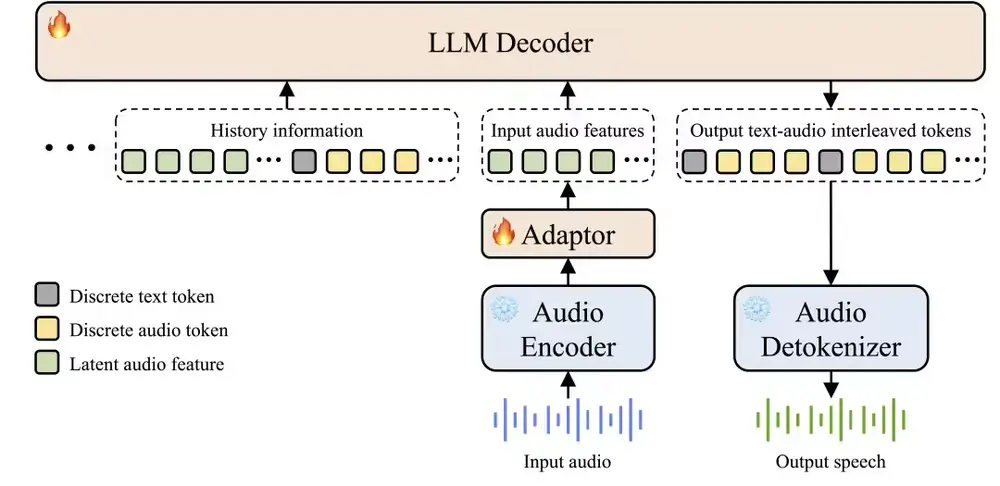
香港科技大学的研究团队近期在探索从给定歌词生成完整歌曲音频的领域取得了重要进展,这一过程被称为“歌词到歌曲”(lyrics2song)。尽管基于文本条件的音乐生成模型在创作非人声音乐短片段方面已经展现出了卓越的能力,但要生成包含人声与伴奏、时长达到数分钟的完整歌曲仍是一个巨大的挑战。目前,仅有一些闭源的商业系统能够提供令人满意的结果。
- 项目主页:https://map-yue.github.io
- GitHub:https://github.com/multimodal-art-projection/YuE
- 模型:https://huggingface.co/m-a-p
面临的挑战
将歌词转化为歌曲面临的四大挑战包括:
- 音乐的长上下文特性:需要处理和理解较长篇幅的音乐内容。
- 音乐信号的复杂性:相较于其他类型的信号(如语音、音效),音乐信号更加复杂。
- 语言内容的扭曲:确保歌词与生成的旋律相匹配且不失真。
- 平行数据的缺乏:即歌词-音频对的数据稀缺问题。
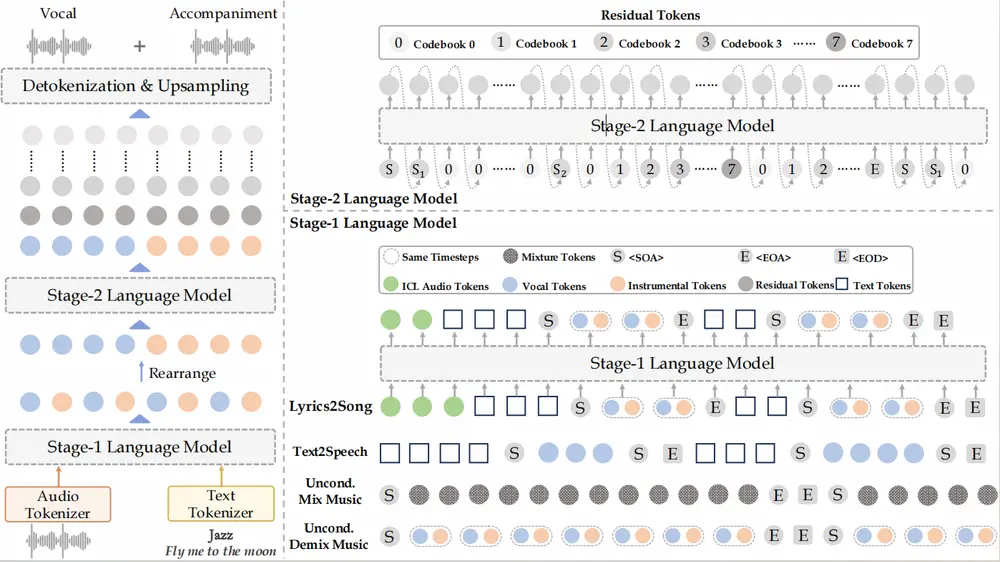
YuE的解决方案
为了解决这些问题,研究团队开发了YuE——一系列专为歌词到歌曲任务设计的开放基础语言模型,并将其整合进llama家族中。以下是YuE所采用的关键技术:
- 语义增强的音频分词器:用于降低训练成本并加速模型收敛。
- 双分词技术:在不改动llama解码器架构的前提下,实现了同步的人声-乐器建模。
- 歌词思维链:帮助模型逐步生成整首歌曲,并在整个过程中遵循歌词条件。
- 三阶段训练方案:旨在提升模型的可扩展性、音乐表现力以及歌词控制能力。
结果展示
YuE模型能够生成长达5分钟的高质量音乐音频,其不仅包含了引人入胜的人声旋律,还配备了合适的伴奏,确保最终作品既和谐又精致。此外,YuE能够模拟多种音乐流派和演唱风格,包括但不限于流行和金属风格。想要了解更多不同风格的作品,请访问我们的演示页面。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











