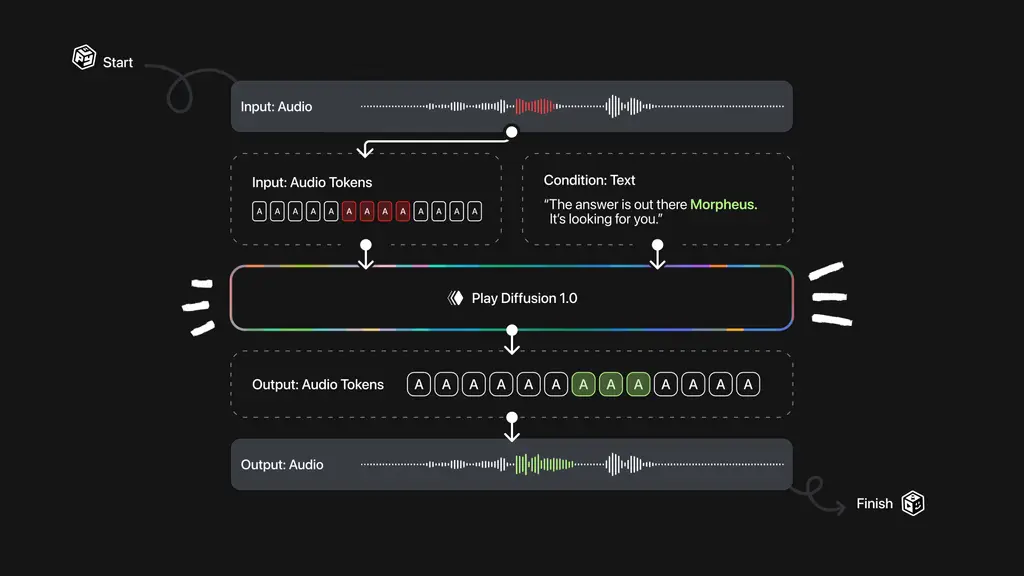
在大规模文本转语音(TTS)模型的发展中,自回归与非自回归系统各有优劣。自回归模型虽然在语音自然度方面表现优异,但其逐标记生成机制难以实现对语音持续时间的精确控制。这一缺陷在视频配音等需要严格音画同步的场景中尤为突出。
- 项目主页:https://index-tts.github.io/index-tts2.github.io
- GitHub:https://github.com/index-tts/index-tts
- 模型:https://huggingface.co/IndexTeam/IndexTTS-2
- 魔塔:https://modelscope.cn/models/IndexTeam/IndexTTS-2
- Demo:https://huggingface.co/spaces/IndexTeam/IndexTTS-2-Demo
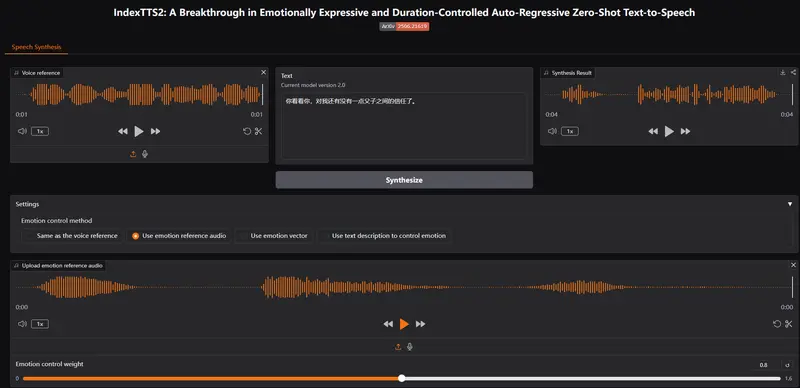
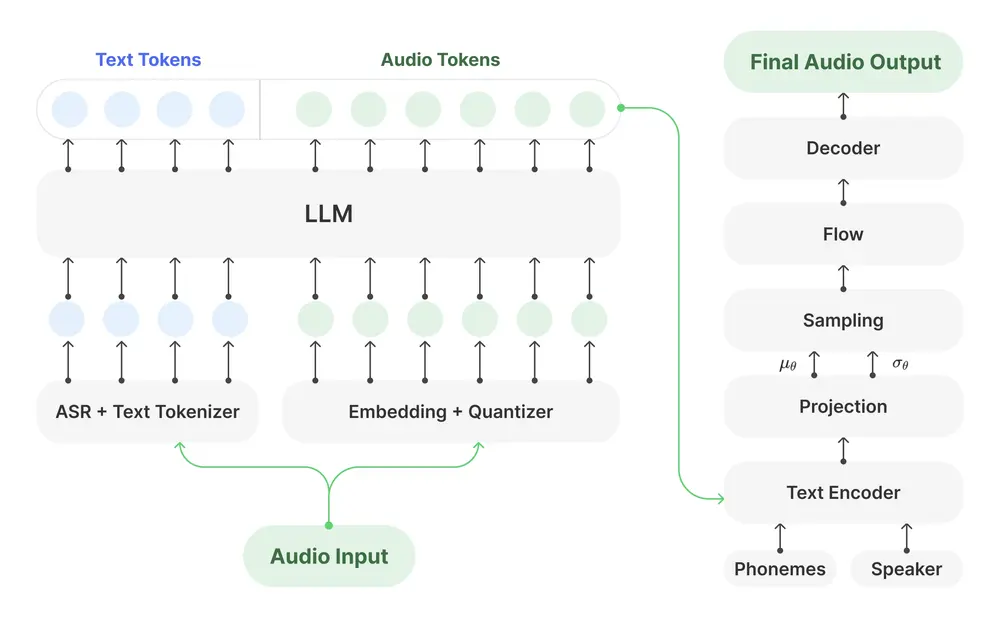
哔哩哔哩(B站)Index 团队推出的 IndexTTS2,首次在自回归 TTS 模型中实现了对语音持续时间的精细控制,并引入了情感与音色解耦机制,显著提升了语音合成的可控性与表现力。以下是对该模型核心能力的详细解析。
语音持续时间控制:首次在自回归 TTS 中实现
IndexTTS2 的最大创新之一,是提出了一种新颖且通用的语音持续时间控制方法,适用于自回归模型。该方法支持两种生成模式:
- 显式控制模式:用户可指定生成语音的标记数量,从而精确控制语音的总时长。
- 自适应生成模式:模型以传统自回归方式生成语音,同时忠实还原输入提示音频中的韵律特征,无需手动设定标记数量。
这种设计使得 IndexTTS2 在需要音画同步的场景(如视频配音、AI 动画配音)中具有显著优势,填补了自回归模型在持续时间控制方面的空白。
