
随着多模态大语言模型(MLLMs)的发展,如何有效地整合视觉、语言和语音成为了人工智能领域面临的一个重要挑战。VITA-1.5 是由南京大学(NJU)、腾讯优图实验室(Tencent Youtu Lab)、厦门大学(XMU)和中国科学院自动化研究所(CASIA)的研究人员共同开发的一款新型多模态大语言模型。它通过一个精心设计的三阶段训练方法,成功地将这三种模态整合在一起,提供了一种更高效、更流畅的人机交互解决方案,实现接近实时的视觉和语音交互能力。
- 项目主页:https://vita-home.github.io
- GitHub:https://github.com/VITA-MLLM/VITA
- 模型:https://huggingface.co/VITA-MLLM
VITA-1.5 的目标是将视觉、语言和语音三种模态的信息进行有效整合,从而在多模态对话系统中提供更自然、更便捷的交互体验。例如,在一个虚拟的博物馆导览场景中,用户可以通过语音向 VITA-1.5 提问关于展品的信息,同时系统能够理解用户所指的展品图像,并以语音形式回答问题,实现流畅的对话。
技术细节与优势
VITA-1.5 的主要特点包括:
- 端到端框架:与前代产品 VITA-1.0 不同,VITA-1.5 无需依赖外部的自动语音识别(ASR)和文本到语音(TTS)模块,实现了端到端的语音处理能力,显著降低了交互延迟。
- 动态分块技术:用于处理图像输入,提高处理效率。
- 下采样技术:应用于音频数据,以优化处理速度和质量。
- 非自回归(NAR)与自回归(AR)结合的语音解码器:确保了语音生成的质量和流畅性。
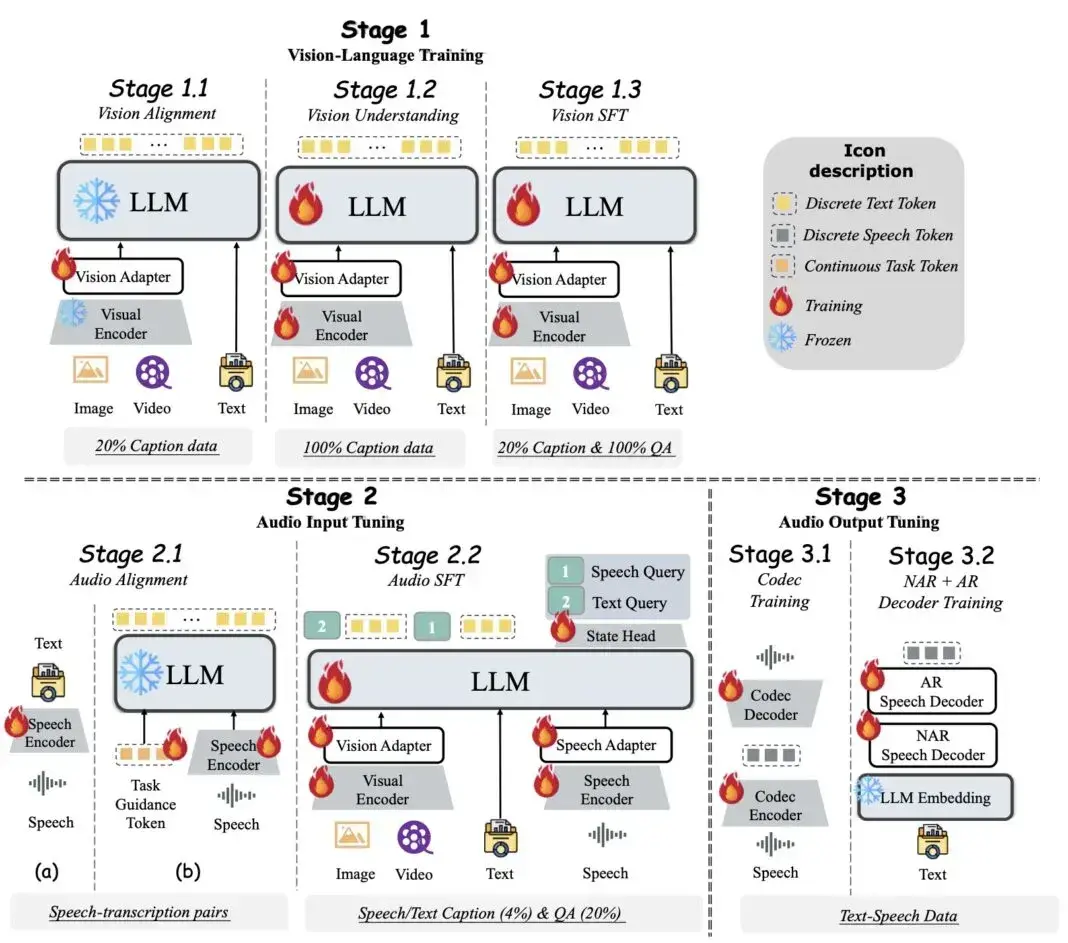
训练过程分为三个关键阶段,逐步建立并调优不同模态之间的联系,最终实现无缝的多模态交互体验。
性能提升
VITA-1.5 在多个方面展现了显著的性能提升:
- 交互延迟大幅减少:从原先的大约4秒降低到了1.5秒,极大地改善了用户体验。
- 多模态性能增强:在MME、MMBench 和 MathVista 等测试中的平均得分从59.8上升至70.8。
- 语音处理能力加强:语音识别错误率(WER)从18.4降至7.5,并且采用了直接接受大语言模型嵌入作为输入的端到端TTS模块。
此外,VITA-1.5 的渐进式训练策略保证了语音模态的加入对其他多模态性能影响极小,仅使图像理解性能从71.3轻微下降到70.8。
