Canopy Labs推出基于 Llama-3b 骨干网络构建的开源文本转语音(TTS)模型Orpheus TTS ,这款模型展示了利用大语言模型(LLM)进行高质量语音合成的能力。

模型规模与特性
Canopy Labs 提供了四种不同规模的预训练和微调模型,以满足不同的应用场景需求:
中等 – 30亿参数 小型 – 10亿参数 微型 – 4亿参数 纳米 – 1.5亿参数
尽管是较小规模的模型,它们仍能产生极高质量且令人愉悦的语音输出。这些模型经过精选语音数据的微调后,可以直接应用于生产环境。
易于使用的工具包
为了方便开发者使用,Canopy Labs 还提供了一个简易的 Python 包,支持实时流式处理代码。即使是在 A100 40GB GPU 上运行 30亿参数的模型,其流式推理速度也快于回放速度。
试用演示与资源
想要体验 Orpheus TTS 的实际效果吗?可以通过以下链接访问:
GitHub - Orpheus TTS 仓库 Hugging Face - 模型仓库 Google Colab - 交互式笔记本
技术亮点
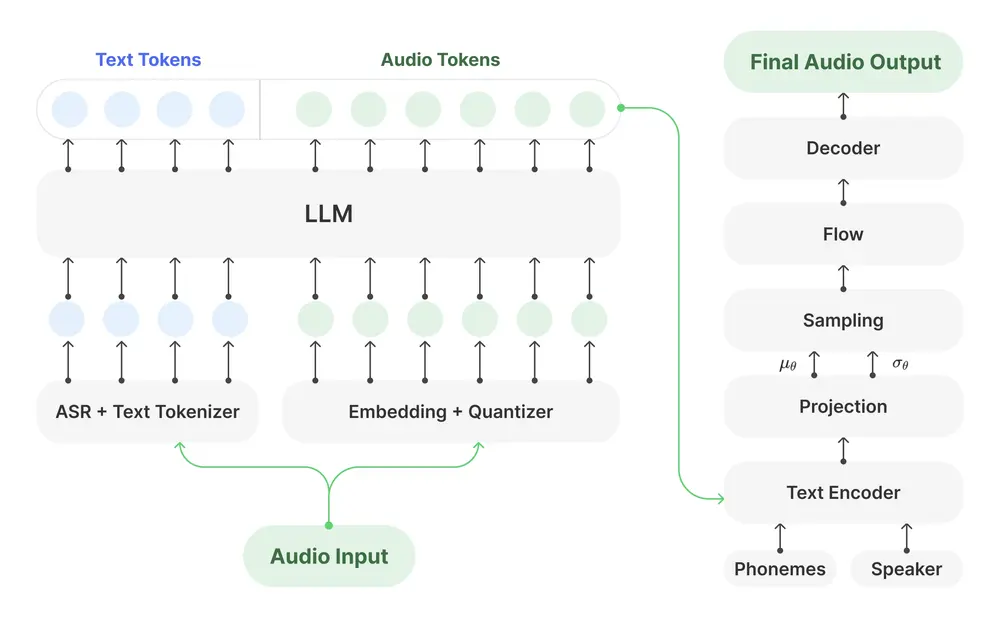
Orpheus TTS基于超过 10万小时的英语语音数据和数十亿文本 token 训练而成,保证了对语言的深刻理解。以下是部分技术亮点:
零样本语音克隆:无需专门训练即可实现自然的语音克隆。 情感和语调控制:通过少量高质量的示例即可教会模型特定的情感表达方式。 低延迟实时输出:支持对话场景下的低延迟(约200毫秒)实时输出,优化后的KV缓存技术可将延迟降至25-50毫秒。
创新的设计选择
在设计上,Canopy Labs采用了两种创新方法:
每帧获取7个token,并解码为单一扁平序列,增加了生成步骤的同时确保了流畅性。 使用非流式的分词器避免了传统方法中的爆音问题,实现了无爆音的流式传输。
Orpheus TTS 不仅展现了语音合成领域的前沿进展,也为开发者提供了灵活且强大的工具集。无论是追求高质量的语音生成还是探索最新的语音合成技术,Orpheus TTS 都是一个值得尝试的选择。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