情感与音色解耦:支持独立控制与混合表达
IndexTTS2 实现了说话者音色与情感表达的有效解耦,使得用户可以分别控制这两个维度,从而实现更丰富的语音生成能力。
2.1 使用相同提示音频
在该设置下,模型使用同一段音频作为音色和情感的参考来源。这种方式确保生成语音的变化仅来源于目标情感或音色的变化,避免了其他因素的干扰。
2.2 使用不同提示音频
模型支持将不同音频分别作为音色和情感的参考源。例如,使用 A 的语音作为音色参考,使用 B 的语音作为情感参考。这种设计验证了模型在分离和融合不同语音特征方面的能力,增强了语音表达的灵活性。
2.3 使用文本描述作为情感提示
为了降低情感控制的门槛,IndexTTS2 引入了一种基于自然语言的软指令机制。用户可以通过文本描述(如“愤怒”、“悲伤”、“兴奋”)来引导情感表达,而无需提供情感音频参考。
该机制基于对 Qwen3 的微调实现,使得模型能够理解并响应语义层面的情感指令,提升了交互友好性与实用性。
增强情感表达的语音稳定性
为了在强烈情感(如愤怒、激动)表达时保持语音的清晰度与稳定性,IndexTTS2 引入了 GPT 潜在表示机制。通过引入更强的上下文建模能力,模型在生成高情感强度语音时,依然能够保持良好的语音质量和可理解性。
多语言与多数据集验证
在多个数据集上的实验结果表明,IndexTTS2 在以下关键指标上优于当前最先进的零样本 TTS 模型:
- 词错误率(WER):更低,表示语音识别准确率更高
- 说话者相似度(Speaker Similarity):更高,表示音色还原更真实
- 情感保真度(Emotion Fidelity):更强,表示情感表达更自然
这些结果验证了 IndexTTS2 在语音自然度、可控性与表达力方面的全面优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











