小米近日正式推出 MiMo-Audio ——一个统一的生成式音频-语言模型,支持跨模态语音理解与生成任务。该模型通过超过一亿小时的大规模预训练,实现了强大的少样本学习能力,能够在无需微调的情况下,仅凭少量样本或自然语言指令完成复杂音频操作。
- 项目主页:https://xiaomimimo.github.io/MiMo-Audio-Demo
- GitHub:https://github.com/XiaomiMiMo/MiMo-Audio
- 模型:https://huggingface.co/collections/XiaomiMiMo/mimo-audio-68cc7202692c27dae881cce0
- Demo:https://huggingface.co/spaces/XiaomiMiMo/mimo_audio_chat
更重要的是,MiMo-Audio 全系列核心组件已完全开源:包括分词器、7B 参数指令模型、评估基准和训练代码,标志着国产公司在通用音频智能领域的又一重要进展。
什么是 MiMo-Audio?
MiMo-Audio 是一个将文本与音频统一建模的序列生成模型。它不仅能“听懂”语音内容,还能根据指令生成高质量语音输出,甚至执行跨语种翻译、风格迁移、语音续写等高级任务。
它的核心突破在于:
在海量数据上预训练后,模型展现出真正的涌现能力——在未见过的任务上,仅靠上下文示例即可快速适应。
这使得 MiMo-Audio 不再依赖传统模式下的任务特定微调,而是像大语言模型处理文本一样,以“上下文内学习”(In-Context Learning, ICL)的方式完成语音任务。
核心能力一览
✅ 语音理解(Speech Understanding)
- 能对复杂音频进行描述、推理与摘要
- 支持长音频理解(如讲座、会议记录)
- 在多轮对话中保持上下文一致性
✅ 语音生成(Speech Generation)
- 高保真语音合成,保留原始说话人声学特征
- 支持语音风格转换(如新闻播报 → 播客语气)
- 实现跨语言语音翻译(Speech-to-Speech Translation)
✅ 指令跟随(Instruction Following)
- 接受自然语言指令控制生成过程
示例:“把这段话用更欢快的语气读出来” - 支持多步复合指令
示例:“先总结内容,再用四川话朗读一遍”
✅ 少样本语音编辑(Few-shot Editing)
- 提供几个参考片段,即可完成声音转换、语义替换等操作
- 无需重新训练,适用于个性化定制场景
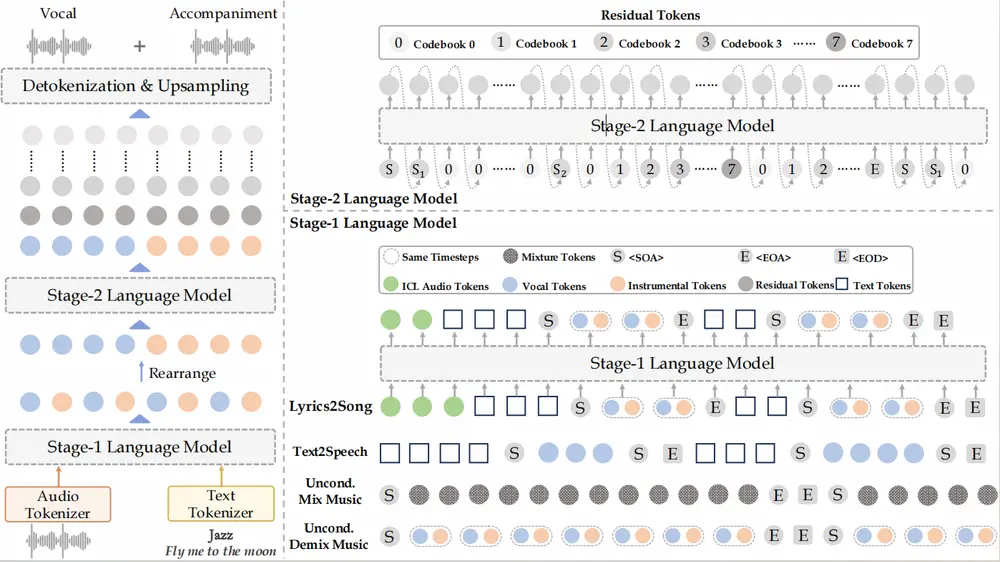
技术架构解析
1. 音频分词器:MiMo-Audio-Tokenizer
音频不能像文本那样直接切分为 token。为此,团队自研了 MiMo-Audio-Tokenizer ——一个 1.2B 参数的神经音频编码器。
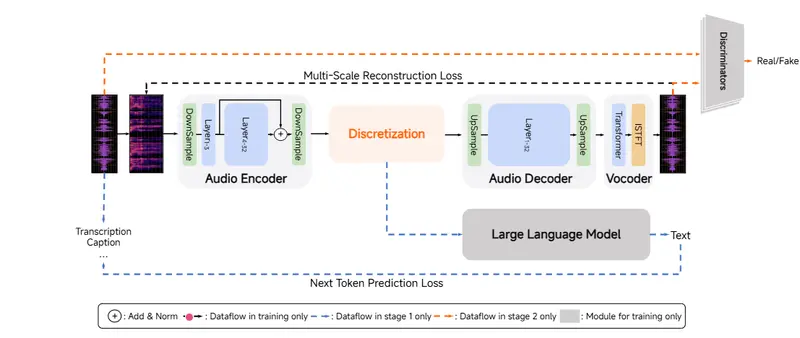
关键设计:
- 基于 Transformer 架构,包含编码器、离散化层与解码器
- 使用 8 层残差矢量量化(RVQ),每秒生成 200 个离散标记
- 工作帧率为 25Hz,兼顾语义表达与重建质量
- 在 1000 万小时语料上从头训练,确保标记既可压缩又利于语言建模
该分词器在重构保真度和下游任务适配性之间取得了良好平衡,是实现端到端音频语言建模的基础。
2. 统一建模范式:补丁化建模架构
由于音频标记率远高于文本(200 tokens/s vs ~10 words/s),直接输入会导致序列过长、计算效率低下。
为此,MiMo-Audio 提出一种新型架构,融合三个核心模块:
| 模块 | 功能 |
|---|---|
