近日,Kyutai Labs 正式开源了一款名为 Kyutai TTS 的文本转语音(TTS)模型,参数规模达到16亿,支持实时、流式处理,成为该领域的技术新标杆。这一模型不仅具备出色的语音生成能力,还首次实现了“文本流式输入”功能,为大语言模型(LLM)提供了更加自然的语音交互体验。
与此同时,Kyutai 还推出了一个配套工具 Unmute,它将 LLM 与 Kyutai 的语音模型结合,使语言模型能够“听”懂用户语音并“说”出回应,真正实现双向语音交互。
Kyutai TTS:专为实时应用打造
Kyutai TTS 最初是为开发 Moshi 项目而构建的内部工具。如今,团队决定将其以开源形式发布,供开发者自由使用。目前发布的版本为 kyutai/tts-1.6b-en_fr,主要支持英语和法语。
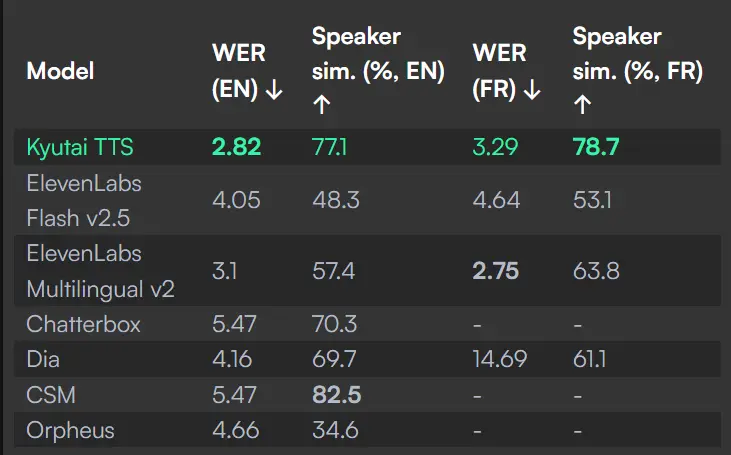
这款模型经过多项优化设计,特别适合需要低延迟、高响应性的实时应用场景,例如虚拟助手、智能客服、语音聊天机器人等。
技术亮点一览
✅ 实时语音克隆
只需提供一段10秒的参考音频,Kyutai TTS 就能模仿说话者的音色、语调和情感表达,生成高度个性化的语音。为了保护语音隐私,官方未直接开放语音嵌入模型,但提供了基于 Expresso 和 VCTK 等公开数据集的声音样本库。用户也可通过匿名捐赠语音样本参与声音库建设。
✅ 支持长文本生成
不同于传统 Transformer 类 TTS 模型通常只能生成30秒以内的音频,Kyutai TTS 可轻松应对长时间语音输出需求,适用于讲解、朗读等场景。
✅ 单词级时间戳输出
除了生成语音外,Kyutai TTS 还能同步输出每个单词的时间戳信息。这项功能对于实时字幕显示、语音打断处理等非常关键。例如,在 Unmute 中,当用户中途打断 AI 讲话时,系统能精准识别中断点,并继续完成剩余内容的表达。
首个支持文本流式输入的 TTS 模型
传统的“流式”TTS 模型通常只在音频端实现流式输出,即仍需等待完整文本输入后才能开始生成语音。
而 Kyutai TTS 是首个在文本输入端也实现流式处理的模型。这意味着,只要接收到第一个文本标记(token),就能立即开始生成对应的语音内容,从而显著降低整体延迟。
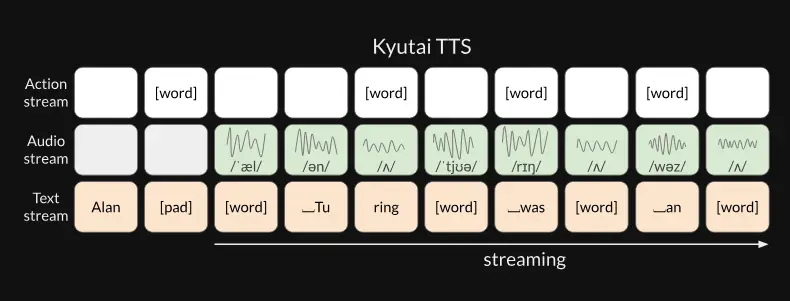
在实际部署中,Kyutai 团队通过批处理最多32个请求,在L40S GPU上观测到平均延迟约为350毫秒。而在单个请求下,从接收第一个文本标记到输出第一段音频的延迟仅为220毫秒。
背后的核心技术:延迟流建模(Delayed Streaming Modeling)
Kyutai TTS 的这些突破性能力,得益于其独特的 延迟流建模技术,最初在 Moshi 项目中首次应用。
与传统方法不同,Kyutai 不再采用“先文本后音频”的串行拼接方式,而是将文本与音频视为并行流动的信息流。通过对音频流进行轻微延迟,模型可以在仅掌握部分文本的情况下就开始生成语音。
这种设计允许系统在不知道全文的前提下持续输出语音,极大提升了实时性和灵活性。
生产就绪:高性能服务端支持
Kyutai 提供了一个基于 Rust 构建的高性能服务器,通过 WebSocket 接口提供对模型的流式访问。该服务已用于运行 Unmute 平台。
在 L40S GPU 上,服务器可支持多达16个并发连接,实时因子超过2倍,性能表现优异。
此外,Kyutai 还提供了 Dockerfile,方便开发者一键部署,无需担心环境依赖问题。
多语言扩展计划
当前 Kyutai TTS 已支持英语和法语。团队表示正在探索更多语言的支持方案。值得一提的是,Kyutai 自研的语言模型 Helium 1 已经覆盖欧盟全部24种官方语言,这为未来多语言 TTS 的扩展打下了坚实基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











