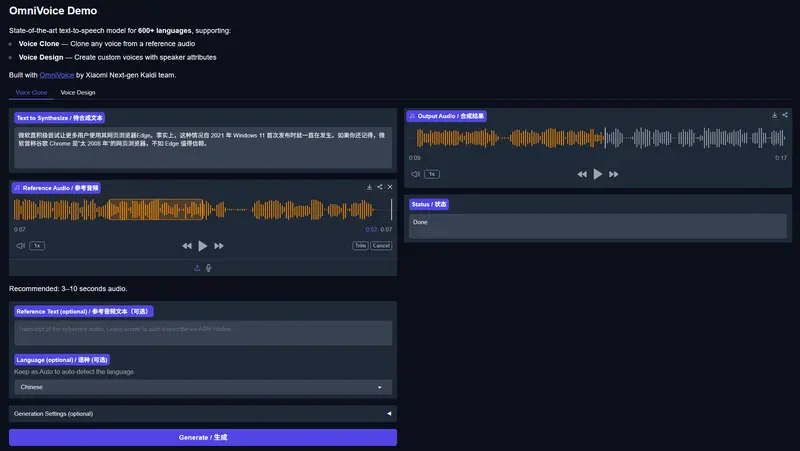
OmniVoice 是由 小米 K2-Fsa 团队 最新推出的文本转语音(TTS)模型。它打破了传统 TTS 的语言壁垒,支持超过 600 种语言(包括大量低资源语言和方言),并凭借创新的 扩散语言模型架构,实现了业界领先的零样本声音克隆能力和极致的推理速度。
- 项目主页:https://zhu-han.github.io/omnivoice
- GitHub:https://github.com/k2-fsa/OmniVoice
- 模型:https://huggingface.co/k2-fsa/OmniVoice
- Demo:https://huggingface.co/spaces/k2-fsa/OmniVoice
这不仅是一个语音合成工具,更是一个旨在“让每种语言都能被听见”的全球性语音基础设施。无论是复刻亲人声音、制作多语言有声书,还是为虚拟角色设计独特嗓音,OmniVoice 都能以惊人的自然度和效率完成任务。
核心亮点:重新定义语音合成
1. 600+ 语言覆盖,全球第一
OmniVoice 是目前支持语言最广泛的零样本 TTS 模型。
- 广泛兼容:涵盖全球主流语言、少数民族语言及方言。
- 低资源突破:即使对于训练数据极少的稀有语言,也能凭借大语言模型的泛化能力,生成清晰、自然的语音。
- 多语言混合:完美支持单句内多语言混合朗读,无缝切换,无口音干扰。
2. 极致声音克隆与降噪
- 零样本克隆:仅需 3-10 秒 的参考音频,即可精准复刻说话人的音色、语调和情感。
- 智能降噪:内置强大的音频净化能力。即使参考音频包含背景噪音、混响或录音瑕疵,OmniVoice 也能自动过滤,生成干净、专业的录音室级音质。
3. 声音设计 (Voice Design)
无需参考音频,直接通过文本指令“捏”出一个声音:
- 属性控制:指定性别、年龄、音调、口音、方言,甚至特殊状态(如耳语、激动、悲伤)。
- 创意无限:为游戏 NPC、虚拟主播或有声读物创造独一无二的专属嗓音。
4. 扩散架构 + 极速推理
- 单阶段非自回归 (NAR):摒弃了传统的“文本→语义→声学”复杂流水线,直接将文本映射到多码本声学令牌。
- 扩散语言模型:基于 Qwen3-0.6B 初始化,结合全码本随机掩码策略,既保留了 LLM 的语言理解力,又具备扩散模型的高质量生成能力。
- 性能怪兽:实时因子 (RTF) 低至 0.025,意味着生成速度比实时播放快 40 倍,轻松应对大规模批量合成任务。
技术原理:极简即最强
OmniVoice 的成功源于其大胆而简洁的架构设计:
- 数据基石:整理了 58.1 万小时 的开源多语言音频数据,覆盖 600+ 语言,并进行了严格的清洗和修复。
- 架构革新:
- 直接映射:Text → Acoustic Tokens,减少中间环节的信息损失和误差累积。
- LLM 初始化:利用预训练大语言模型(Qwen3)的强大语言能力,确保生僻字、多音字和多语言语境下的发音准确性。
- 全码本随机掩码:在训练时随机遮盖部分声学令牌,迫使模型学习全局上下文依赖,显著提升生成质量和鲁棒性。
- 多维控制:在训练过程中引入噪声数据、属性标签和音素标注,赋予模型降噪、音色设计和精准发音控制的能力。
性能表现:全面超越
在多项权威基准测试中,OmniVoice 展现了统治级的实力:
| 维度 | 表现 | 对比优势 |
|---|---|---|
| 中英效果 | SOTA (State-of-the-Art) | 相似度、自然度、清晰度均超越 ElevenLabs v2 等商业标杆 |
| 多语言覆盖 | 24 种 / 102 种语言测试 | 平均表现碾压现有开源及闭源模型,尤其在低资源语言上优势巨大 |
| 抗噪能力 | 极强 | 在嘈杂参考音频下,生成音质依然纯净,远超同类模型 |
| 推理速度 | RTF 0.025 | 比实时快 40 倍,适合高并发、实时交互场景 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











