
Sesame 团队近期发布了一项名为 Conversational Speech Model (CSM) 的全新语音技术,旨在解决当前语音助手普遍存在的“死板”问题。这项技术的目标是让语音助手不仅能够听懂用户的情绪,还能通过自然流畅的对话让用户感受到与真人交流的体验。
- 项目主页:https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice
- 模型:https://huggingface.co/sesame/csm-1b
- Demo:https://huggingface.co/spaces/sesame/csm-1b
- CSM-WebUI:https://github.com/Saganaki22/CSM-WebUI

为了展示 CSM 的潜力,团队设计了两个演示角色:Maya(女声) 和 Miles(男声)。根据用户的反馈,这些角色表现出色,能够在对话中展现出更高的互动性和情感感知能力。不过需要注意的是,目前该技术仅支持英语。
背景与挑战
为了让 AI 伙伴真正实现自然互动,语音生成技术必须超越单纯生成高质量音频的能力——它需要实时理解并适应上下文环境。传统的文本转语音(TTS)模型直接从文本生成语音输出,但缺乏自然对话所需的上下文感知能力。即使最近的一些模型已经能够生成高度类人的语音,它们仍然难以应对复杂的一对多问题:一句话可能有无数种有效的表达方式,但只有少数几种适合特定场景。如果没有额外的上下文信息(如语调、节奏和对话历史),模型很难选择最佳的表达方式。
为了解决这些问题,Sesame 团队引入了 Conversational Speech Model (CSM),这是一种基于 Transformer 的端到端多模态学习框架,能够利用对话历史生成更自然、连贯的语音。
CSM 的核心技术
1. 多模态学习框架
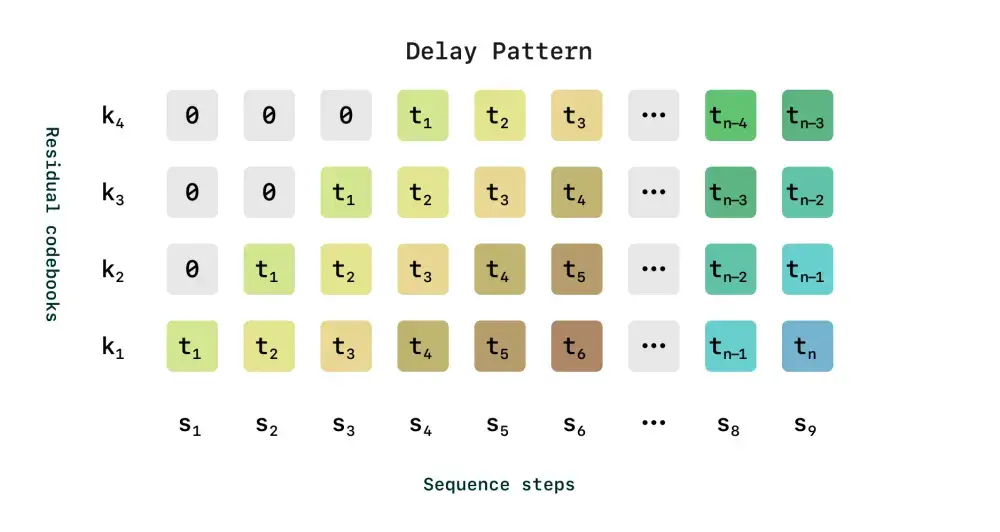
CSM 将语音生成建模为一个多模态任务,结合了文本和语音输入。它使用两个自回归 Transformer 来完成任务:
- 第一阶段(多模态骨干):处理交错的文本和音频标记,生成第零级码书。
- 第二阶段(音频解码器):基于第一阶段的输出,生成剩余的 N-1 级码书,重建高保真语音。
这种设计使得 CSM 能够在单阶段内高效运行,同时保留了韵律和情感细节。
2. 音频标记的处理
CSM 使用两种类型的音频标记:
- 语义标记:捕捉语言和韵律的关键特征,但牺牲了一些高保真细节。
- 声学标记:编码精细的声学细节,用于重建高质量的语音。
通过将语义标记和声学标记结合,CSM 能够在保证语音自然度的同时,灵活适应不同的对话场景。
3. 实时性优化
传统的基于 RVQ 的方法在实时场景中表现不佳,因为它们需要等待所有码书级别的预测完成才能生成第一个音频块。为了解决这一问题,CSM 引入了一种计算摊销方案,只对随机子集进行训练,从而显著降低了内存负担,提高了实时性能。

实验与评估
数据集
团队使用了一个包含约一百万小时英语音频的大规模公开数据集,并对其进行了转录、说话人分离和分段处理。
模型大小
CSM 提供了三种不同规模的模型:
- Tiny:10 亿参数骨干 + 1 亿参数解码器
- Small:30 亿参数骨干 + 2.5 亿参数解码器
- Medium:80 亿参数骨干 + 3 亿参数解码器
每个模型均以 2048 的序列长度(约 2 分钟音频)训练了五个周期。
评估指标
团队设计了一套全面的评估体系,涵盖以下四个方面:
- 文本忠实度:衡量生成语音是否准确反映了输入文本内容。
- 上下文利用率:评估模型是否能根据对话历史生成适当的回应。
- 韵律表现:检测生成语音的自然度和情感表达能力。
- 延迟性能:测试模型在实时场景中的响应速度。
客观指标
- 词错误率(WER) 和 说话人相似度(SIM):现代模型在这两项指标上已接近人类水平。
- 同形异义消歧测试:评估模型是否能正确发音具有相同拼写但不同意义的单词(如“lead” /lɛd/ 和 “lead” /liːd/)。
- 发音一致性测试:检查模型是否能在多轮对话中保持特定单词的发音一致性(如“route” /raʊt/ 或 /ruːt/)。
以下是不同模型大小的客观指标结果:
| 模型大小 | 同形异义准确率 | 发音一致性准确率 |
|---|---|---|
| Tiny | 75% | 68% |
| Small | 82% | 76% |
| Medium | 90% | 85% |
主观指标
团队使用 Expresso 数据集进行了两项 CMOS(比较平均意见分数)研究,邀请人类评估员对生成语音的自然度和韵律适当性进行评分。结果显示,随着模型规模的增加,生成语音的质量显著提升。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











