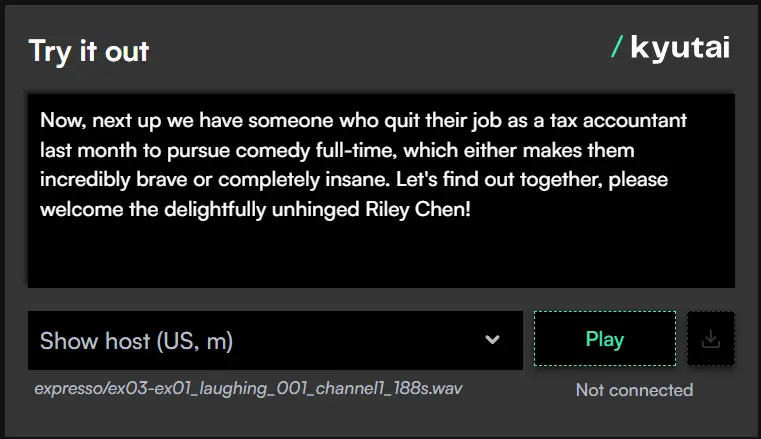
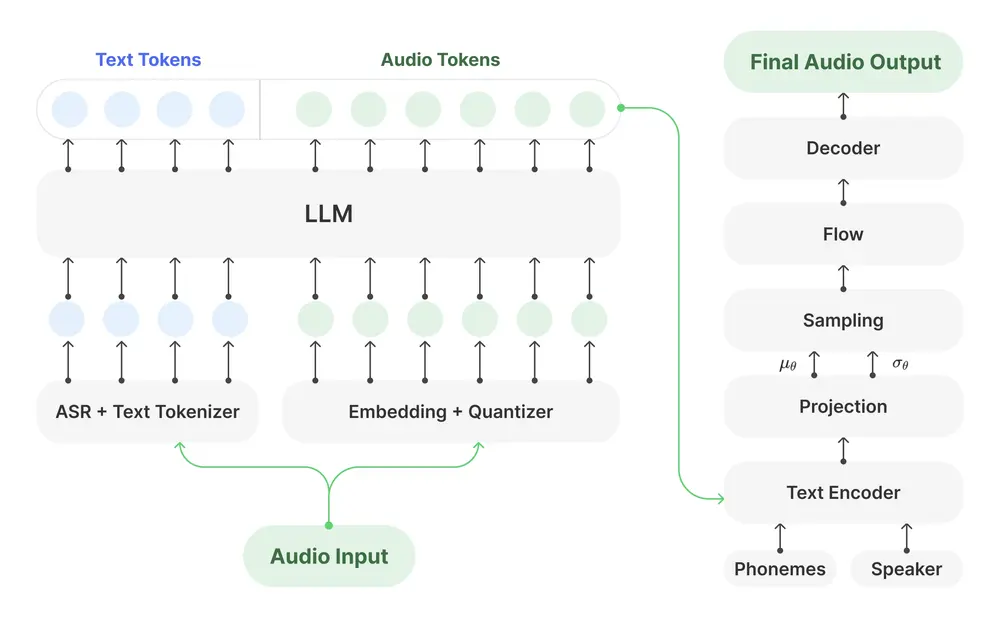
Kyutai Labs推出新一代流式TTS模型Kyutai TTS:实时语音生成迈入新阶段近日,Kyutai Labs 正式开源了一款名为 Kyutai TTS 的文本转语音(TTS)模型,参数规模达到16亿,支持实时、流式处理,成为该领域的技术新标杆。这一模型不仅具备出色的语音生成能力...语音模型# Kyutai Labs# Kyutai TTS# TTS模型9个月前02780
ElevenLabs 发布 Eleven v3(Alpha 版),迄今最具表现力的TTS模型在语音合成技术不断进化的今天,ElevenLabs 正式推出了其最新一代文本转语音模型 —— Eleven v3(Alpha 版)。该版本在情感表达、对话自然度和多语言支持方面实现了重大突破,被誉为目...早报# Eleven v3# ElevenLabs# TTS模型10个月前04860
OpenAudio S1:Fish Audio 推出媲美语音演员的尖端文本转语音模型Fish Audio 重磅推出 OpenAudio S1 —— 一款在表现力、自然度和可控性方面达到新高度的文本转语音(TTS)模型。作为目前全球最先进的开源 TTS 模型之一,S1 在超过 200万...语音模型# Fish Audio# OpenAudio S1# TTS模型10个月前04870