| 补丁编码器(Patch Encoder) | 将每 4 个连续 RVQ 标记聚合成一个“补丁”,将序列下采样至 6.25Hz,供 LLM 处理 |
| 大语言模型主干(LLM Backbone) | 自回归预测补丁序列,支持文本与音频混合输入 |
| 补丁解码器(Patch Decoder) | 将 LLM 输出的补丁逐步展开,恢复为完整的 25Hz RVQ 序列 |
这一设计显著降低了建模复杂度,同时保留了细粒度声学信息。
3. 训练流程:两阶段推进
第一阶段:大规模预训练
- 数据规模:>1亿小时 多源语音数据(含对话、广播、有声书、直播等)
- 目标:让模型掌握通用语音规律与跨模态关联
- 关键能力获得:
- 语音延续(给定开头,自动续说)
- 上下文内学习(ICL)能力初现
第二阶段:指令微调 + 思考机制引入
- 构建多样化指令语料库,覆盖理解、生成、编辑任务
- 引入“思考机制”(reasoning process),提升复杂任务中的推理能力
- 显著增强在口语对话、逻辑判断、多跳推理等任务上的表现
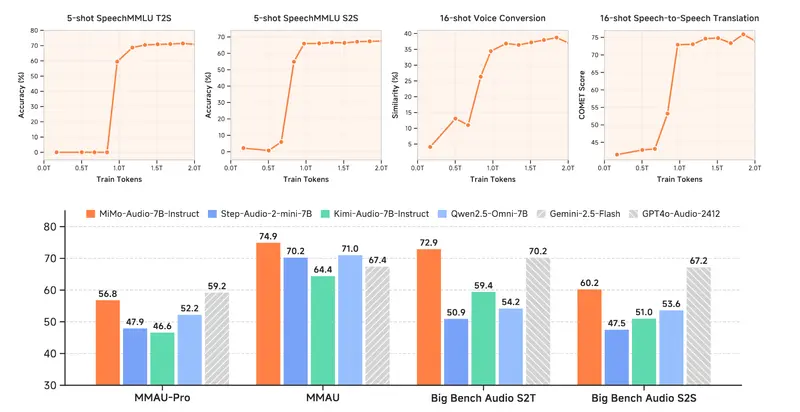
性能表现:开源 SOTA,逼近闭源模型
在多个权威音频基准测试中,MiMo-Audio-7B-Instruct 表现出色:
| 基准类别 | 成绩 |
|---|---|
| 音频理解 MMSU / MMAU / MMAR / MMAU-Pro | 开源模型中排名第一,部分指标超越 Gemini 1.5 Flash |
| 口语对话推理 Big-Bench-Audio-S2T | 超越 GPT-4o-Audio 的公开报告结果 |
| 指令 TTS 质量评估 | 生成自然度、情感匹配度达到行业领先水平 |
特别是在“少样本语音到语音转换”任务中,模型仅需 1–3 个示例即可完成风格迁移或语种转换,展现出极强的泛化能力。
实际应用场景展示
🎙️ 语音风格迁移
输入一段普通话新闻播报,指令:“改为轻松幽默的脱口秀风格”。
输出:同一内容,但语调活泼、节奏明快,适合娱乐类节目。
适用:内容再创作、个性化播客生成。
🔤 语音翻译(S2S Translation)
输入英文访谈录音,指令:“翻译成中文,并保持原说话人音色”。
输出:流畅中文语音,语速、停顿、情感贴近原声。
相比传统“ASR → MT → TTS”三段式方案,MiMo-Audio 实现端到端直译,减少信息损失。
🧩 上下文内学习(ICL)示例
提供以下上下文示例:
[语音A] → [语音B] # 方言转普通话
[语音C] → [语音D] # 正式语气转童趣讲述
然后输入新语音并指令:“按上述模式转换为温柔妈妈讲故事风格”。
模型无需额外训练,即可完成迁移。
📚 长音频理解
面对长达 30 分钟的教师讲课录音,MiMo-Audio 可:
- 自动生成章节摘要
- 回答具体问题(如“老师提到哪三种解题方法?”)
- 推理隐含知识点之间的联系
这对教育、会议记录等场景具有实用价值。
开源详情与生态支持
小米此次开放了完整技术栈:
| 组件 | 是否开源 |
|---|---|
| MiMo-Audio-7B-Instruct 模型权重 | ✅ |
| MiMo-Audio-Tokenizer 分词器 | ✅ |
| 指令微调数据格式说明 | ✅ |
| 评估脚本与基准工具 | ✅ |
| 补丁化架构实现代码 | ✅ |
未来还将发布更大规模版本及轻量化部署方案。
局限与挑战
尽管性能优异,当前版本仍存在一些限制:
- 中文方言覆盖有限,部分口音识别不稳定
- 多人对话分离能力有待加强
- 极低资源语言(如少数民族语言)支持较弱
- 实时推理延迟较高,尚未适配移动端低功耗场景
团队表示将持续迭代,重点优化推理效率与边缘部署能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











