北京沐言智语科技开源可训练文本到语音(TTS)模型 Muyan-TTS ,专为播客场景优化,并在5万美元的预算内开发。该模型通过在超过10万小时的播客音频数据上进行预训练,能够实现高质量的零样本文本到语音合成,并且支持通过目标说话人的几十分钟语音进行说话者适应,从而实现高度定制化的语音合成。
- GitHub:https://github.com/MYZY-AI/Muyan-TTS
| 模型 | 地址 |
|---|---|
| Muyan-TTS | huggingface | modelscope | wisemodel |
| Muyan-TTS-SFT | huggingface | modelscope | wisemodel |
例如,你正在制作一个播客节目,需要将文本内容转换为自然流畅的语音。传统的TTS模型可能无法很好地处理播客中的复杂语义和情感表达,而Muyan-TTS通过其预训练的大语言模型(LLM)和优化的解码器,能够生成高质量的语音,并且可以根据特定主持人的声音进行定制,使合成语音更接近目标说话人的风格。
主要功能
- 零样本语音合成:Muyan-TTS能够在没有目标说话人大量数据的情况下,生成高质量的语音。
- 说话者适应:通过几十分钟的目标说话人语音数据,模型可以进一步优化,以更好地模仿特定说话人的声音。
- 高质量语音生成:模型在播客音频数据上进行了大量预训练,能够生成自然、流畅的语音。
- 高效推理框架:优化的推理框架使得模型在实时语音生成中表现出色,适合低延迟的应用场景。
主要特点
- 开源性:Muyan-TTS提供了完整的训练代码、数据处理流程和推理框架,确保了研究和开发社区的透明度和可访问性。
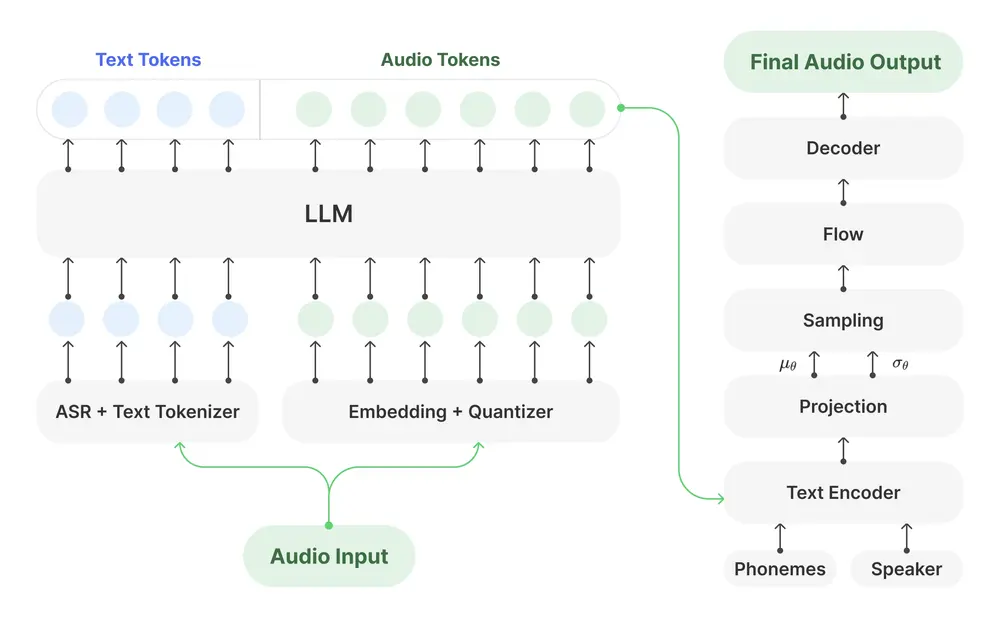
- 基于LLM的架构:模型基于Llama-3.2-3B,结合了LLM的强大语义理解能力和VITS解码器的高效性,平衡了质量和效率。
- 定制化:支持通过少量目标说话人的语音数据进行微调,以适应特定的语音风格和情感表达。
- 优化的解码器:采用VITS解码器,减少了LLM引入的幻觉问题,提高了语音合成的准确性和自然度。
工作原理
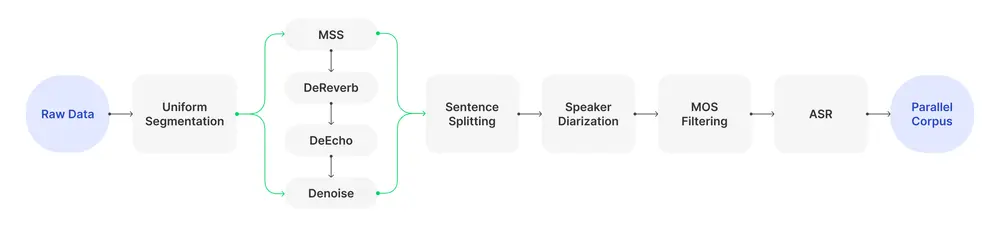
- 数据收集与处理:通过多阶段数据处理流程,从开源数据集和专有播客集合中收集超过15万小时的音频数据,经过音乐源分离、去混响、去回声和降噪等步骤,生成高质量的并行语料库。
- 预训练:在收集的并行语料库上继续预训练Llama-3.2-3B模型,将文本和音频表示对齐到统一的建模空间。
- 解码器训练:在高质量播客音频数据上微调SoVITS模型,优化语音合成的保真度和自然度。
- 推理加速:通过高效的内存管理和并行推理技术,优化LLM组件,提高实时语音生成的效率。
测试结果
- 零样本语音合成:在LibriSpeech和SEED数据集上,Muyan-TTS在词错误率(WER)、说话者相似度(SIM)和平均意见得分(MOS)等指标上表现出色,与现有的开源TTS模型相比具有竞争力。
- 说话者适应:通过监督微调(SFT)模型,Muyan-TTS在语音质量和说话者相似度上进一步提升,但WER略有下降。
- 推理速度:Muyan-TTS在所有测试模型中具有最快的推理速度,每秒合成语音的时间仅为0.33秒,适合实时应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











