阿里通义实验室今日推出 Qwen3-LiveTranslate-Flash——一款基于 Qwen3-Omni 基座模型打造的多语言实时音视频同声传译大模型。
- Demo:https://huggingface.co/spaces/Qwen/Qwen3-Livetranslate-Demo
- API:https://bailian.console.aliyun.com/
- 官方博文:https://qwen.ai/blog
它不仅是传统语音翻译的升级,更是首次实现“视觉增强 + 低延迟 + 拟人语音”三位一体的全模态同传系统,标志着机器翻译从“听音识义”迈向“观言察色”的新阶段。

该模型支持 18 种主要语言 的离线与实时翻译,现已开放试用,适用于国际会议、跨语言直播、远程协作等高要求场景。
核心能力一览
| 特性 | 表现 |
|---|---|
| 支持语言 | 中、英、法、德、俄、日、韩、西、阿、印地等主流语种 |
| 方言覆盖 | 普通话、粤语、吴语、四川话、北京话、天津话 |
| 翻译延迟 | 最低仅 3 秒,接近人类同传水平 |
| 翻译质量 | 实时模式下保留离线翻译 94% 以上准确率 |
| 输出语音 | 自然拟人音色,语气随内容动态调节 |
| 运行模式 | 支持纯音频输入与音视频融合输入 |
为什么需要“看得懂”的翻译模型?
传统语音翻译依赖音频信号,但在真实环境中面临诸多挑战:
- 背景噪音干扰(如会议现场、街头采访)
- 同音词、一词多义导致歧义(如“苹果”指水果还是公司?)
- 专有名词发音模糊或口音重
- 缺乏上下文导致语序错乱
为此,Qwen3-LiveTranslate-Flash 首次引入 视觉上下文增强技术,通过分析视频中的以下信息,显著提升翻译准确性:
✅ 口型变化(辅助判断发音)
✅ 手势与表情(理解情绪和强调)
✅ 场景文字(识别 PPT、标识牌内容)
✅ 实体对象(结合画面判断“iPhone”出现在演讲中 vs. 出现在广告里)
例如:当音频中出现模糊的 “I bought an apple”,若画面显示发布会舞台和手机产品,模型将更倾向于翻译为“我买了一台苹果手机”。
这种“视听融合”的能力,在嘈杂环境和复杂语境下优势尤为明显。
技术突破:三大关键创新
1. 轻量混合专家架构 + 动态采样,实现 3 秒极低延迟
采用轻量化 MoE(Mixture of Experts)结构,结合动态推理路径选择策略,在保证精度的同时大幅压缩计算开销。
相比传统端到端模型,响应速度提升 40% 以上,实测最低延迟可达 3 秒,满足高质量同传对时效性的严苛要求。
2. 语义单元预测技术,缓解跨语言调序问题
不同语言语法结构差异大,直译常导致语序混乱。Qwen3-LiveTranslate-Flash 引入 语义单元提前预测机制,在解码前预判目标语言的句式结构,有效减少后置调整,提升流畅度。
实验表明,该技术使中文→英文等远距语言对的翻译连贯性提升超 35%。
3. 海量语音训练,生成自然拟人化输出
基于百万小时真实音视频数据训练,模型能根据原始语音的情感、节奏和语境,自适应调整语调、停顿与重音,生成更具表现力的口语化译文。
不再是机械朗读,而是接近真人主播的表达质感。
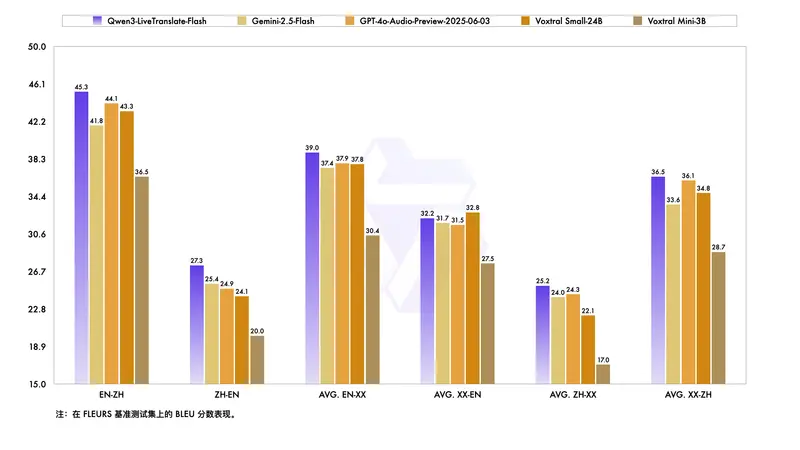
性能表现:全面超越主流闭源模型
在多个公开测试集上的对比显示,Qwen3-LiveTranslate-Flash 在中英及其他多语言方向均优于当前主流模型:
| 模型 | BLEU 分数(中→英) | 延迟(平均) | 视觉增强支持 |
|---|---|---|---|
| Qwen3-LiveTranslate-Flash | ✅ 32.6 | 3.0s | ✔️ 是 |
| Gemini 2.5 Flash | 30.1 | 4.8s | ❌ 否 |
| GPT-4o Audio Preview | 31.3 | 5.2s | ❌ 否 |
| Voxtral Small-24B | 29.7 | 4.5s | ❌ 否 |
在复杂声学环境(背景音乐、多人交叉说话)下,其鲁棒性优势更加突出,错误率降低达 28%。
应用场景
- 🎤 国际会议实时字幕与语音播报
- 📺 跨语言直播自动翻译(电商、教育、娱乐)
- 💼 多语言远程面试与商务谈判
- 🏫 多语种教学辅助系统
- 🚑 跨境医疗问诊与应急沟通
尤其适用于对准确性、延迟、自然度有综合要求的专业场景。
开放与可用性
- ✅ 支持音视频流输入(RTMP、WebRTC、本地文件)
- ✅ 提供 API 接口,便于集成至会议平台、直播系统
- ✅ 可部署于云端或边缘设备,支持离线运行
- 🌐 已开放申请体验,开发者可通过 ModelScope 或 Qwen 官网获取接入文档
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











