近年来,自动语音识别(ASR)技术取得了显著进展,这主要得益于模型架构的改进和大规模数据集的可用性。然而,现有的多语言 ASR 模型(如 Whisper)在处理东方语言时表现不佳,且存在可重复性问题
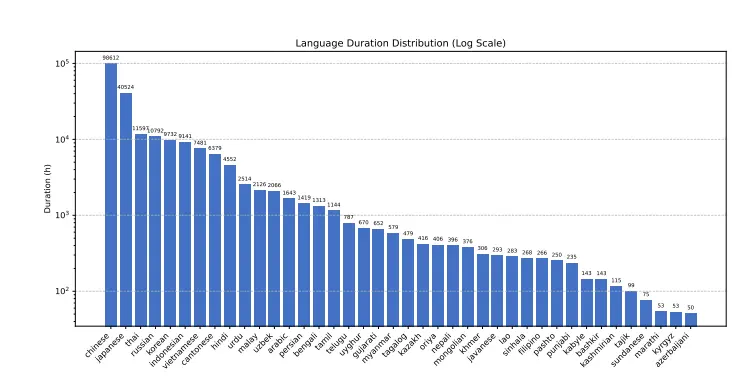
为了解决这些问题,Dataocean AI 和清华大学合作开发的多语言、多任务 ASR 模型Dolphin,它支持东亚、南亚、东南亚和中东地区的 40 种东方语言,同时也支持 22 种中国方言。该模型在超过 210,000 小时的数据上进行训练,这些数据包括 DataoceanAI 的专有数据集和开源数据集。该模型可以执行语音识别、语音活动检测(VAD)、分段和语言识别(LID)。
- GitHub:https://github.com/DataoceanAI/Dolphin
- Huggingface:https://huggingface.co/DataoceanAI
- 魔塔:https://www.modelscope.cn/organization/DataoceanAI
Dolphin 大体上遵循了 Whisper 和 OWSM 的创新设计方法。采用联合 CTC-Attention 架构,编码器基于 E-Branchformer,解码器基于标准 Transformer。为了特别关注 ASR,引入了几个关键的修改。Dolphin 不支持翻译任务,并且消除了对先前文本及其相关标记的使用。
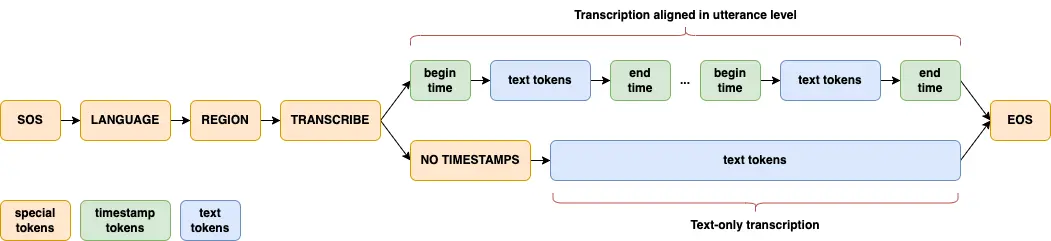
Dolphin 的一个显著增强是引入了两级语言标记系统,以更好地处理语言和区域多样性,特别是在 Dataocean AI 数据集中。第一个标记指定语言(例如 <zh>,<ja>),而第二个标记指示地区(例如 <CN>,<JP>)。
主要功能
- 多语言支持:Dolphin 支持 40 种东方语言和 22 种中文方言,覆盖了东亚、南亚、东南亚和中东地区。
- 高性能:在多种语言上,Dolphin 的性能显著优于现有的开源模型,包括 Whisper。
- 可扩展性:Dolphin 提供了不同大小的模型版本(如 base、small、medium 和 large),以满足不同的应用场景和资源需求。
- 开源:为了促进研究和社区创新,Dolphin 的训练模型和推理代码将公开发布。
主要特点
- 专有数据与开源数据结合:Dolphin 通过结合内部专有数据和公开的开源数据集进行训练,提高了模型的泛化能力。
- 优化的架构:Dolphin 采用了基于 E-Branchformer 的编码器和标准 Transformer 的解码器,结合了 CTC 和注意力机制,提高了训练效率和性能。
- 多任务格式:Dolphin 引入了两级语言标记系统,能够更好地处理语言和方言的多样性。
- 显著的性能提升:Dolphin 在多种语言上的平均词错误率(WER)显著低于 Whisper,即使在较小的模型尺寸下也能实现更好的性能。
工作原理
- 模型架构:Dolphin 采用了联合 CTC-注意力架构,结合了 E-Branchformer 编码器和 Transformer 解码器。这种架构能够有效地捕捉输入语音信号的局部和全局依赖关系。
- 多任务学习:Dolphin 支持多种语音相关任务,如转录、翻译、语音活动检测等。通过引入两级语言标记系统,Dolphin 能够更好地处理语言和方言的多样性。
- 数据处理:Dolphin 的训练数据包括内部专有数据和多个开源数据集,总时长超过 20 万小时。数据经过清洗和格式化,以确保高质量的训练。
- 训练策略:Dolphin 在训练过程中采用了多种优化策略,如数据分段、数据增强和优化的数据加载策略,以提高训练效率和模型性能。
应用场景
- 多语言语音识别:Dolphin 可以用于多种语言的语音识别任务,特别是在东方语言和方言的识别上表现出色。
- 语音翻译:虽然 Dolphin 不直接支持翻译任务,但其强大的语音识别能力可以为后续的翻译任务提供高质量的输入。
- 语音助手:Dolphin 可以集成到语音助手系统中,为用户提供多语言支持,特别是在处理东方语言时。
- 实时语音识别:Dolphin 的高效架构和优化的训练策略使其适合实时语音识别应用,能够快速准确地识别语音内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











