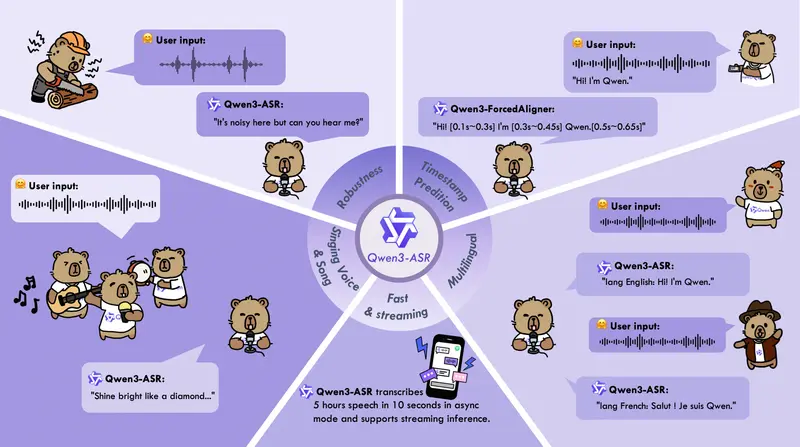
香港科技大学的研究人员推出统一DiT架构模型AudioX,通过多模态输入(如文本、视频、图像、音乐和音频)生成高质量的音频和音乐。AudioX通过创新的多模态掩码训练策略,强制模型从掩码输入中学习,从而生成鲁棒且统一的跨模态表示。此外,研究者还构建了两个综合数据集,以解决高质量多模态训练数据稀缺的问题。
例如,你有一个视频片段,展示了一辆汽车在道路上行驶的场景。使用AudioX模型,你可以输入这个视频片段,并要求模型生成与视频内容匹配的音频,例如汽车行驶的声音。模型不仅能够生成与视频内容一致的音频,还可以根据文本提示(如“汽车在高速公路上行驶的声音”)进一步优化生成的音频,使其更加符合用户的期望。
主要功能
- 多模态输入支持:AudioX能够处理多种输入模态,包括文本、视频、图像、音乐和音频,并将它们灵活组合以生成音频。
- 高质量音频生成:模型能够生成高质量的音频和音乐,适用于多种应用场景,如电影配乐、视频特效音效等。
- 灵活的自然语言控制:用户可以通过自然语言描述来指导音频生成,例如指定音频的风格、情感或特定的乐器。
- 音频修复和音乐续写:模型支持音频修复(如音频修复)和音乐续写任务,能够根据给定的音频片段生成后续内容。
- 零样本图像到音频生成:即使没有特定的图像数据训练,模型也能根据图像内容生成相关的音频。
主要特点
- 多模态掩码训练策略:通过随机掩码输入模态(如视频帧、文本标记和音频片段),强制模型学习从不完整的输入中生成音频,从而提高跨模态表示的鲁棒性。
- 扩散模型与变换器的结合:AudioX基于扩散变换器(Diffusion Transformer),结合了扩散模型在高质量音频生成方面的优势和变换器在多模态对齐方面的优势。
- 大规模多模态数据集:研究者构建了两个大规模多模态数据集(vggsound-caps和V2M-caps),为模型训练提供了丰富的基础。
- 广泛的适用性:AudioX不仅在单一模态任务(如文本到音频、视频到音频)上表现出色,还在多模态组合任务(如文本和视频到音频)上展现出强大的性能。
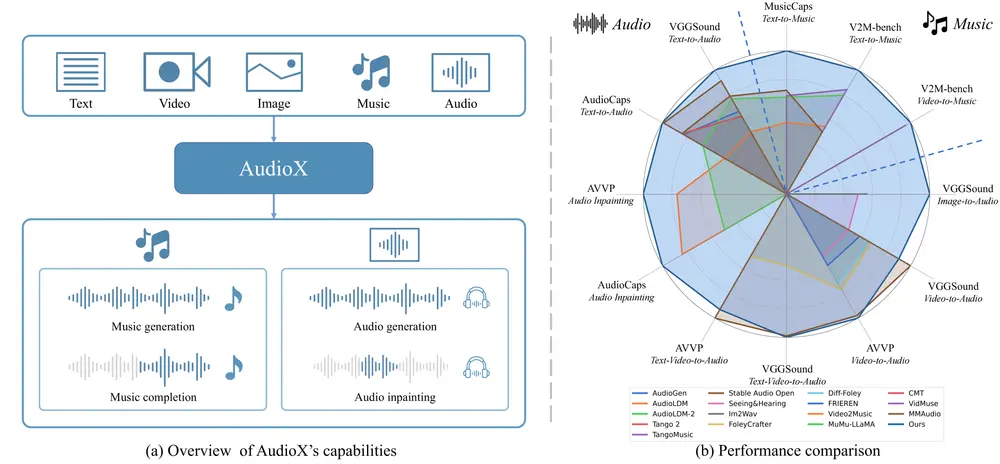
工作原理
- 多模态输入处理:
- 视频输入:使用视频编码器(如CLIP-ViT-B/32)提取视频帧特征。
- 文本输入:使用文本编码器(如T5-base)处理文本输入。
- 音频输入:使用音频编码器(如Autoencoder)处理音频输入。
- 掩码策略:随机掩码部分输入,例如视频帧、文本标记和音频片段,以增强模型的跨模态学习能力。
- 多模态特征融合:
- 特征提取:将处理后的视频、文本和音频特征通过投影模块转换为统一的特征空间。
- 特征融合:将这些特征拼接成一个多模态条件嵌入,用于后续的音频生成。
- 扩散生成过程:
- 扩散模型:使用扩散模型(如Diffusion Transformer)在潜在空间中逐步去噪,生成高质量的音频或音乐。
- 条件生成:根据多模态条件嵌入生成与输入条件一致的音频。
应用场景
- 电影和视频制作:
- 音效生成:根据视频内容自动生成匹配的音效,如环境音、动作音等。
- 配乐生成:根据视频的情感和节奏生成背景音乐,提升观众的观看体验。
- 音频修复:修复视频中的音频片段,填补缺失或损坏的部分。
- 游戏开发:
- 实时音效:根据游戏场景动态生成音效,增强游戏的沉浸感。
- 背景音乐:根据游戏情节生成匹配的背景音乐,提升玩家的情感共鸣。
- 社交媒体和内容创作:
- 创意音频生成:根据文本描述生成独特的音频内容,用于社交媒体视频或广告。
- 音乐创作:根据文本提示生成音乐,为创作者提供灵感。
- 教育和培训:
- 互动学习:生成与教育内容匹配的音频,如自然现象的声音或历史事件的背景音乐,增强学习的趣味性。
- 语言学习:生成与语言学习内容匹配的音频,帮助学生更好地理解和记忆。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











