阿里巴巴通义实验室联合香港科技大学与浙江大学的研究团队提出了一种全新的多模态视频-音频生成与编辑框架 —— ThinkSound。
- 项目主页:https://thinksound-project.github.io
- GitHub:https://github.com/liuhuadai/ThinkSound
- Demo:Hugging Face | 魔塔
该框架基于多模态大型语言模型(MLLM)的链式推理能力(Chain-of-Thought, CoT),实现了从任意输入模态(如视频、文本、音频或其组合)中生成高质量、语义一致的音频,并支持交互式的对象级编辑功能。
ThinkSound 是目前首个将 CoT 推理引入音频生成领域的统一 Any2Audio 框架,为视频配乐、影视制作、AI 创作等领域带来了全新可能性。
技术亮点:CoT 驱动的统一音频生成与编辑流程
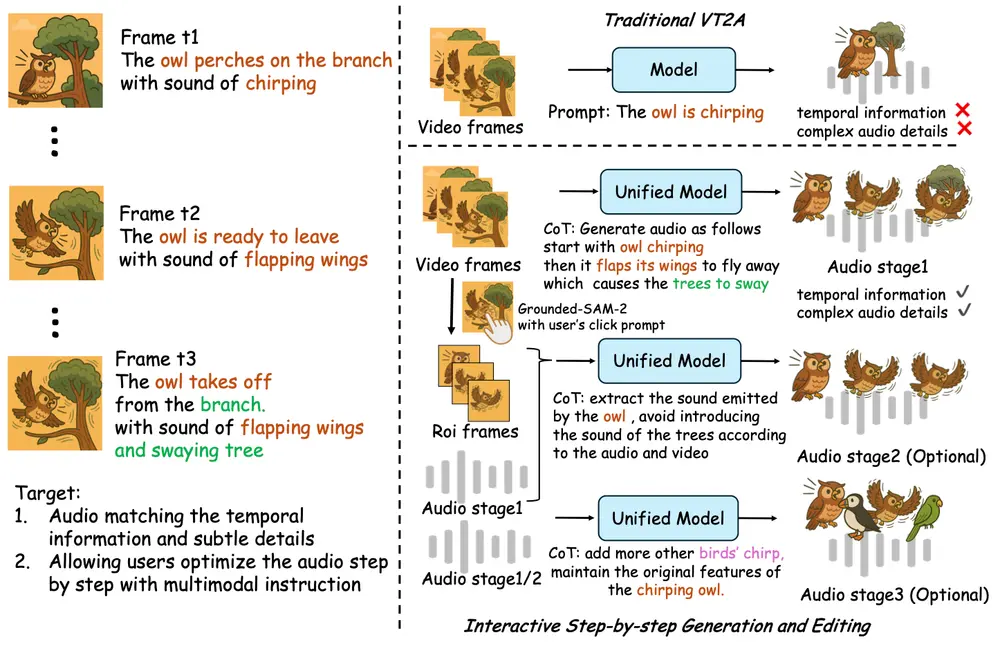
ThinkSound 的核心创新在于通过 MLLM 的链式思维推理机制,将复杂的音频生成任务分解为多个阶段,逐步生成并优化音频输出,确保最终结果在语义和时间上与视觉内容高度对齐。
主要特性包括:
- Any2Audio:支持视频、文本、音频或其组合输入生成音频;
- SOTA 视频转音频性能:在多个 V2A 基准测试中表现优异;
- CoT 驱动推理:通过可解释的推理链提升可控性与组合性;
- 交互式对象编辑:用户可通过点击视觉对象或使用自然语言指令细化特定声音;
- 统一框架设计:一套基础模型支持生成、编辑与交互式工作流。
工作原理详解
ThinkSound 将音频生成与编辑划分为三个主要阶段,每个阶段均由 MLLM 支持的 CoT 推理引导:
1. 拟音生成(Foley Generation)
- 输入:原始视频;
- 处理过程:
- 使用 VideoLLaMA2 提取视频中的语义和时序信息;
- 结合 Qwen2-Audio 生成初步音频描述;
- 利用 GPT-4.1-nano 构建详细的 Chain-of-Thought 推理链;
- 最终由统一音频基础模型合成高质量音频。
- 输出:基础声景,如脚步声、环境音等,与视频事件同步。
2. 面向对象的细化(Object-Centric Refinement)
- 输入:用户选择的视觉对象(如点击猫);
- 处理过程:
- 使用 Grounded-SAM2 进行对象检测;
- 针对选中对象生成专属音频片段;
- 将新生成的音频融合至整体声景中。
- 输出:精细化的特定对象音效,如“猫叫”、“翅膀拍打”。
3. 目标音频编辑(Target Audio Editing)
- 输入:自然语言指令(如“增加更多的鸟叫声”);
- 处理过程:
- 解析指令并匹配到对应的音频操作;
- 基于 CoT 推理链执行添加、删除或修改;
- 保证编辑后音频与原视频保持高度同步。
- 输出:根据需求调整后的定制化音频。
✅ 主要功能
| 功能 | 描述 |
|---|---|
| 基础音效生成 | 根据视频内容自动生成与之语义和时间对齐的声音场景。 |
| 交互式对象细化 | 点击视频中的特定对象,实时优化对应音效。 |
| 自然语言编辑 | 输入文本指令,实现对音频内容的定向修改。 |
| 多模态推理驱动 | 利用 CoT 推理链分解复杂任务,提升生成质量与可控性。 |
主要特点
| 特点 | 内容说明 |
|---|---|
| 链式推理(CoT) | 将音频生成任务拆解为多个步骤,逐步优化输出质量。 |
| 多模态融合 | 支持视频、文本、音频等多种输入形式,实现跨模态理解。 |
| 交互性强 | 用户可通过点击对象或输入指令,实时参与音频创作。 |
| 高质量音频合成 | 基于统一基础模型,输出清晰、逼真且同步的音频内容。 |
| 大规模数据支持 | 引入 AudioCoT 数据集,提供丰富的结构化 CoT 注释用于训练与研究。 |
性能评估结果
ThinkSound 在多项视频到音频生成与编辑任务中均取得优异成绩:
视频到音频生成
| 指标 | 表现 |
|---|---|
| Fréchet Distance (FD) | 优于现有方法 |
| Kullback-Leibler Divergence (KL) | 更低,表示分布更接近真实音频 |
| CLAP Score | 显著提升 |
| MOS-Q(主观质量) | 4.02 |
| MOS-A(与视频对齐度) | 4.18 |
对象中心音频生成
| 指标 | 表现 |
|---|---|
| FD/KL/CLAP | 均优于基线方法 |
| MOS-Q / MOS-A | 分别达到 3.89 和 3.91 |
音频编辑
| 指标 | 表现 |
|---|---|
| FD/KL/CLAP | 均优于对照方法 |
| MOS-Q / MOS-A | 分别达到 3.92 和 3.85 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











