
ACE Studio和阶跃星辰(StepFun)联合推出了一款全新的开源音乐生成基础模型ACE-Step,该模型通过创新的整体架构设计,突破了现有方法的局限性,实现了卓越的性能表现。
- GitHub:https://github.com/ace-step/ACE-Step
- 模型:https://huggingface.co/ACE-Step/ACE-Step-v1-3.5B
- Demo:https://huggingface.co/spaces/ACE-Step/ACE-Step
为什么 ACE-Step 如此重要?
当前的音乐生成模型面临一个核心问题:不同的方法在性能上各有优劣,但难以兼顾所有关键指标。例如:
- 基于大语言模型(LLM)的方法(如 Yue、SongGen)在歌词对齐和细节表现上表现出色,但推断速度慢,并且容易产生结构性伪影。
- 扩散模型(如 DiffRhythm)生成速度快,但在长范围结构连贯性方面存在明显短板。
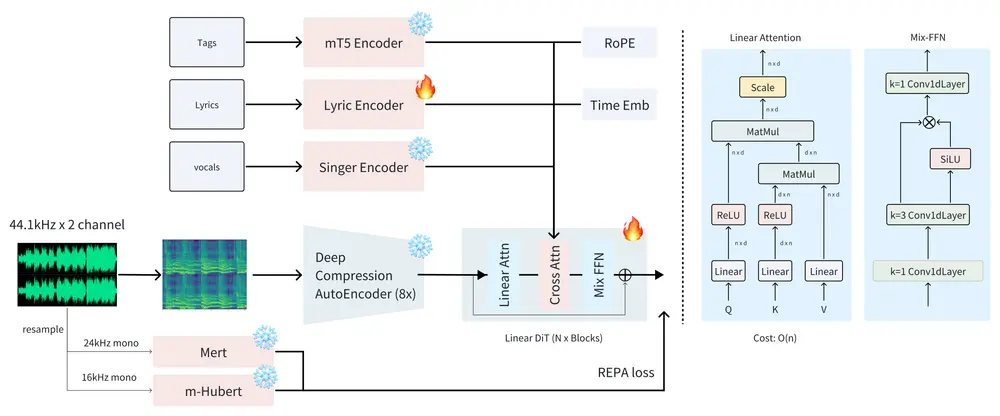
ACE-Step 通过整合基于扩散的生成、深度压缩自编码器(DCAE) 和轻量级线性变换器,成功弥合了这些差距。此外,它还利用 MERT 和 m-hubert 在训练期间对齐语义表示(REPA),实现快速收敛。最终结果是:
- 生成速度:在 A100 GPU 上,仅需 20 秒即可合成长达 4 分钟的音乐——比基于 LLM 的基线快 15 倍。
- 音乐连贯性:在旋律、和声和节奏指标上表现卓越。
- 歌词对齐:高质量的歌词与音乐同步。
- 细粒度控制:支持声音克隆、歌词编辑、混音和轨道生成等高级功能。
这种高性能、高灵活性的设计使 ACE-Step 成为音乐生成领域的“稳定扩散”时刻,为未来的音乐创作工具铺平了道路。
核心功能
基线质量
- 多样化风格与流派:支持所有主流音乐风格,兼容多种描述格式,包括短标签、描述性文本或使用场景。能够生成不同流派的音乐,配备适当的乐器和风格。
- 多语言支持:支持 19 种语言,其中表现最佳的 10 种语言包括英语、中文、俄语、西班牙语、日语、德语、法语、葡萄牙语、意大利语和韩语。由于数据不平衡,较少使用的语言可能表现不佳。
- 器乐风格:支持多种流派和风格的器乐生成,能够生成具有适当音色和表现力的真实器乐轨道,并可生成多乐器复杂编排,同时保持音乐连贯性。
- 声乐技巧:能够以高质量渲染各种声乐风格和技巧,支持不同声乐表达,包括多种演唱技巧和风格。
- 可控性:
- 变体生成:使用无需训练的推断时优化技术实现。通过流匹配模型生成初始噪声,然后使用 trigFlow 的噪声公式添加额外的正态噪声。用户可调节原始初始噪声与新正态噪声的混合比例,以控制变体程度。
- 重绘:通过为目标音频输入添加噪声并在 ODE 过程中应用掩码约束实现。当输入条件与原始生成变化时,可仅修改特定方面,同时保留其余部分。可与变体生成技术结合,创建风格、歌词或声乐的局部变体。
- 歌词编辑:创新应用流编辑技术,实现局部歌词修改,同时保留旋律、声乐和伴奏。适用于生成内容和上传音频,大幅提升创作可能性。当前限制为一次只能修改小段歌词以避免失真,但可顺序应用多次编辑。
应用场景
- Lyric2Vocal (LoRA):基于纯声乐数据微调的 LoRA,允许直接从歌词生成声乐样本。可用于声乐演示、引导轨道、歌曲创作辅助和声乐编排实验,为词曲作者提供快速测试歌词演唱效果的方法,帮助其更快迭代。
