
近年来,大语言模型(LLMs)在自然语言处理领域取得了显著进展,这启发了业界对语音理解语言模型(Speech Understanding Language Models, SULMs)的开发。SULMs 不仅能够处理传统的语音识别任务,还能结合副语言信息(如情感、性别等)实现高表现力的交互。然而,大多数先进的 SULMs 由行业头部公司开发,这些模型依赖于大规模的数据和计算资源,而这些资源在学术界并不容易获得。
- GitHub:https://github.com/ASLP-lab/OSUM
- 模型:https://huggingface.co/ASLP-lab/OSUM
- Demo:https://huggingface.co/spaces/ASLP-lab/OSUM
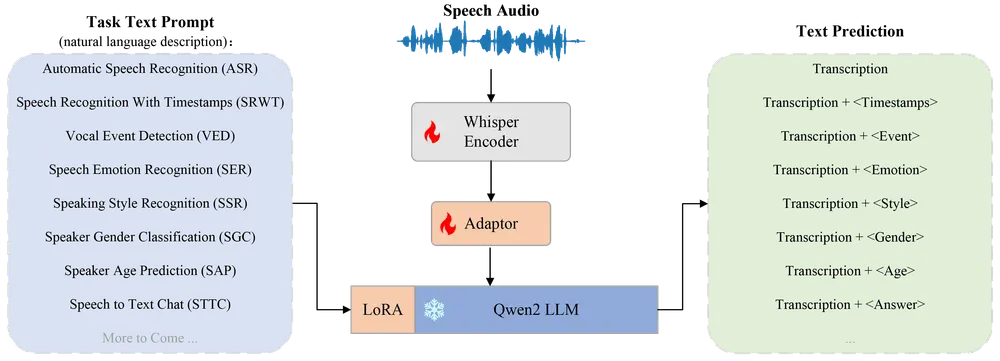
为了探索在有限资源下训练SULMs的潜力,西北工业大学的研究人员提出了OSUM——一个开源的语音理解模型。OSUM结合了Whisper编码器和大语言模型Qwen2,支持多种语音任务。通过采用ASR+X训练策略,OSUM能够同时优化模态对齐和目标任务,实现了高效稳定的多任务训练。
OSUM 的架构设计
OSUM 将 Whisper 编码器 和 Qwen2 LLM 结合起来,支持广泛的语音任务,包括但不限于:
- 语音识别(ASR):将语音转换为文本。
- 带时间戳的语音识别(SRWT):提供精确的时间戳信息。
- 语音事件检测(VED):检测语音中的特定事件(如笑声、掌声等)。