Resemble AI推出首个情感可控的开源TTS模型ChatterboxResemble AI正式发布了其首个生产级开源TTS模型——Chatterbox。这是目前市面上少有的、具备高质量语音合成能力并支持情感控制的开源项目。目前仅支持英文。 GitHub:https...语音模型# Chatterbox# Resemble AI# TTS模型7个月前03960
北京沐言智语科技开源专为播客场景优化的可训练TTS模型 Muyan-TTS 北京沐言智语科技开源可训练文本到语音(TTS)模型 Muyan-TTS ,专为播客场景优化,并在5万美元的预算内开发。该模型通过在超过10万小时的播客音频数据上进行预训练,能够实现高质量的零样本文本到...语音模型# Muyan-TTS# TTS模型11个月前03970
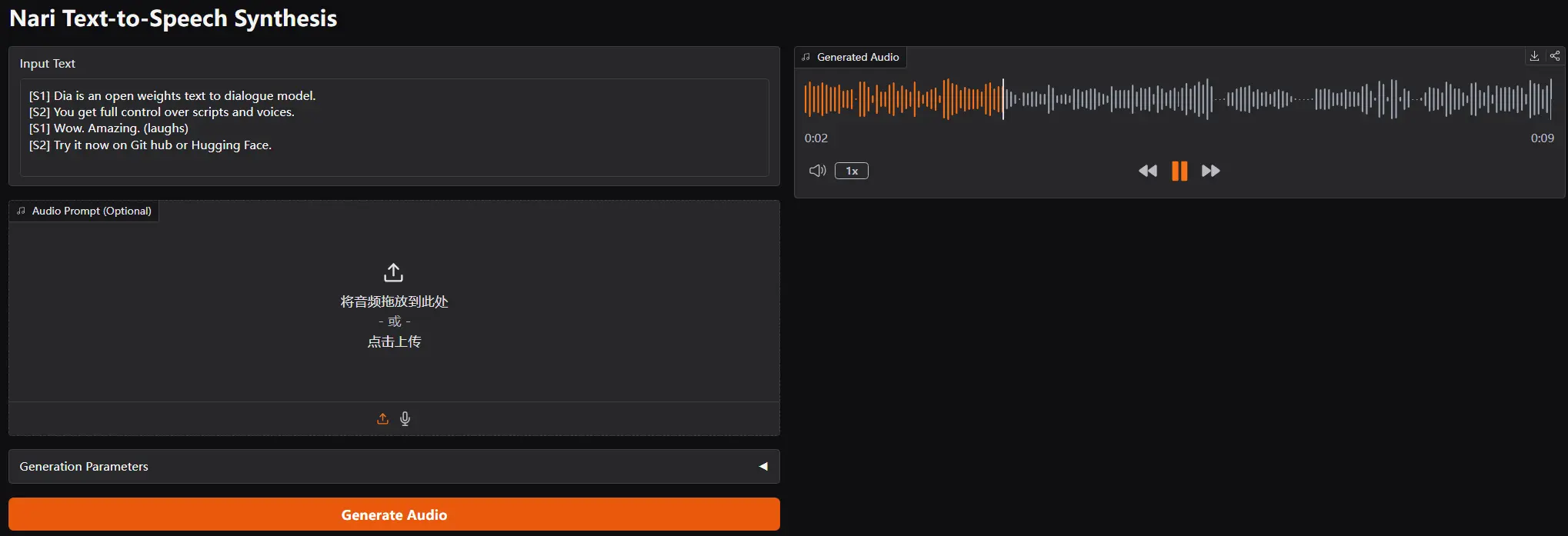
Nari Labs开源TTS模型Dia-1.6B:生成自然对话与非语言表达,支持声音克隆Nari Labs在今天开源了一个拥有16亿参数的文本转语音模型Dia-1.6B。这个模型的最大亮点在于它能够生成高度逼真的对话,并且加入了自然人声元素,比如笑声、咳嗽、清喉咙等,让语音合成更加生动自...语音模型# Dia-1.6B# Nari Labs# TTS模型11个月前02,2490
字节跳动与浙大联合发布轻量高效TTS模型MegaTTS3字节跳动和浙江大学的研究人员推出的一款轻量级TTS模型:MegaTTS3,0.45B,高质量语音克隆,支持中英文以及中英文混合,支持口音强度控制,后面会支持更细粒度的发音和时长调整。 GitHub:h...语音模型# MegaTTS3# TTS模型# 字节跳动1年前04840
