中央音乐学院、美国罗切斯特大学、北京飞天云动科技、北京航空航天大学和清华大学的研究人员推出符号音乐生成模型NotaGen,通过借鉴大语言模型(LLM)的训练范式来生成高质量的古典乐谱。其在超过 160 万首音乐作品上进行预训练而来。官方本次开源还包括了一个受 DeepSeekR1 启发的模型 Notagen-X,本地部署需要 24G 显存。
- 项目主页:https://electricalexis.github.io/notagen-demo
- GitHub:https://github.com/ElectricAlexis/NotaGen
- 模型:https://huggingface.co/ElectricAlexis/NotaGen
- Demo:https://huggingface.co/spaces/ElectricAlexis/NotaGen
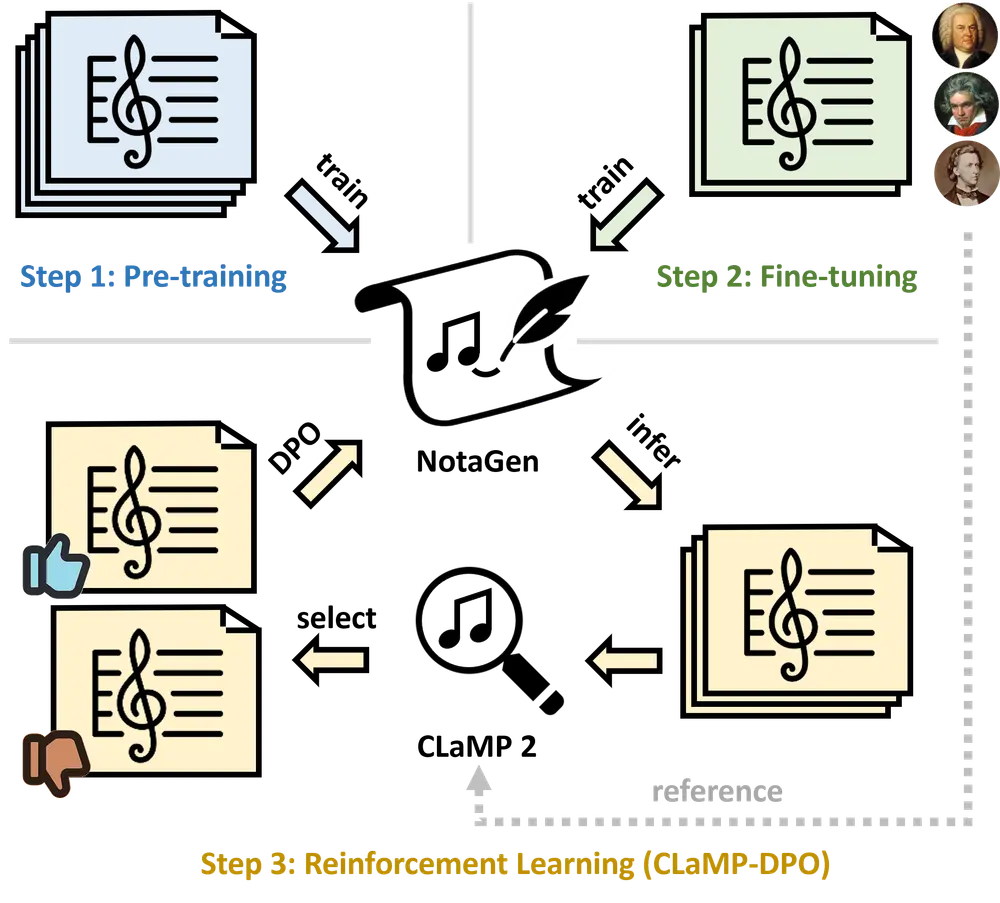
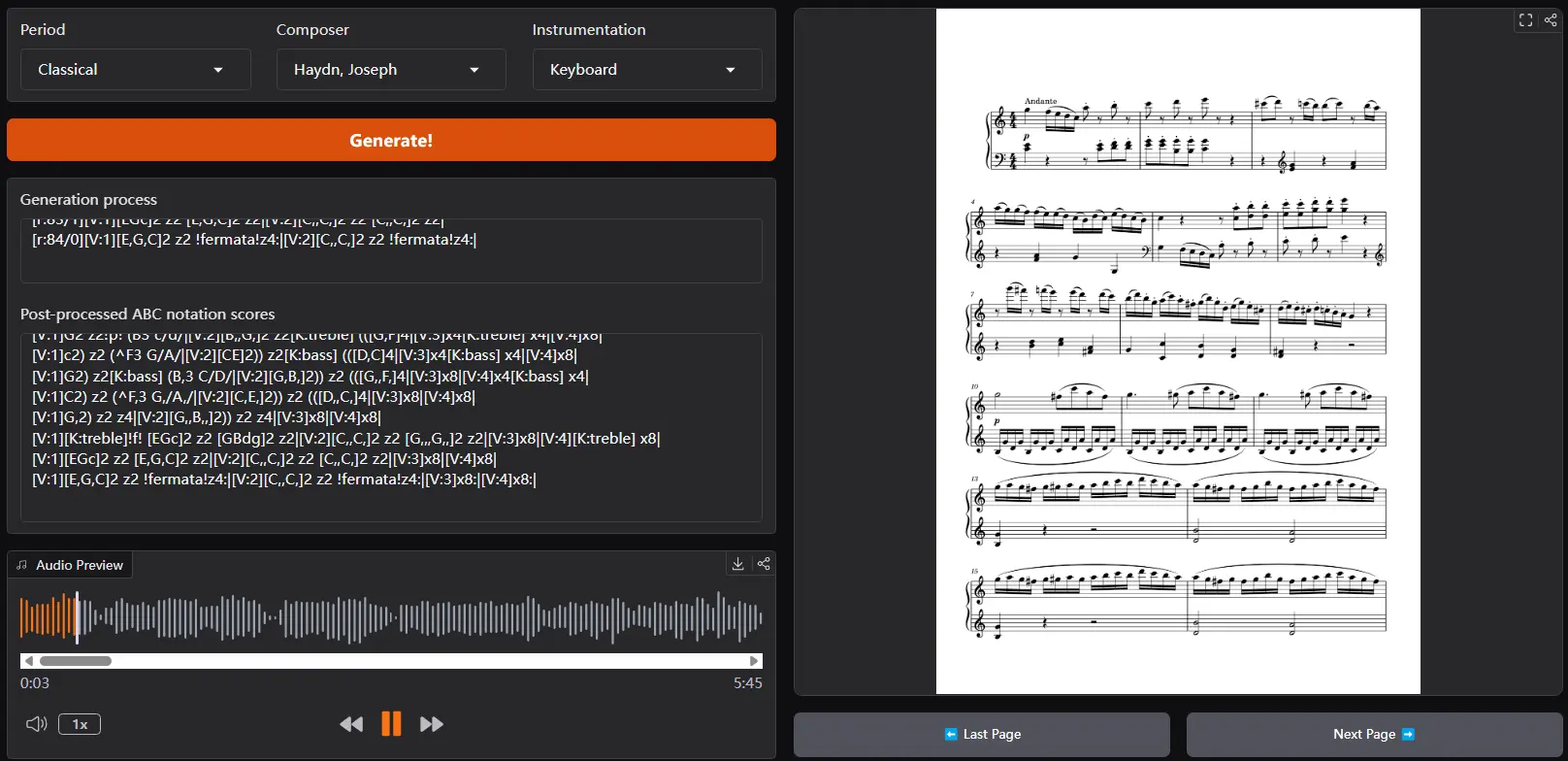
NotaGen 是一种符号音乐生成模型,专注于生成高质量的古典乐谱。它通过预训练、微调和强化学习三个阶段来提升生成音乐的音乐性(musicality)。例如,用户可以指定“巴洛克时期,巴赫风格,键盘乐器”的提示,NotaGen 将生成符合这些条件的乐谱。值得注意的是,该模型输出的不是音频文件,而是 ABC & xml 文件。
主要功能
- 高质量乐谱生成:生成符合古典音乐风格的高质量乐谱。
- 条件生成:根据“时期-作曲家-乐器”等提示生成特定风格的音乐。
- 音乐性提升:通过强化学习优化生成音乐的音乐性,使其更符合人类的审美标准。