- 语音情感识别(SER):识别语音中表达的情感。
- 说话风格识别(SSR):识别说话者的语气或风格。
- 说话者性别分类(SGC):判断说话者的性别。
- 说话者年龄预测(SAP):估计说话者的年龄段。
- 语音转文本聊天(STTC):将语音转换为文本并进行对话生成。
通过采用 ASR+X 训练策略,OSUM 同时优化模态对齐和目标任务,实现了高效稳定的多任务训练。这种策略使得 OSUM 能够在有限的资源下完成复杂的语音任务。
透明性与开源贡献
除了提供强大的性能,OSUM 还强调透明性。研究人员提供了以下内容:
- 公开可用的代码:所有训练代码和推理代码均开源,便于学术界复现和改进。
- 详细的数据处理流程:清晰描述了数据预处理、特征提取和模型训练的具体步骤,为后续研究提供参考。
这种透明性不仅有助于加速 SULM 技术的研究,还为学术界提供了宝贵的资源和方法论支持。
实验评估
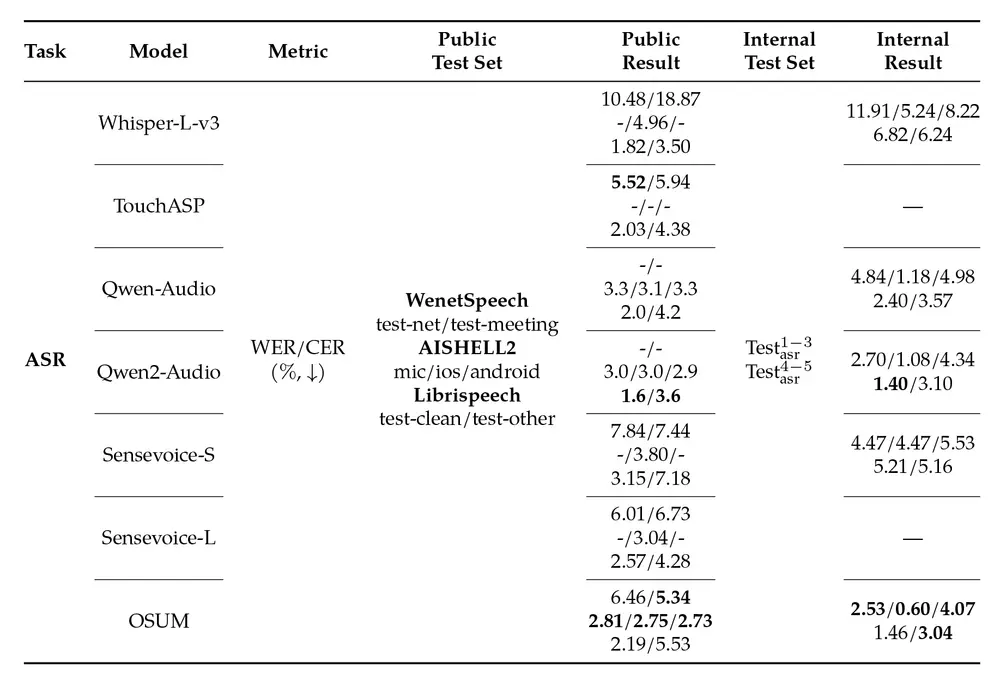
语音识别(ASR)任务
OSUM 在公共和内部测试集上的 ASR 性能表现如下表所示:
多任务评估
OSUM 在其他任务上的表现如下表所示:
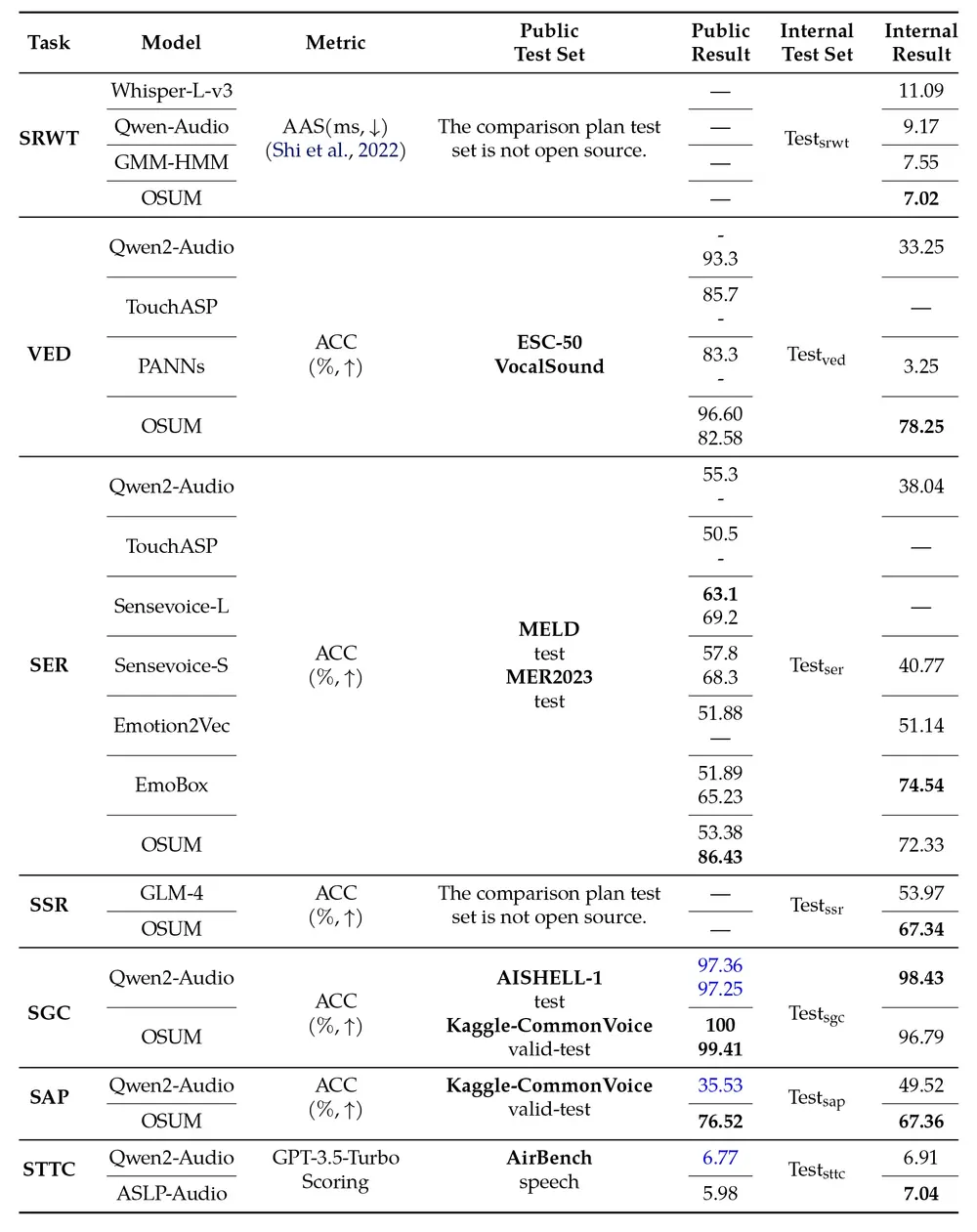
从多任务评估结果来看,OSUM 在某些任务上(如 SGC)的表现优于 Qwen2-Audio,而在其他任务上则表现出相当的竞争力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











