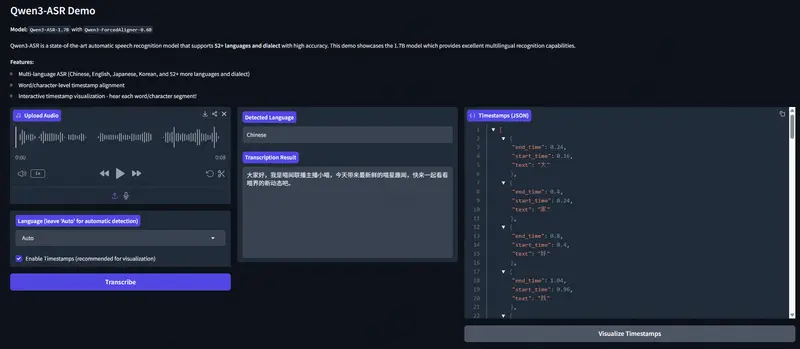
Qwen(通义千问)团队正式开源全新一代语音技术方案——Qwen3-ASR系列语音识别模型与Qwen3-ForcedAligner强制对齐模型。该系列包含Qwen3-ASR-1.7B、Qwen3-ASR-0.6B两款语音识别模型,以及Qwen3-ForcedAligner-0.6B强制对齐模型,不仅支持52种语种与方言的识别,更在精度、效率、场景适配性上实现突破,1.7B模型多项场景达SOTA水平,0.6B模型兼顾性能与高吞吐,强制对齐模型精度超越传统方案。此次开源同步释放模型结构、权重及完整推理框架,旨在推动语音识别与理解领域的研究与产业落地。
- 官方介绍:https://qwen.ai/blog?id=qwen3asr
- GitHub:https://github.com/QwenLM/Qwen3-ASR
- 模型:https://modelscope.cn/collections/Qwen/Qwen3-ASR
- Demo:https://modelscope.cn/studios/Qwen/Qwen3-ASR
开源模型矩阵:覆盖识别与对齐核心需求
Qwen3-ASR系列构建了“高精度+高效率+精准对齐”的完整模型矩阵,三款模型各有侧重,可适配不同场景的技术需求:
| 模型名称 | 核心定位 | 语种支持 | 方言支持 | 推理模式 | 音频种类支持 |
|---|---|---|---|---|---|
| Qwen3-ASR-1.7B | 高精度旗舰款 | 52种(含中文、英语、粤语、阿拉伯语等30种主流语种,及多类小语种) | 22种中文方言/口音(安徽、东北、福建、四川、粤语<香港/广东口音>、吴语、闽南语等) | 离线/流式一体化 | 普通语音、歌唱、带背景音乐的歌声 |