- Text2Samples (LoRA):与 Lyric2Vocal 类似,但微调于纯器乐和样本数据。可根据文本描述生成概念性音乐制作样本,用于快速创建乐器循环、音效和音乐制作元素。
- 即将推出:
- RapMachine:基于纯说唱数据微调,创建专为说唱生成的 AI 系统。预期功能包括 AI 说唱对战和通过说唱进行叙事表达,说唱具有出色的叙事和表达能力,应用潜力巨大。
- StemGen:基于多轨道数据训练的 controlnet-lora,生成单独的乐器分轨。以参考轨道和指定乐器(或乐器参考音频)为输入,输出与参考轨道互补的乐器分轨,如为长笛旋律创建钢琴伴奏或为吉他主奏添加爵士鼓。
- Singing2Accompaniment:StemGen 的逆过程,从单一声乐轨道生成混合主轨道。以声乐轨道和指定风格为输入,生成完整的声乐伴奏,为任何声乐录音轻松添加专业音效伴奏。
硬件性能
我们在不同硬件设置上评估了 ACE-Step,以下是其吞吐量结果:
| 设备 | 27 步 | 60 步 |
|---|---|---|
| NVIDIA A100 | 27.27x | 12.27x |
| NVIDIA RTX 4090 | 34.48x | 15.63x |
| NVIDIA RTX 3090 | 12.76x | 6.48x |
| MacBook M2 Max | 2.27x | 1.03x |
我们使用实时因子(RTF)测量 ACE-Step 的性能,值越高表示生成速度越快。例如,27.27x 表示生成 1 分钟音乐仅需 2.2 秒(60/27.27)。性能在单 GPU 上以批量大小 1 和 27 步测量。
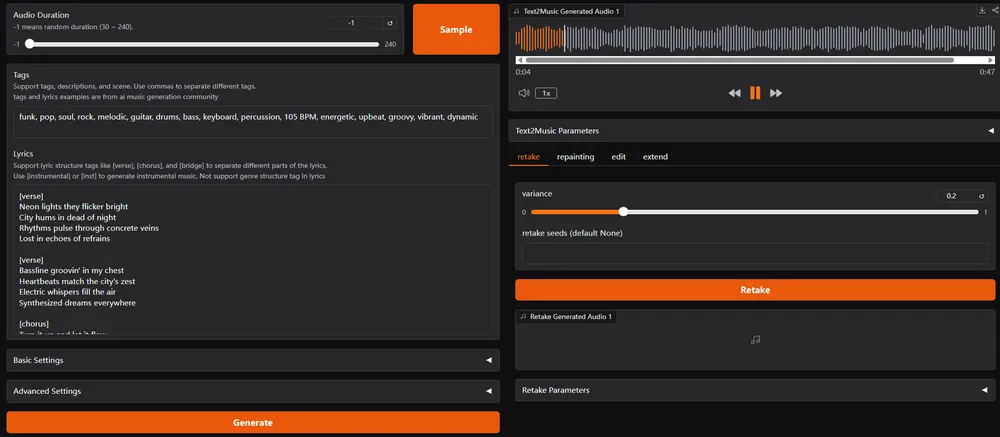
用户界面指南
ACE-Step 界面提供多个选项卡,用于不同的音乐生成和编辑任务:
Text2Music 选项卡
- 输入字段:
- 标签:输入描述性标签、流派或场景描述,以逗号分隔。
- 歌词:输入带有结构标签(如 [verse]、[chorus]、[bridge])的歌词。
- 音轨时长:设置生成的音频时长(-1 表示随机)。
- 设置:
- 基本设置:调整推断步数、引导尺度、种子。
- 高级设置:微调调度器类型、CFG 类型、ERG 设置等。
- 生成:点击“生成”按钮,根据输入创建音乐。
重拍选项卡
- 使用不同种子重新生成略有变化的音乐。
- 调整变异度以控制重拍与原始的差异程度。
重绘选项卡
- 选择性重新生成音乐的特定部分。
- 指定重绘部分的开始和结束时间。
- 选择源音频(文本到音乐输出、上次重绘或上传)。
编辑选项卡
- 通过更改标签或歌词修改现有音乐。
- 在“仅歌词”模式(保留旋律)或“混音”模式(更改旋律)之间选择。
- 调整编辑参数以控制保留原始内容的程度。
扩展选项卡
- 在现有音乐的开头或结尾添加音乐。
- 指定左侧和右侧扩展长度。
- 选择要扩展的源音频。
ACE-Step 为音乐创作带来了前所未有的灵活性和高效性,无论是音乐艺术家、制作人还是内容创作者,都能从中受益。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











