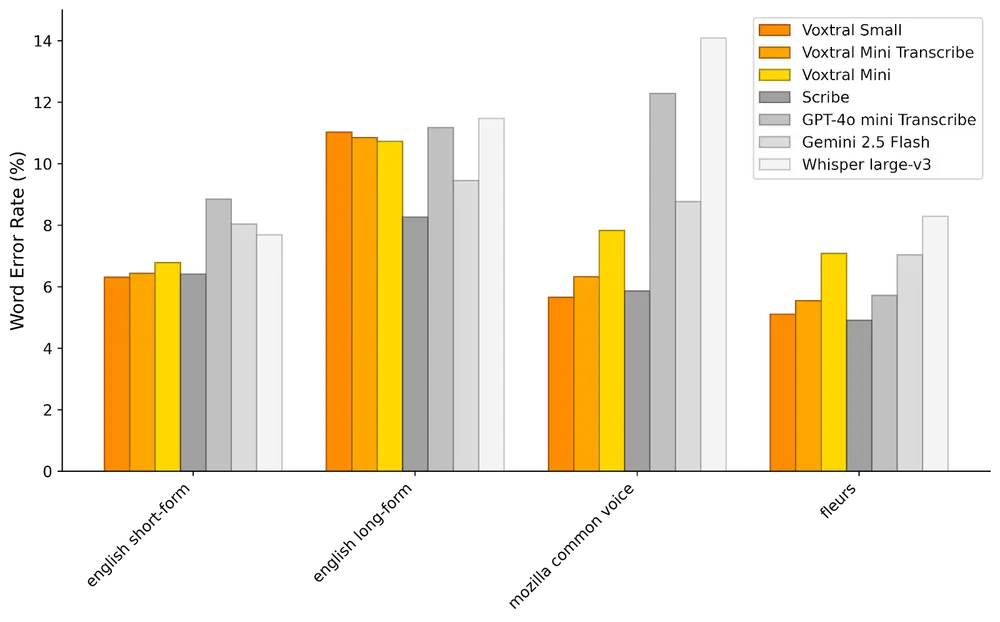
此外,Voxtral Small 在语音翻译任务中也表现出色,超过了 GPT-4o-mini 和 Gemini 2.5 Flash。
技术细节与能力扩展
📝 语音理解模型(Speech Understanding)
Voxtral 的语音理解模型不仅限于转录,它还能:
- 回答关于音频内容的问题
- 生成结构化摘要
- 直接解析语音指令并调用 API
- 支持语音到文本的翻译
Mistral 在内部构建了一个语音理解(AU)基准测试集,包含40个长篇音频样本,用于评估模型的深层理解能力。
🗣️ 语音转录模型(仅转录版本)
Voxtral Mini Transcribe 是一个精简版本,专注于高性价比的语音转录任务。它在性能上优于 Whisper,而成本不到其一半。
使用方式与部署选项
Mistral 提供多种使用方式,满足不同用户需求:
- Hugging Face 下载:开发者可直接下载模型权重,进行本地部署。
- API 调用:通过 Mistral 平台提供语音理解服务,起始价格为 每分钟 0.001 美元。
- Le Chat 体验:在 Mistral 的聊天机器人 Le Chat 中测试语音理解功能(即将向所有用户开放)。
此外,Mistral 还提供企业级部署方案,包括:
- 私有部署支持(适用于医疗、金融等敏感领域)
- 领域微调(法律、医疗、客服等专业场景)
- 上下文增强(支持说话人识别、情感分析、长窗口处理)
- 优先集成支持(专属工程资源协助部署)
免费试用与未来计划
开发者可通过以下方式免费体验 Voxtral:
- 在 Hugging Face 上下载模型;
- 使用 Mistral API 进行原型设计;
- 通过 Le Chat 测试语音理解功能。
Mistral 还计划在未来几个月推出更多高级功能:
- ✅ 发言人分割
- ✅ 情感与年龄识别
- ✅ 单词级时间戳
- ✅ 非语音音频识别
- ✅ 更长上下文窗口
此外,Mistral 与 Inworld 合作,将于 8 月 6 日展示一个完整的 语音到语音代理(Speech-to-Speech Agent)演示,展示语音驱动的 AI 应用新可能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