| Qwen3-ASR-0.6B | 高效均衡款 | 同1.7B模型 | 同1.7B模型 | 离线/流式一体化 | 普通语音、歌唱、带背景音乐的歌声 |
| Qwen3-ForcedAligner-0.6B | 精准强制对齐 | 11种主流语种(中文、英语、粤语、法语、德语等) | 无 | 非自回归(NAR) | 普通语音 |
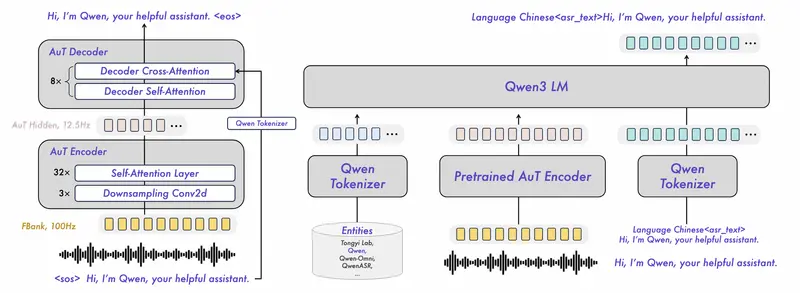
三款模型均基于创新技术架构打造:语音识别模型依托自研AuT语音编码器与Qwen3-Omni基座模型的多模态能力,实现声学特征与语言理解的深度融合;强制对齐模型则采用NAR LLM推理架构,打破传统端到端方案的局限,兼顾精度与效率。
核心特性:全场景适配、高精度与极致效率并存
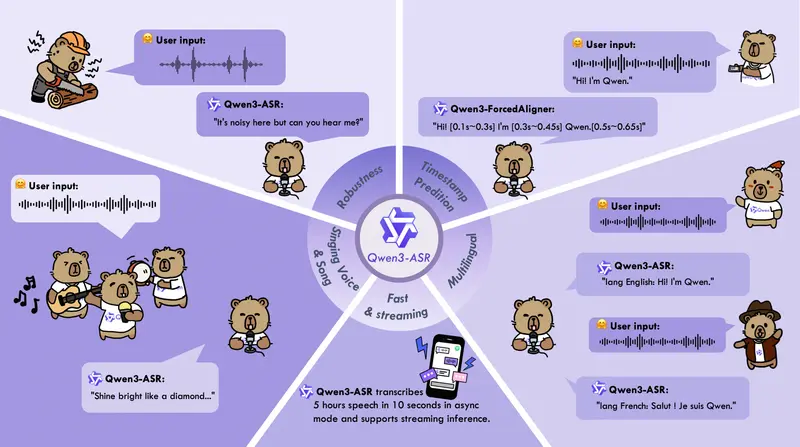
1. All-in-one全场景覆盖,无需多模型切换
Qwen3-ASR-1.7B与0.6B模型均实现“一模型多能力”,无需额外部署多个模型即可应对复杂需求:
- 语种层面:支持30种语种的“语种识别+语音识别”双功能,无需提前指定输入语种;
- 口音层面:覆盖22种中文方言/口音,及多个国家和地区的英文口音,适配地域差异明显的场景;
- 音频类型层面:不仅支持普通语音,还能精准识别歌唱、带背景音乐的歌声,填补传统ASR在娱乐、创作场景的空白;
- 长度支持:最长可一次性处理20分钟音频,满足长语音转写(如会议记录、课程录音)需求。
2. 精度与效率双突破,覆盖不同性能需求
Qwen3-ASR系列针对“高精度”与“高效率”两大核心诉求,设计两款差异化模型,兼顾专业场景与高并发场景:
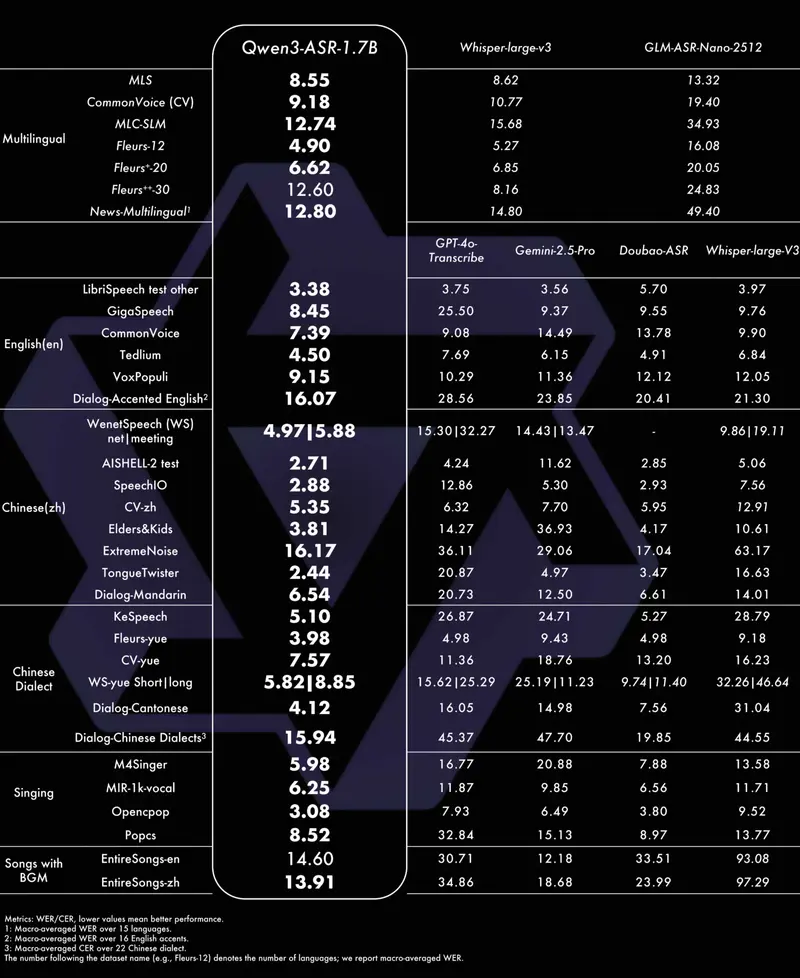