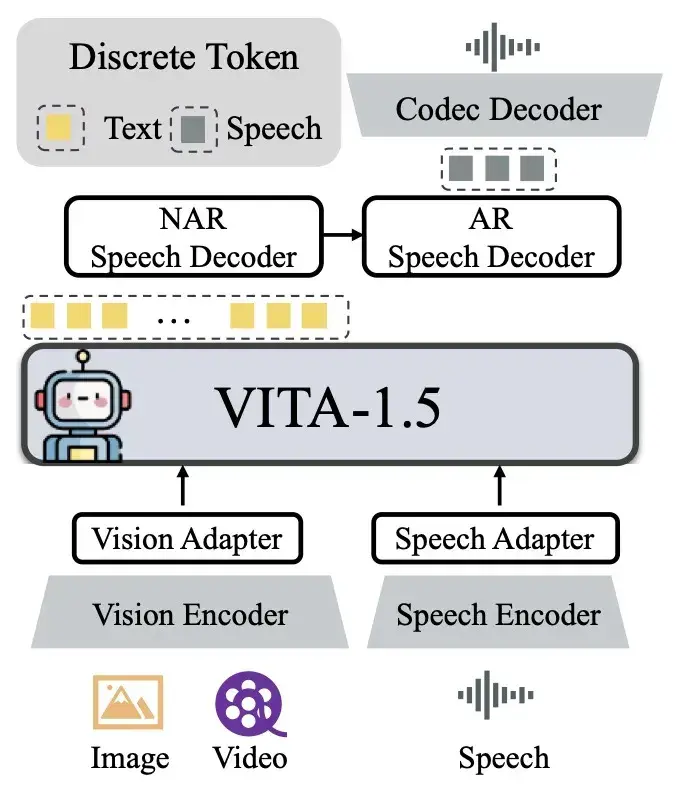
工作原理
- 视觉模态处理:VITA-1.5 使用 InternViT-300M 作为视觉编码器,将输入的图像或视频帧转换为视觉特征,然后通过视觉适配器将这些特征映射为适合后续语言模型理解的视觉 token。
- 语音模态处理:对于语音输入,模型首先通过语音编码器将语音信号转换为音频特征,然后通过语音适配器将这些特征整合到语言模型中。在语音输出阶段,VITA-1.5 使用非自回归(NAR)和自回归(AR)语音解码器,将文本 token 转换为语音 token,最终通过语音编解码器生成连续的语音信号。
- 多模态融合与对话:在多模态对话过程中,VITA-1.5 能够同时接收和处理视觉和语音输入,通过语言模型对多模态信息进行融合和推理,生成相应的语音回复,实现流畅的交互体验。
结果与洞察
评估显示,VITA-1.5 在多种基准测试中表现出色,尤其是在图像和视频理解任务上,其表现堪比顶级开源模型。同时,在语音任务中也取得了优异的成绩,如在普通话中实现了低字符错误率(CER),英语中实现了低单词错误率(WER)。值得注意的是,尽管增加了音频处理功能,但并未对其视觉推理能力造成负面影响。
具体应用场景
- 智能客服:在在线购物、银行服务等领域,VITA-1.5 可以作为智能客服系统的核心,通过语音与用户进行交流,同时展示相关的商品图片、服务流程视频等,提供更加直观、便捷的服务。
- 教育辅助:在教育领域,VITA-1.5 可以辅助教师进行教学,例如在语言学习中,通过展示图片和视频,帮助学生更好地理解和记忆词汇和语法知识,同时与学生进行语音互动,提高学习效果。
- 虚拟导游:在旅游行业,VITA-1.5 可以作为虚拟导游,为游客提供景点介绍、路线指引等服务。游客可以通过语音向系统提问,系统会结合景点的图片和视频信息,以语音形式进行回答,让游客获得更加丰富、生动的旅游体验。
- 智能家居控制:在智能家居场景中,VITA-1.5 可以作为语音控制中心,用户可以通过语音指令控制家中的各种智能设备,如灯光、空调、电视等,同时系统能够展示设备的使用状态和操作指南,提高家居生活的便利性和舒适度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











