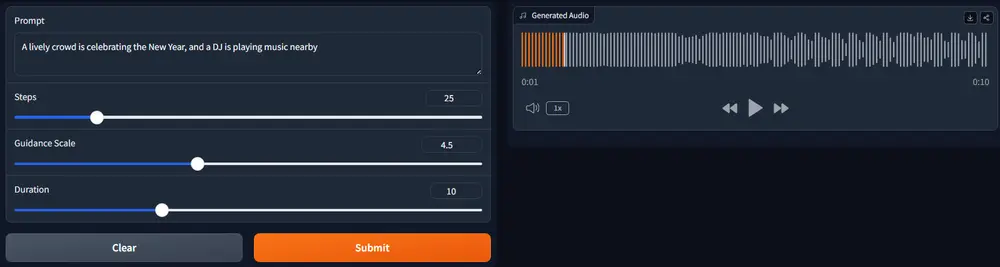
随着人工智能技术的发展,文本到音频(TTA)生成模型正在逐渐改变我们与数字内容互动的方式。然而,创建高质量且自然的音频输出仍然是一个复杂的技术挑战,尤其是在对齐模型以产生符合人类期望的音频方面。新加坡科技设计大学DeCLaRe实验室和英伟达的研究人员联合推出了TangoFlux,这是一个拥有5.15亿参数的高效TTA(文本到音频)生成模型,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频。这意味着,如果你提供一段描述特定声音场景的文本,如“森林中鸟儿的鸣叫声”,TANGOFLUX能够生成与这段描述相匹配的音频。
- 项目主页:https://tangoflux.github.io
- GitHub:https://github.com/declare-lab/TangoFlux
- 数据:https://huggingface.co/datasets/declare-lab/CRPO
- 模型:https://huggingface.co/declare-lab/TangoFlux
- Demo:https://huggingface.co/spaces/declare-lab/TangoFlux
- ComfyUI插件:https://github.com/LucipherDev/ComfyUI-TangoFlux
关键挑战与解决方案
对齐TTA模型的困难
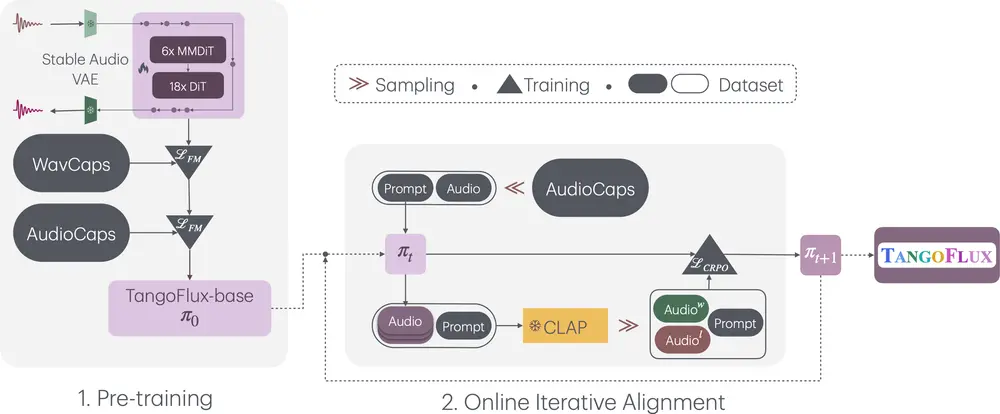
对齐TTA模型的一个关键挑战在于创建偏好对的难度。与大语言模型(LLMs)不同,TTA缺乏可验证的奖励机制或黄金标准答案,这使得优化模型变得更加困难。为了克服这一障碍,研究人员提出了CLAP排序偏好优化(CRPO)框架。
CLAP排序偏好优化(CRPO)
CRPO是一个新颖的框架,通过迭代生成和优化偏好数据来增强TTA的对齐能力。具体来说,CRPO的工作流程如下:
- 初始偏好数据生成:首先,使用现有的TTA模型生成一系列音频样本,并由人工标注者根据音质、自然度等方面进行评分。
- 迭代优化:基于这些评分,CRPO框架会自动调整模型参数,生成新的音频样本,并再次进行评分。这一过程不断重复,直到模型性能达到最优。