- 高精度旗舰(1.7B模型):在中文、英文、方言、歌唱识别等多个场景达到开源SOTA水平,甚至超越部分商用API。具体表现为:
- 英文识别:不仅在公开基准夺冠,在覆盖16个国家口音的内部测试集中,全面优于GPT-4o Transcribe、Gemini系列、Doubao ASR及Whisper-large-v3;
- 多语种识别:20个主流语种的平均字错误率(WER)低于现有开源模型;
- 中文与方言:普通话、粤语及22种方言识别精度领先,方言识别错误率较Doubao-ASR平均降低20%(15.94 vs 19.85);
- 复杂场景:面对老人/儿童语音、极低信噪比(强噪声)、鬼畜重复等极端场景,仍能稳定输出,保持低错误率;
- 歌唱识别:支持带BGM的中英文歌曲转写,中文WER低至13.91%,英文WER低至14.60%。
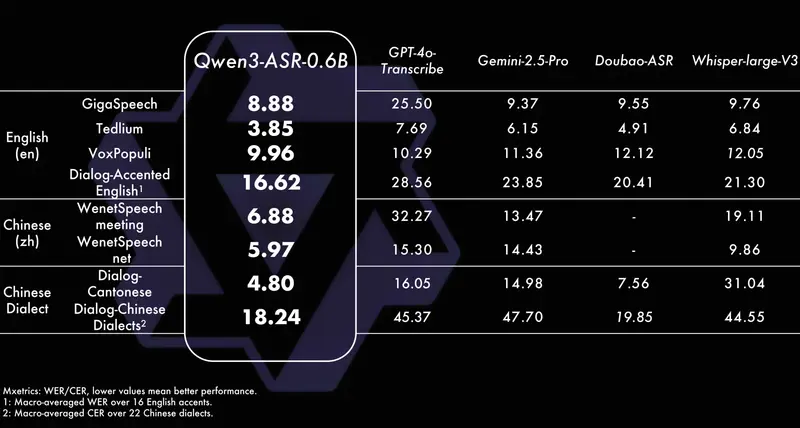
- 高效均衡款(0.6B模型):在保证识别精度稳健的前提下,重点优化推理效率,适配高并发场景:
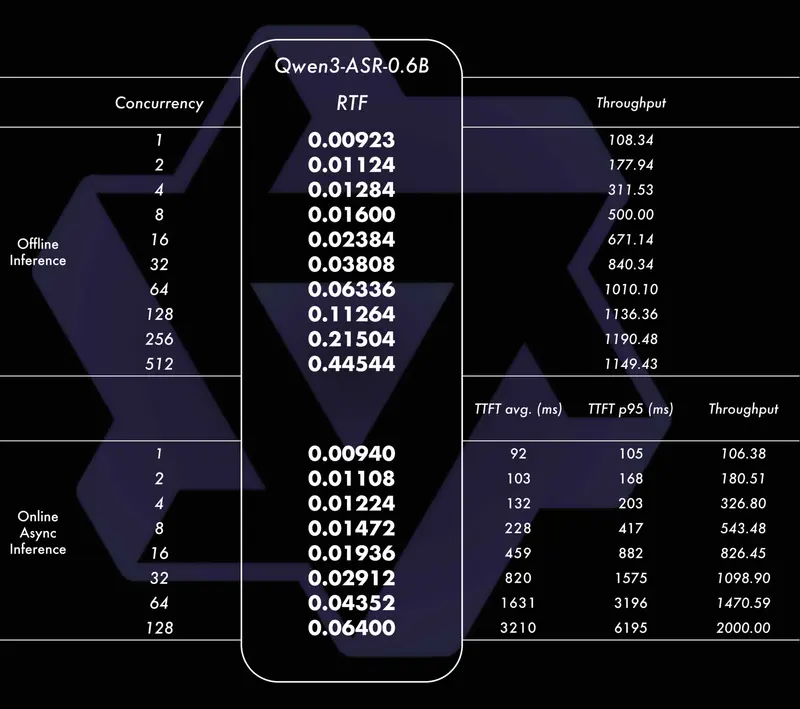
- 单并发推理:实现100倍加速比,大幅缩短单条音频处理时间;
- 高并发推理:128并发异步服务场景下,吞吐率达2000倍,仅需10秒钟即可处理超过5小时的音频,适合大规模语音转写需求(如客服录音、音频库整理)。
3. 独创强制对齐模型,精度与效率超越传统方案
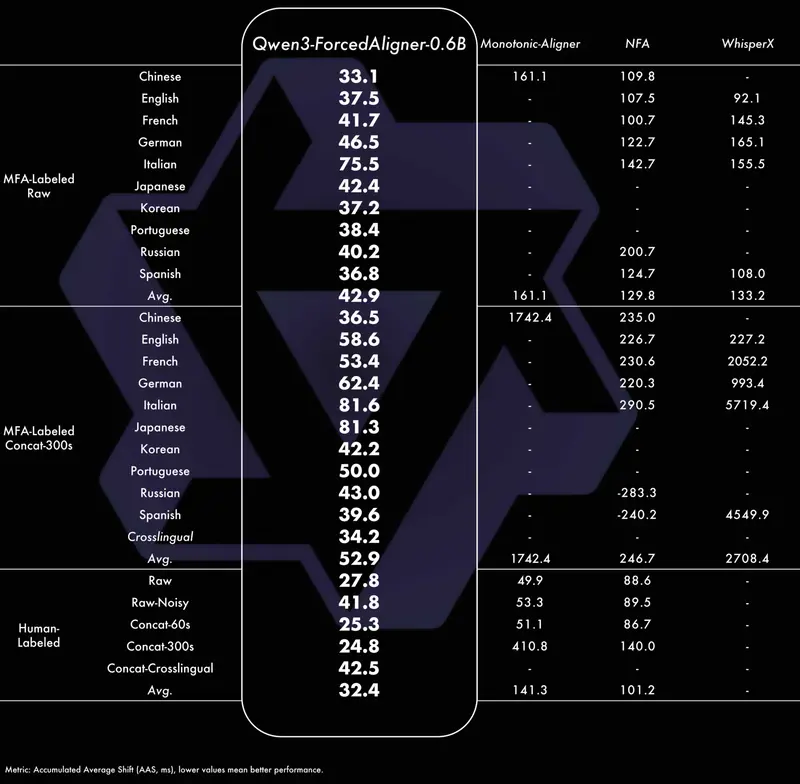
Qwen3-ForcedAligner-0.6B是基于NAR LLM推理架构的创新型时间戳预测模型,核心解决“语音与文本精准匹配”的需求(如字幕生成、语音片段定位):