Zyphra开源支持高保真语音克隆的实时文本转语音(TTS)模型 Zonos-v0.1 测试版Zyphra 最近发布了 Zonos-v0.1 测试版,这是一款支持高保真语音克隆的实时文本转语音(TTS)模型。作为开源项目的一部分,Zonos-v0.1 包含两个强大的 TTS 模型:一个 16 ...语音模型# TTS模型# Zonos-v0.11年前02470
Audiblez:基于TTS模型Kokoro的Python 3应用,轻松地将电子书转换为有声书Kokoro是一款最近发布的文本转语音(TTS)模型,尽管其参数量仅为8200万,但它能够生成极其自然的语音输出。该模型基于Apache许可证发布,并且仅使用了不到100小时的音频数据进行训练。尽管规...工具# Audiblez# Kokoro# TTS模型1年前03530
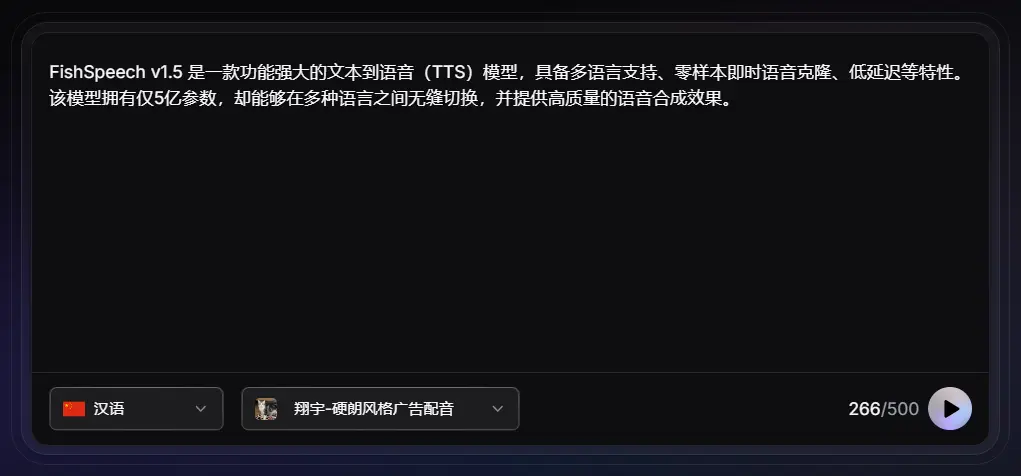
TTS模型FishSpeech推出v1.5 版本:具备多语言支持、零样本即时语音克隆、低延迟等特性FishSpeech v1.5 是一款功能强大的文本到语音(TTS)模型,具备多语言支持、零样本即时语音克隆、低延迟等特性。该模型拥有仅5亿参数,却能够在多种语言之间无缝切换,并提供高质量的语音合成效...语音模型# FishSpeech v1.5# TTS模型1年前04920