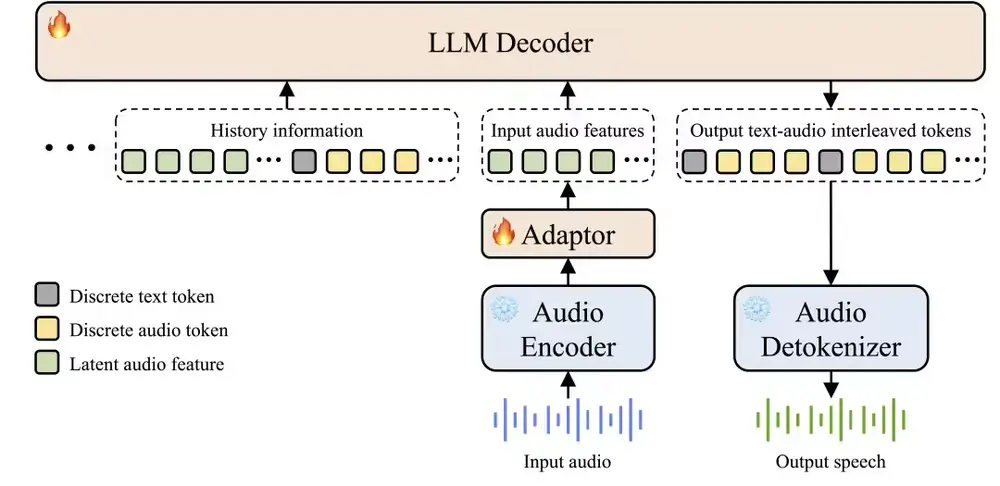
文本转语音(TTS)技术正成为人机交互领域的重要工具。随着娱乐、无障碍服务、客户服务和教育等行业对语音合成的需求不断增加,市场对逼真、情感丰富且支持多种语言的语音合成技术的需求也在迅速增长。然而,传统的TTS系统虽然功能强大,但在真实感和个性化方面仍存在不足。
- GitHub:https://github.com/zhenye234/LLaSA_training
- 模型:https://huggingface.co/HKUSTAudio
- Demo:https://huggingface.co/spaces/srinivasbilla/llasa-3b-tts
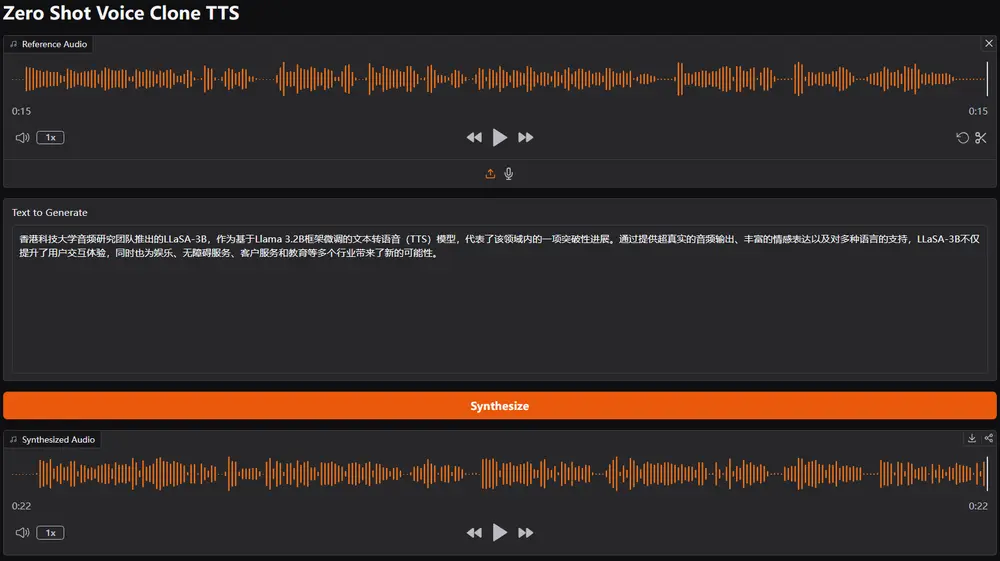
为了解决这些挑战,香港科技大学音频研究团队开发了一个文本转语音(TTS)系统LLaSA,它通过整合来自XCodec2码本的65,536个语音标记,扩展了基于文本的LLaMA(1B、3B和8B)语言模型。研究团队在包含25万小时中英文语音数据的数据集上训练了Llasa,使其能够仅从输入文本生成高质量的语音,或通过使用给定的语音提示来生成带有特定音色和情感特征的语音。
核心特点与优势
- 超真实音频输出:LLaSA-3B基于一个庞大的25万小时音频数据集进行训练,能够生成极其逼真的语音。这种高度的真实感使得合成语音听起来几乎与自然人类语音无异。
- 情感表达:该模型特别擅长于传达不同情感的声音,如快乐、愤怒、悲伤甚至低语等。这极大地增强了用户的参与度,并拓宽了其在各种应用场景中的实用性。
- 多语言支持:LLaSA-3B支持英语和中文两种全球主要语言,能够无缝处理这两种语言的复杂性,展现了其设计上的多样性和广泛的应用潜力。
- 语音克隆功能:Llasa只需15秒的声音样本就能实现高度准确的声音克隆,不仅能够保持原声音的音色,还能捕捉到其情感特征,这对于个性化虚拟助手、配音及本地化工作来说是非常宝贵的特性。
主要亮点
- 情感丰富的语音合成:LLaSA-3B能够生成包含快乐、悲伤、愤怒和低语等情感的逼真语音。
- 双语支持:该模型支持英语和中文,适合全球多样化的受众和个性化应用。
- 多种参数变体:提供10亿和30亿参数的变体,80亿参数版本正在开发中,以满足不同的部署需求。
- 开放权重框架:兼容Transformers和vLLM等工具,鼓励协作并推动TTS技术的进一步发展。
- 广泛的应用场景:从虚拟现实和游戏到无障碍服务和客户服务,LLaSA-3B以真实且引人入胜的音频重新定义了人机交互。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











