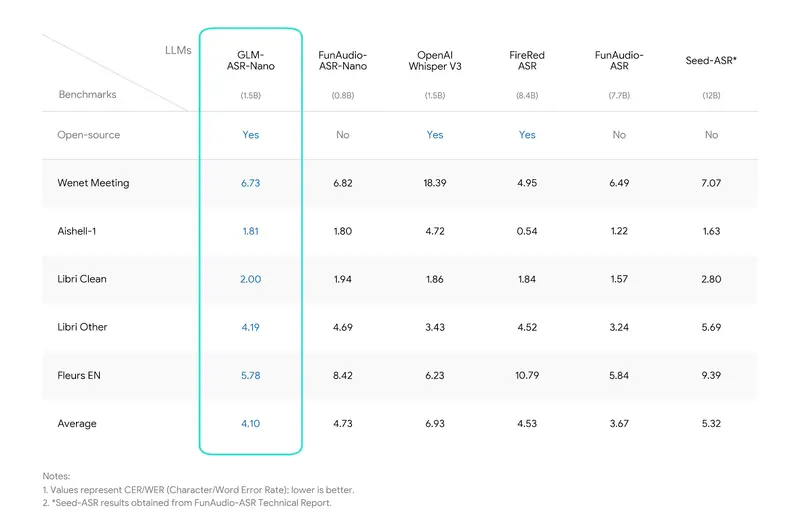
在文本转语音(TTS)领域,如何在保持高保真音质的同时,实现对韵律、情感和副语言特征(如笑声、呼吸声)的精细化控制,一直是行业难点。今日,Fish Audio 正式开源 S2 模型及其完整的生产级推理栈。
S2 不仅是一个模型权重的释放,更是一套包含数据清洗、强化学习对齐(RLHF)及基于 SGLang 的流式推理引擎的完整系统。它在 EmergentTTS-Eval 基准测试中以 81.88% 的综合胜率超越包括 Google 和 OpenAI 在内的闭源系统,位居榜首。目前已释出Fish Audio S2 Pro版本,后续应该会有Mini版本。
- GitHub:https://github.com/fishaudio/fish-speech
- 模型:https://huggingface.co/fishaudio/s2-pro
核心突破:自然语言驱动的精细化行内控制
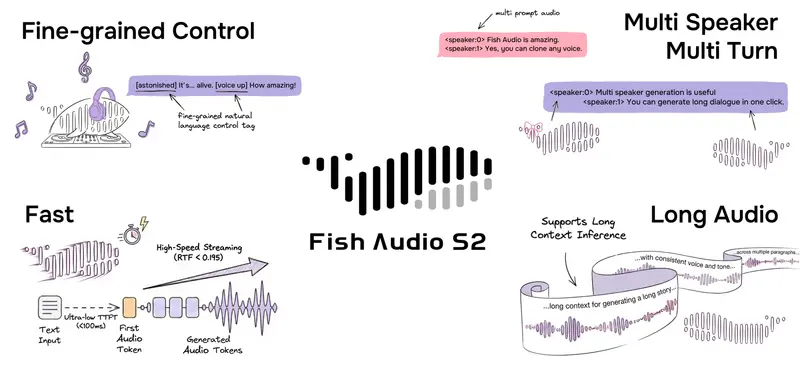
传统的 TTS 模型通常依赖有限的预定义标签或全局风格设置,难以在句子级别进行动态调整。S2 引入了革命性的自由形式自然语言指令机制。
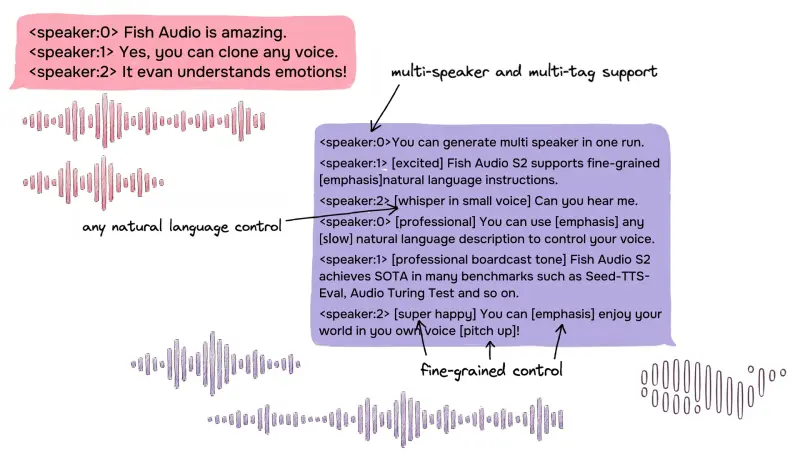
用户无需记忆复杂的标签代码,只需在文本中直接嵌入类似 [whisper in small voice](小声低语)、[professional broadcast tone](专业播音腔)或 [laughing](大笑)的自然语言描述。模型能够理解这些指令,并在单词或短语级别实时调整发音方式。
- 开放式控制:支持超过 15,000 种独特的语义标签,涵盖情绪(愤怒、惊喜)、动作(清嗓子、吸气)、语调(强调、耳语)等。
- 行内嵌入:指令直接写在文本中,例如:“你好 [whisper] 这是一个秘密 [normal] 请大声朗读 [shouting] 开始!”