- 兼容多种模型架构:适用于不同架构和编码方案的符号音乐生成模型。
主要特点
- LLM 训练范式:采用预训练、微调和强化学习的完整流程,提升生成音乐的质量。
- CLaMP-DPO 方法:提出一种无需人工标注或预定义奖励的强化学习方法,通过对比学习优化生成音乐的音乐性。
- 多模态评估:利用 CLaMP 2 模型对生成的音乐进行评估,确保生成结果与真实乐谱在语义上的一致性。
- 高效数据利用:通过大规模预训练和小规模微调,有效利用有限的高质量音乐数据。
工作原理
- 预训练:
- NotaGen 在包含 160 万首 ABC 符号表示的音乐数据上进行预训练,学习音乐的基本结构和模式。
- 预训练的目标是最小化下一个符号的预测误差,从而捕捉音乐的全局结构和风格。
- 微调:
- 在预训练的基础上,NotaGen 在约 9000 首高质量古典音乐作品上进行微调。
- 每首乐曲都附带“时期-作曲家-乐器”提示,模型需要根据这些条件生成符合特定风格的音乐。
- 强化学习(CLaMP-DPO):
- 利用 CLaMP 2 模型对生成的音乐进行评估,根据与真实乐谱的语义相似性对生成结果进行选择。
- 采用直接偏好优化(DPO)算法,通过对比选择的“好”样本和“坏”样本,优化模型的生成能力,提升音乐性。
应用场景
- 音乐创作辅助:为作曲家提供灵感,生成符合特定风格和乐器要求的乐谱。
- 音乐教育:生成用于教学的示例乐谱,帮助学生学习不同风格和时期的音乐。
- 音乐娱乐:为游戏、影视等创作背景音乐,快速生成符合场景需求的音乐。
- 音乐研究:用于音乐风格分析和历史研究,生成特定时期或作曲家风格的音乐样本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











