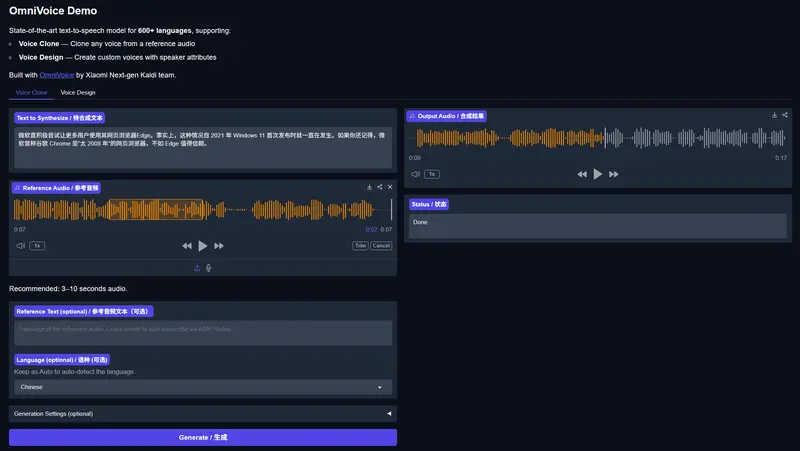
OmniVoice:小米 K2-FSA 团队开源 600+ 语言零样本 TTS,一句话复刻全球声音OmniVoice 是由 小米 K2-Fsa 团队 最新推出的文本转语音(TTS)模型。它打破了传统 TTS 的语言壁垒,支持超过 600 种语言(包括大量低资源语言和方言),并凭借创新的 扩散语言模...语音模型# OmniVoice# TTS5天前0120
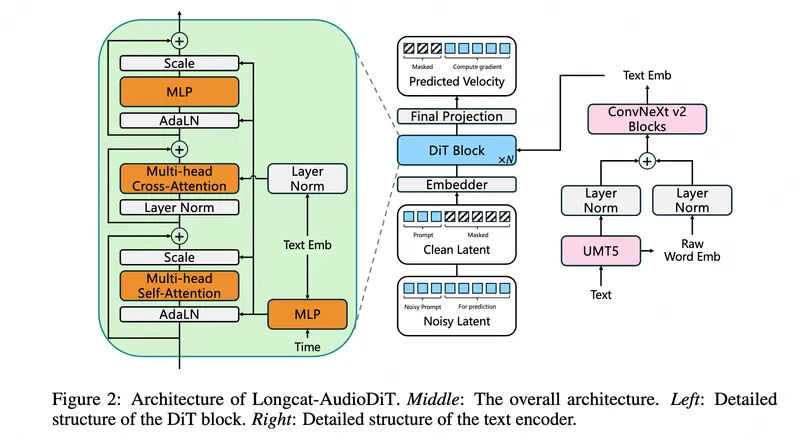
LongCat-AudioDiT:美团开源的端到端语音合成模型,直接在波形潜空间生成高保真语音美团 LongCat 团队推出了 LongCat-AudioDiT,这是一种基于扩散模型的最新文本转语音(TTS)系统。该模型的核心创新在于摒弃了传统的中间声学特征(如梅尔频谱图),直接在波形潜空间...语音模型# LongCat-AudioDiT# TTS# 美团7天前0100
Foundation-1:重新定义 AI 音乐制作,首个“结构化文本生成采样”模型在 AI 音乐生成领域,大多数模型(如 Suno, Udio)专注于生成完整的歌曲或长段落,但对于专业音乐制作人而言,他们真正需要的是高质量的、可循环的、结构精准的采样(Samples/Loops...语音模型# Foundation-1# 采样模型1周前0190
Mistral 发布 Voxtral TTS:40 亿参数开源模型,以极致低延迟和跨语言克隆挑战 ElevenLabs法国 AI 独角兽 Mistral AI 今日正式进军语音合成领域,发布了其首款开源文本转语音(TTS)模型——Voxtral TTS。这款基于 Ministral 3B 架构打造的轻量级模型,旨在以...语音模型# Mistral# Voxtral TTS2周前0160
谷歌发布 Gemini 3.1 Flash Live:迄今最自然、最敏锐的语音 AI,支持全球 200+ 语言谷歌在 AI 语音交互领域再次迈出关键一步。今日,谷歌正式推出 Gemini 3.1 Flash Live,称其为“迄今为止最高质量的音频和语音模型”。这款新模型不仅大幅降低了延迟,更在语调理解、情绪...早报语音模型# Gemini 3.1 Flash Live# 谷歌2周前01180
Cohere 开源自动语音识别(ASR)模型 Cohere Transcribe:20 亿参数跑赢巨头,消费级显卡即可部署在企业 AI 赛道深耕多年的 Cohere 今日正式进军语音领域,发布了其首款开源自动语音识别(ASR)模型——Cohere Transcribe(cohere-transcribe-03-2026...语音模型# Cohere# Cohere Transcribe# 自动语音识别模型2周前0580
