
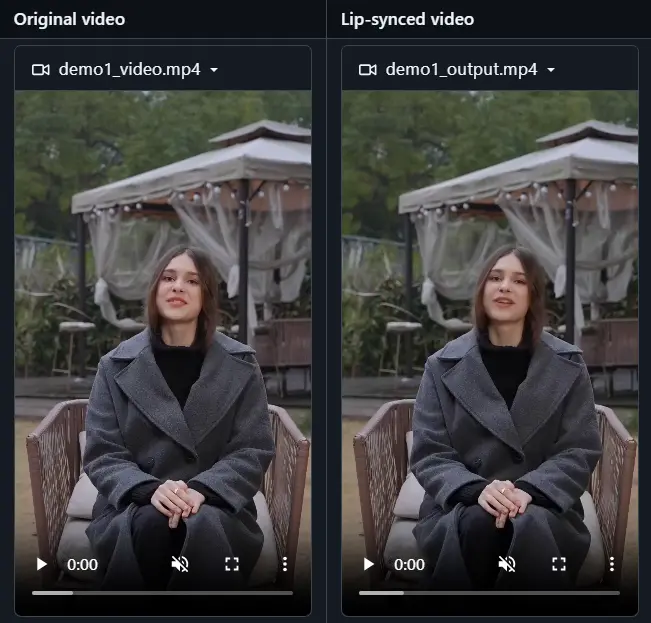
字节跳动与北京交通大学的研究团队共同提出了一种名为LatentSync的新方法,旨在解决唇音同步的问题。这一框架利用了Stable Diffusion的强大能力,通过一个端到端的流程直接建模复杂的音视频关联,而无需依赖任何中间的运动表示。这标志着与之前基于像素空间扩散或两阶段生成的扩散式唇音同步方法的区别。
- GitHub:https://github.com/bytedance/LatentSync
- 模型:https://huggingface.co/chunyu-li/LatentSync
- ComfyUI插件:https://github.com/ShmuelRonen/ComfyUI-LatentSyncWrapper
- Windows一键包:https://github.com/sdbds/LatentSync-for-windows
- Demo:https://huggingface.co/spaces/fffiloni/LatentSync
例如,你有一个视频,视频中的人物正在说话,但你希望改变他们的口型以匹配新的音频。LatentSync可以分析新的音频信号,并生成与音频同步的口型,而不需要改变视频中的其他部分,如头部姿势和个人身份。这在电影后期制作、视频会议中的实时语音转换,或者为无声视频添加配音时非常有用。
传统方法的局限性
以往的方法通常需要在像素空间中进行扩散,或者采用两阶段生成策略,这些方法往往难以处理音视频之间的时间一致性问题。由于扩散过程在不同帧之间的不一致性,导致了时间上的不连贯。为了克服这一挑战,研究团队引入了时间表示对齐(TREPA)技术,该技术能够在保持唇音同步准确性的同时,显著增强时间一致性。
主要功能
- 唇形同步生成:根据对应的语音生成准确的口型运动。
- 保持头部姿势和个人身份:在生成唇形同步视频的同时,保持视频中人物的其他特征不变。
- 端到端生成:直接从音频到视频帧的生成,无需中间的3D表示或2D地标。
主要特点
- 直接模拟音视频关联:利用Stable Diffusion直接捕捉音视频之间的复杂关联。
- Temporal REPresentation Alignment (TREPA):提出TREPA来增强时间一致性,同时保持唇形同步的准确性。
- 解决SyncNet收敛问题:通过模型架构、训练超参数和数据预处理方法的综合实验研究,显著提高了SyncNet的准确性。
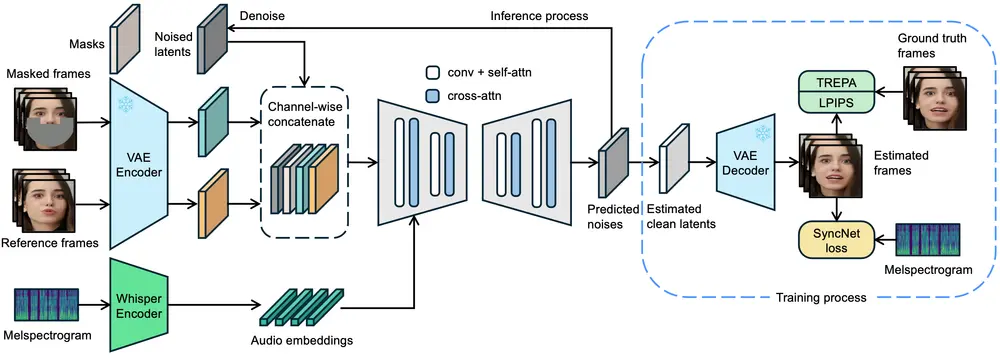
LatentSync的工作原理
LatentSync的核心在于它能够直接在潜在空间中操作,而不是传统的像素空间。以下是其工作流程:
- 音频嵌入:使用Whisper将音频的梅尔频谱图转换为音频嵌入。
- 交叉注意力机制:通过U-Net中的交叉注意力层,将音频嵌入集成到模型中,使得模型可以理解音频内容,并据此生成相应的视觉输出。
- 多帧输入:参考帧和掩码帧与噪声潜在表示在通道维度上拼接,作为U-Net的输入,以便模型学习如何从噪声中重建出清晰的图像。
- 一步预测:在训练过程中,模型通过一步法从预测的噪声中获取估计的干净潜在表示,然后将其解码以获得估计的干净帧。
- 损失函数优化:为了确保生成的帧既准确又具有良好的时间一致性,训练目标结合了TREPA、LPIPS(感知损失)和SyncNet损失,在像素空间中计算并加入训练过程。
时间表示对齐(TREPA)
为了提高时间一致性,TREPA技术利用大规模自监督视频模型提取的时间表示,将生成帧与真实帧对齐。这种方法不仅增强了唇音同步的准确性,还保证了生成视频的时间流畅性,从而提供更加自然的观看体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