- 偏好数据集构建:通过多次迭代,CRPO能够构建一个高质量的音频偏好数据集,这个数据集比现有替代方案更加丰富和准确。
优势
研究表明,使用CRPO生成的音频偏好数据集显著优于现有的替代方案。这不仅提升了TangoFlux在客观和主观基准测试中的表现,还为TTA生成的进一步研究提供了坚实的基础。
主要特点
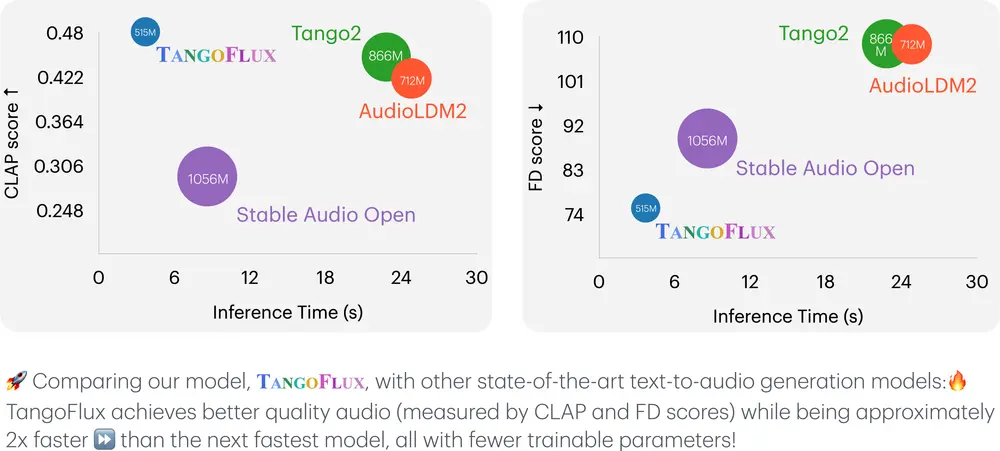
- 高速生成:TANGOFLUX能够以极快的速度生成音频,比现有的一些最快模型还要快大约2倍。
- 高保真度:该模型生成的音频质量非常高,根据CLAP和FD分数进行评估,显示出比现有技术更好的性能。
- 参数效率:尽管性能出色,TANGOFLUX的参数数量相对较少,这使得模型更加轻量化,易于部署。
- 开源:TANGOFLUX的所有代码和模型都是开源的,这有助于推动文本到音频生成领域的进一步研究。
工作原理
TANGOFLUX基于流匹配(Flow Matching)和CLAP排名偏好优化(CLAP-Ranked Preference Optimization, CRPO)框架。它通过以下步骤工作:
- 预训练:使用变分自编码器(VAE)将音频编码为潜在表示,然后通过FluxTransformer块进行预训练。
- 文本和时长条件:模型根据提供的文本描述和所需音频时长生成音频。
- 流匹配:使用流匹配框架生成样本,通过学习时间依赖的向量场将简单的先验分布(如高斯分布)映射到复杂的目标分布。
- CLAP排名偏好优化(CRPO):使用CLAP模型作为代理奖励模型,对生成的音频进行排名,并构建偏好对,以优化音频与文本描述的对齐。
性能表现
借助CRPO框架,TangoFlux在多个方面展现了其卓越的性能:
- 效率:能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频,体现了其高效的计算能力和快速的响应速度。
- 质量:无论是客观评价指标还是主观听觉测试,TangoFlux都达到了行业领先的水平,生成的音频自然流畅,音质出色。
- 灵活性:由于CRPO框架的即插即用特性,TangoFlux可以轻松适应不同的应用场景和需求,具有广泛的适用性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...