谷歌发布 Lyria 3 Pro:谷歌音乐生成迈入“完整曲目”时代,最长支持 3 分钟继上个月推出 Lyria 3 后,谷歌于本周三正式发布了其最新音乐生成模型 Lyria 3 Pro。这款升级版模型不仅将生成时长从 30 秒大幅延长至 3 分钟,更在音乐结构理解、创意控制和多平台集成...早报语音模型# Lyria 3 Pro# 谷歌2周前0330
阿里通义实验室开源 Fun-CineForge:首个影视级多场景 AI 配音大模型,攻克“音画同步”与“多人对话”难题在 AI 语音合成(TTS)日益普及的今天,将其应用于专业影视制作仍面临巨大挑战:口型对不上、情感不到位、多人对话混乱、画面遮挡时声音消失…… 阿里通义实验室正式宣布开源 Fun-CineForge ...语音模型# Fun-CineForge# 通义实验室# 配音大模型3周前0230
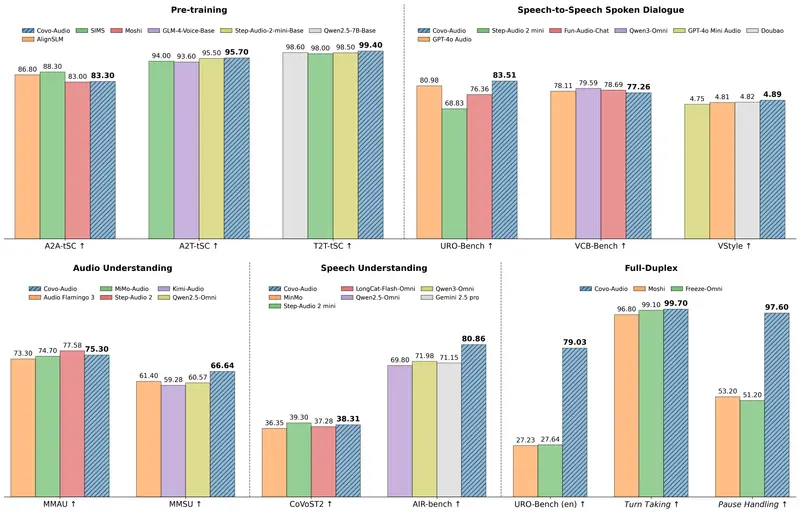
Covo-Audio:腾讯开源 7B 端到端语音大模型,重新定义“像人一样”的对话在 AI 语音交互领域,长期存在一个痛点:传统的“语音识别 (ASR) + 大语言模型 (LLM) + 语音合成 (TTS)”三段式架构,导致信息丢失、延迟累积、情感匮乏,且难以实现真正的实时打断与插...语音模型# Covo-Audio# 腾讯3周前0400
KokoClone:极速实时多语言语音克隆系统,基于 Kokoro-ONNX 驱动KokoClone 是一款构建在 Kokoro-ONNX(目前最快的开源神经语音合成引擎之一)之上的高性能语音克隆系统。它打破了传统 TTS(文本转语音)和语音转换的延迟瓶颈,实现了快速、实时兼容的多...语音模型# KokoClone# Kokoro-ONNX3周前0220
Hume AI 开源 TTS 模型 TADA:文本 - 声学一对一同步,推理速度提升 5 倍且零幻觉在基于大语言模型(LLM)的文本转语音(TTS)领域,开发者长期面临一个“不可能三角”:速度、质量与可靠性难以兼得。传统的 LLM-TTS 系统往往因为文本与音频表示的不匹配,导致推理缓慢、内存消耗巨...语音模型# Hume AI# TADA# TTS4周前0670
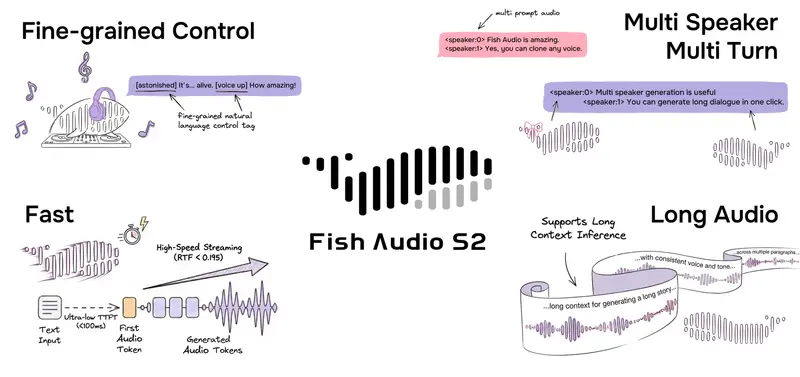
Fish Audio 开源 Fish Audio S2 Pro:支持自然语言指令的精细化 TTS 模型,单卡 H200 实时因子低至 0.195在文本转语音(TTS)领域,如何在保持高保真音质的同时,实现对韵律、情感和副语言特征(如笑声、呼吸声)的精细化控制,一直是行业难点。今日,Fish Audio 正式开源 S2 模型及其完整的生产级推理...语音模型# Fish Audio# Fish Audio S2 Pro4周前0140