- 核心优势:支持11种语种、5分钟内语音的任意单元(字、词、句)时间戳预测,精度超越WhisperX、NeMo-ForcedAligner(NFA)等主流工具;
- 效率表现:单并发推理实时因子(RTF)低至0.0089,意味着处理1小时音频仅需约32秒,远快于传统方案;
- 灵活适配:可针对音频任意位置进行精准对齐,无需完整遍历音频,适配字幕编辑、语音检索等精细化场景。
4. 全栈工具链开源,降低落地门槛
此次开源不仅释放模型权重,还配套推出全面易用的推理与微调工具链,支持开发者快速部署与二次开发:
- 推理能力:支持基于vLLM的批量推理、异步服务部署、流式推理(适合实时场景如直播转写)、时间戳预测等核心功能;
- 适配性强:兼容主流开发环境,无需复杂配置即可完成部署;
- 支持微调:提供完整的微调方案,开发者可基于自有数据集优化模型,适配特定行业(如医疗、法律)的专业术语识别。
模型适用场景与核心价值
Qwen3-ASR系列模型凭借全场景适配、高精度、高效率的特性,可广泛应用于多个领域:
- 企业级场景:客服录音转写、会议实时字幕、多语种会议纪要生成、企业音频知识库检索;
- 内容创作场景:短视频字幕自动生成、歌曲歌词转写、多语种内容本地化(字幕对齐);
- 民生服务场景:方言语音助手、无障碍音频转写(如老人/儿童语音识别)、公共服务语音导航;
- 科研与开发场景:语音识别算法优化、多语种技术研究、强制对齐技术落地验证。
其核心价值在于:一方面,1.7B模型的高精度的能力为专业场景提供开源替代方案,降低企业对商用API的依赖;另一方面,0.6B模型的极致效率与强制对齐模型的精准性,为高并发、精细化场景提供低成本解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











