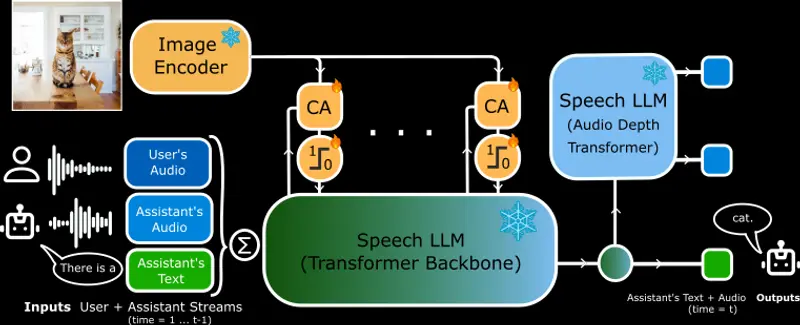
Kyutai发布首个开源实时语音模型MoshiVis,开启视觉与语音交互新时代在AI领域,将实时语音交互与视觉内容相结合一直是一个极具挑战性的课题。传统系统通常依赖于多个独立组件来实现语音活动检测、语音识别、文本对话和文本转语音合成,这种分段式的方法不仅容易引入延迟,还难以捕捉...语音模型# MoshiVis# 语音模型1年前02080