
Rev 最近宣布开源其尖端的 Reverb 自动语音识别 (ASR) 和话者分离模型。经过 200,000 小时高质量人工转录的英语语音训练,Reverb 在长篇语音识别领域中表现出色,超越了所有现有的开源语音识别模型。
- 官网:https://www.rev.ai
- GitHub:https://github.com/revdotcom/reverb
- 模型:https://huggingface.co/Revai
- Demo:https://huggingface.co/spaces/Revai/reverb-asr-demo

以下是 Reverb 的几个关键特点和优势:
无与伦比的准确性: Reverb 在各种长篇语音识别任务中表现出色,不仅仅是渐进式的改进,而是开源 ASR 领域的一大飞跃。
民主化高级 AI: 通过开源 Reverb,Rev 将企业级的语音识别能力交到了全球研究人员、开发人员和创新者手中,加速了语音技术在多个领域的进步。
逐字控制: Reverb 提供了独特的功能,可以控制转录中的逐字程度,适用于从精确的法律转录到更易读的字幕等多种应用场景。
话者分离卓越: Reverb 不仅能转录音频,还能理解谁在说话。其经过 26,000 小时专家标注数据微调的尖端话者分离模型,为多说话人环境中的说话人归属设定了新标准。
研究人员和开发人员的灵活性: Rev 同时发布了完整的生产管道和简化的研究模型,确保 Reverb 可以在学术和商业环境中推动创新。
新 ASR 模型和灵活许可
Rev 推出了两款新的 ASR 模型:
Reverb V1:旗舰模型,提供无与伦比的准确性,每小时成本仅为 20 美分。 Reverb Turbo V1:快速的选择,每小时成本为 10 美分,同时保持高准确性。
这两款模型都包含了尖端的话者分离功能,提供了一个完整的转录和说话人归属解决方案。

对于开源模型的用户,Rev 提供了极具竞争力的定价:
Reverb 自托管:每小时 20 美分 Reverb Turbo 自托管:每小时 10 美分
Rev 还提供“无限量”许可选项,以满足不同项目的需求。有兴趣的用户可以联系 Rev 讨论具体的许可方案。
模型架构和技术细节
ASR 模型架构:
训练数据:Reverb ASR 在 200,000 小时的英语语音上进行了训练,所有语音都由专家人工转录,这是迄今为止用于训练开源模型的最大人工转录音频语料库。 模型架构:使用修改版的 WeNet 工具包进行训练,采用联合 CTC/注意力架构。编码器有 18 个 conformer 层,双向注意力解码器有 6 个 transformer 层,每个方向 3 层,总参数量约为 6 亿。 逐字控制:通过特定语言层机制控制输出的逐字程度,这些层被添加到编码器和解码器的第一和最后一层。
话者分离模型:
训练数据:使用高性能的 pyannote.audio 库,在 26,000 小时专家标注的数据上对现有模型进行了微调。 模型架构:Reverb 话者分离 v1 使用 pyannote3.0 架构,而 v2 使用 WavLM 特征。
性能基准测试
Rev 使用长篇语音识别语料库对 Reverb ASR 进行了基准测试,包括 Rev16(播客)、Earnings21(美国公司的盈利电话)和 Earnings22(全球公司的盈利电话)。结果显示,Reverb ASR 在这些测试套件中显著优于现有的开源模型,特别是在处理非英语母语者的语音时表现尤为出色。
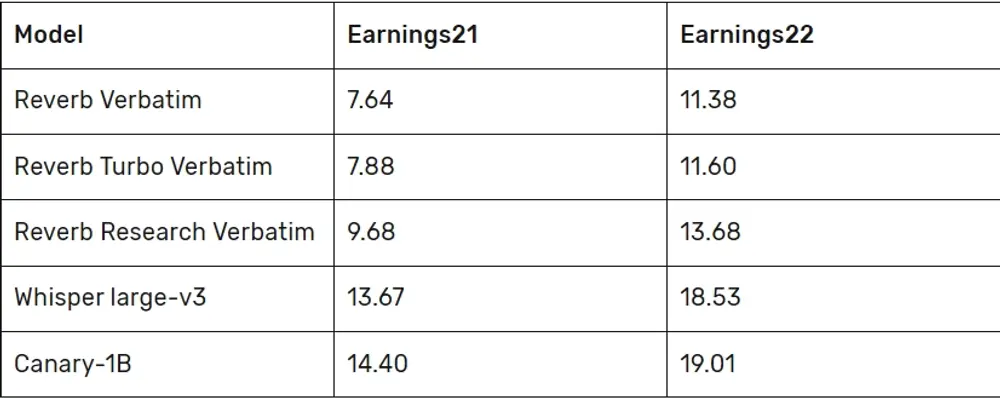
推动研究和创新
为了促进研究和创新,Rev 推出了“Rev 模型非生产许可证”,允许任何人免费使用这些模型进行评估、研究和私人用途。这一举措为学者、爱好者和创新者提供了探索和构建 Rev 技术的机会,而无需承担财务负担。
对于商业应用,Rev 提供专有许可证,并致力于与各种规模的企业合作,找到合适的许可解决方案,使他们能够在其产品和服务中利用 Reverb 的强大功能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











