通义实验室旗下语音团队 通义百聆(Tongyi Bailin)正式推出 Fun-Audio-Chat —— 一款专为自然、低延迟语音交互设计的端到端大型音频语言模型(Audio Language Model, ALM)。
- 项目主页:https://funaudiollm.github.io/funaudiochat
- GitHub:https://github.com/FunAudioLLM/Fun-Audio-Chat
- 模型:https://huggingface.co/FunAudioLLM/Fun-Audio-Chat-8B
- 魔塔:https://modelscope.cn/models/FunAudioLLM/Fun-Audio-Chat-8B
与传统“语音识别 + 文本大模型 + 语音合成”多模块拼接方案不同,Fun-Audio-Chat 采用纯端到端 Speech-to-Speech(S2S)架构,直接从语音输入生成语音输出,显著降低系统延迟,提升交互流畅度,同时支持情感共鸣、指令执行与高情商对话等复杂能力。
核心定位:不只是聊天,更是高情商伙伴 + 效率助手
Fun-Audio-Chat 的设计目标明确分为两类角色:
- 高情商语音伙伴:能识别用户情绪,主动安慰、共情,适用于陪伴、心理支持等场景
- 高效语音助手:听得懂复杂指令,可直接调用函数完成任务(如“帮我订明天早上8点的会议室”)
这种双重能力使其区别于仅聚焦语音转写的传统语音模型。
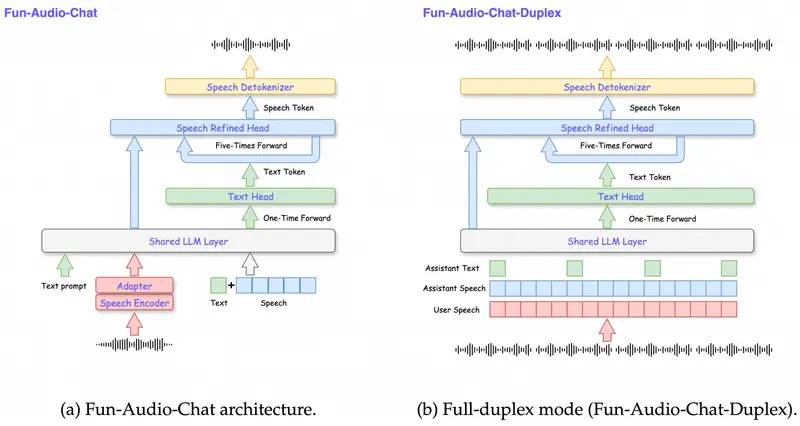
技术亮点
1. 双分辨率语音表征架构
Fun-Audio-Chat 引入创新的双分辨率语音编码机制:
- 5Hz 共享骨干网络:用于提取全局语义与上下文(远低于行业常见的 12.5Hz 或 25Hz)
- 25Hz 精细化头部:仅在输出阶段启用,用于保留语音韵律、情感与音质细节
该设计在保持高语音质量的同时,将 GPU 计算开销降低近 50%,显著提升训练与推理效率。
2. Core-Cocktail 训练策略
为避免端到端模型在语音优化过程中“遗忘”文本理解能力,团队采用 Core-Cocktail 训练策略:
- 混合语音-文本多模态数据
- 保留原始 LLM 的核心推理能力
- 确保模型在语音交互中仍具备强大的逻辑、知识与指令遵循能力
3. 语音函数调用(Voice Function Calling)
Fun-Audio-Chat 原生支持语音触发的函数调用。用户无需切换界面,仅通过语音即可完成:
- 日程管理
- 设备控制
- 信息查询
- 自动化任务执行
系统能准确解析意图、提取参数,并安全调用后端服务。
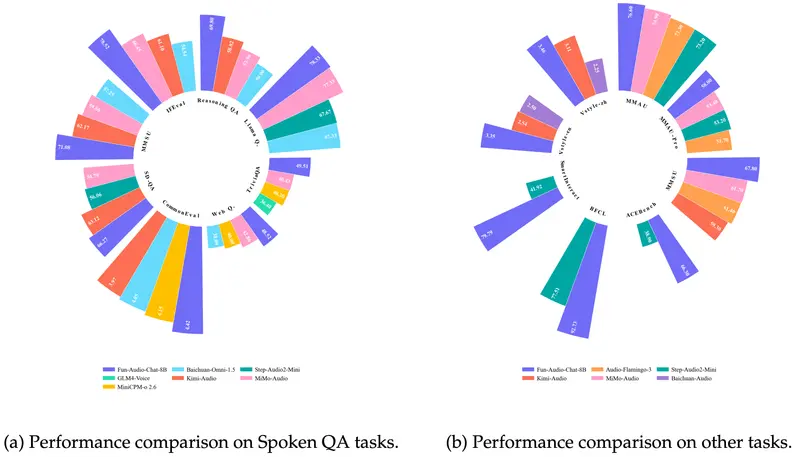
权威评测表现
在多项主流语音与多模态评测中,Fun-Audio-Chat(8B 参数规模)均取得同尺寸模型中的领先成绩,包括:
- OpenAudioBench
- VoiceBench
- UltraEval-Audio
- MMAU / MMAU-Pro
- MMSU
- Speech-ACEBench
- Speech-BFCL
- Speech-SmartInteract
- VStyle
这些基准覆盖了语音理解、指令遵循、情感表达、音频问答、风格控制等多个维度,验证了其能力的全面性。
能力覆盖全景
Fun-Audio-Chat 支持以下核心语音交互能力:
| 能力类别 | 典型应用 |
|---|---|
| 语音问答 | 回答基于音频内容或知识库的问题 |
| 音频理解 | 理解背景音、多说话人、非语言声(如咳嗽、敲击) |
| 语音指令遵循 | 执行“播放音乐”“调高音量”“发短信给张三”等命令 |
| 语音函数调用 | 连接外部 API,完成真实世界任务 |
| 语音情感共鸣 | 识别悲伤、兴奋、焦虑等情绪,并以匹配语调回应 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