- 多语言支持:原生支持 80+ 种语言,包括中文、英语、日语(第一梯队),以及韩语、西班牙语、阿拉伯语等主流语言,甚至涵盖威尔士语、巴斯克语等小语种。
架构创新:双自回归(Dual-AR)与 LLM 生态复用
S2 的成功很大程度上归功于其巧妙的架构设计,使其能够直接复用大语言模型(LLM)成熟的推理优化生态。
1. 双自回归架构(Dual-AR)
为了解决音频序列过长导致的计算爆炸问题,S2 采用了非对称的双自回归设计:
- 慢速自回归(Slow AR):拥有 40 亿参数,沿时间轴操作,负责预测主要的语义码本(Semantic Codebook),把握整体韵律和内容。
- 快速自回归(Fast AR):拥有 4 亿参数,在每个时间步并行生成剩余的 9 个残差码本,重建细粒度的声学细节。
这种设计在保证音频高保真度的同时,大幅降低了推理延迟。更重要的是,由于该架构在结构上与标准的 Decoder-only Transformer 同构,S2 能够无缝继承 SGLang 框架的所有原生优化特性。
2. 生产级流式推理
得益于 SGLang 的支持,S2 实现了企业级的推理性能:
- 连续批处理(Continuous Batching):动态调度请求,最大化 GPU 利用率。
- 分页 KV 缓存(Paged KV Cache):高效管理显存,支持长上下文。
- RadixAttention 前缀缓存:针对语音克隆场景,参考音频的 KV 状态可被自动缓存。在跨请求复用同一声音时,前缀缓存命中率高达 86.4%,使得预填充开销几乎忽略不计。
实测性能(单张 NVIDIA H200 GPU):
- 实时因子(RTF):低至 0.195(即生成 1 秒音频仅需 0.195 秒计算时间)。
- 首包延迟:约 100 毫秒,实现近乎实时的交互体验。
- 吞吐量:每秒可生成 3000+ 声学词元,且在保持 RTF < 0.5 的高负载下依然稳定。
训练策略:统一的数据与奖励流水线
S2 在架构层面解决了一个长期存在的痛点:预训练数据与后训练目标之间的分布不匹配。
许多 TTS 系统分别训练数据过滤模型和奖励模型,导致目标不一致。S2 采用“统一配方”:
- 数据清洗阶段:使用语音质量模型和富转录 ASR 模型(基于 Qwen3-Omni 持续预训练)对 1000 万小时、80+ 语言的原始数据进行评分和标注,生成带有副语言注释的增强字幕。
- 强化学习阶段:直接复用上述模型作为奖励模型(Reward Model),通过群体相对策略优化(GRPO)对模型进行对齐。
这种设计确保了模型从数据摄入到最终优化的目标高度一致,显著提升了指令遵循能力和音质表现。
性能基准:全面领先开源与闭源模型
在多项权威基准测试中,S2 展现了统治级的表现:
| 测试项目 | 指标 | Fish Audio S2 | 竞品对比 (Seed-TTS / MiniMax) |
|---|---|---|---|
| Seed-TTS Eval (WER) | 中文 | 0.54% (最佳) | 1.12% / 0.99% |
| Seed-TTS Eval (WER) | 英文 | 0.99% (最佳) | 2.25% / 1.90% |
| 音频图灵测试 | 带指令后验均值 | 0.515 | 0.417 / 0.387 |
| EmergentTTS-Eval | 综合胜率 | 81.88% | - |
| Fish Instruction Benchmark | 指令遵循率 (TAR) | 93.3% | - |
特别是在副语言控制(91.61% 胜率)和复杂语法结构处理上,S2 表现出了极强的鲁棒性,证明了其在处理真实世界复杂对话场景中的能力。
开源生态与快速上手
此次开源不仅仅是模型权重,Fish Audio 提供了完整的工具链:
- 模型权重:包含 Slow AR 和 Fast AR 全部参数。
- 微调代码:支持用户基于自有数据进行定制化训练。
- 推理引擎:基于 SGLang 构建的生产级流式推理服务。
- 交互式演示:可在 Hugging Face Space 或官方 Demo 页面直接体验。
获取方式:
开发者可通过 Fish Audio 的 GitHub 仓库、Hugging Face 模型页以及 ModelScope 获取相关资源。
# 示例:使用 SGLang 启动 S2 服务 (伪代码示意)
python -m sglang.launch_server --model-path fish-audio/s2-pro --port 30000
Fish Audio S2 的发布,标志着开源 TTS 模型在可控性和工程化落地两个维度上迈上了新台阶。通过自然语言指令实现的精细化控制,让语音合成不再是机械的朗读,而是充满情感的表达;而基于 Dual-AR 架构与 SGLang 的深度集成,则让这一高性能模型能够轻松部署于生产环境。
对于需要构建虚拟人、有声书、游戏 NPC 或智能客服的企业与开发者而言,S2 提供了一个目前看来最具竞争力的开源选择。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











