在 AI 语音合成(TTS)日益普及的今天,将其应用于专业影视制作仍面临巨大挑战:口型对不上、情感不到位、多人对话混乱、画面遮挡时声音消失……

阿里通义实验室正式宣布开源 Fun-CineForge —— 全球首个支持影视级多场景配音的多模态大模型。它不仅发布了强大的模型,还同步开源了高质量数据集 CineDub 的构建方法,旨在通过“数据 + 模型”的一体化设计,彻底解决 AI 配音在专业领域的落地瓶颈。
- 项目主页:https://funcineforge.github.io
- GitHub:https://github.com/FunAudioLLM/FunCineForge
- HuggingFace:https://huggingface.co/FunAudioLLM/Fun-CineForge
- ModelScope:https://www.modelscope.cn/models/FunAudioLLM/Fun-CineForge
影视配音的“四大严苛考验”
在真实电影制作中,一段合格的配音必须同时满足:
- 👄 口型同步:语音波形必须与人物唇部运动帧级对齐。
- 🎭 情绪表达:根据画面表情和指令,精准演绎愤怒、悲伤、喜悦等复杂情感。
- 🗣️ 音色一致:在多角色切换时,保持每个角色音色的独特性和稳定性。
- ⏱️ 时间对齐:即使说话人被遮挡或镜头切走,声音也必须在正确的时间点出现和结束。
现有通用 TTS 模型往往顾此失彼,难以同时达标。
行业两大痛点 vs. Fun-CineForge 的破局之道
痛点一:高质量多模态数据稀缺
- 现状:现有数据集规模小、标注粗糙,缺乏长视频多人对话数据,人工标注成本极高。
- Fun-CineForge 方案:自动化构建 CineDub 数据集
- 创新流程:提出了一套自动化流水线,包含人声分离、文本转录、长视频分段、音视频联合说话人分离。
- 双向矫正机制:利用大模型思维链(CoT)对转录文本和说话人分离结果进行双向校验纠错。
- 效果惊人:
- 中文字错率 (CER):4.53% ➔ 0.94%
- 英文词错率 (WER):9.35% ➔ 2.12%
- 说话人分离错误率:8.38% ➔ 1.20%
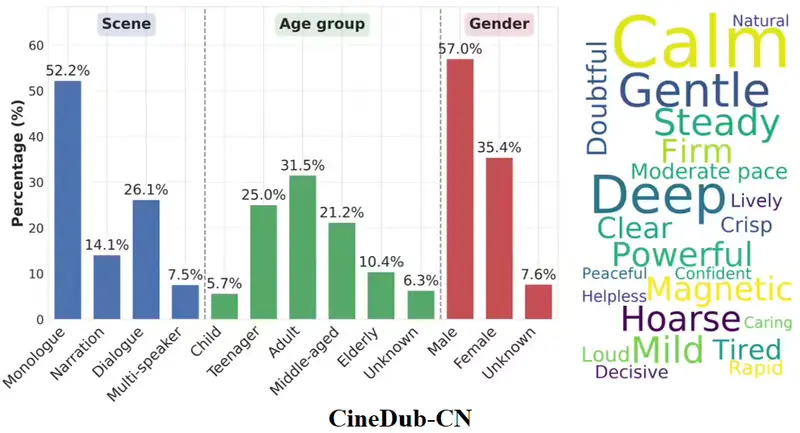
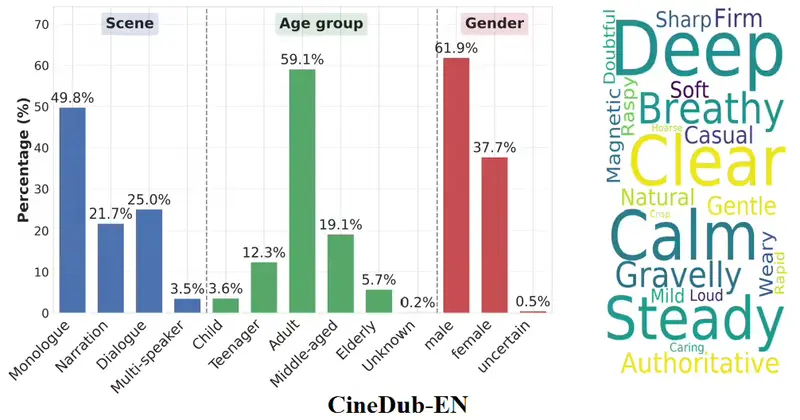
- 数据规模:基于 350+ 部中英文影视剧,覆盖独白、旁白、双人/多人对话等全场景,包含帧级唇部数据、情感线索及毫秒级时间戳。
痛点二:模型能力不足,无法应对复杂场景
- 现状:传统模型仅依赖可见唇部学习同步,一旦人脸被遮挡、模糊或镜头切换,配音即刻失效。
- Fun-CineForge 方案:首创“时间模态” + 四模态融合
- 🌟 核心创新:引入“时间模态” (Time Modality)
- 传统模型只看“说什么”和“长什么样”,Fun-CineForge 额外学会了**“什么时候说”**。
- 即使画面中看不到说话人(如背影、遮挡、空镜),模型也能依据时间戳强监督,在正确区间生成语音,实现完美的时间对齐。
- 四模态深度融合:
- 视觉模态:学习唇动与表情。
- 文本模态:理解台词、角色属性与情感指令。
- 音频模态:作为预测目标,学习音色与韵律。
- 时间模态:控制语音起止与说话人轮次。
- 基座强大:基于 CosyVoice3 构建,具备卓越的语音合成底层能力。
- 🌟 核心创新:引入“时间模态” (Time Modality)
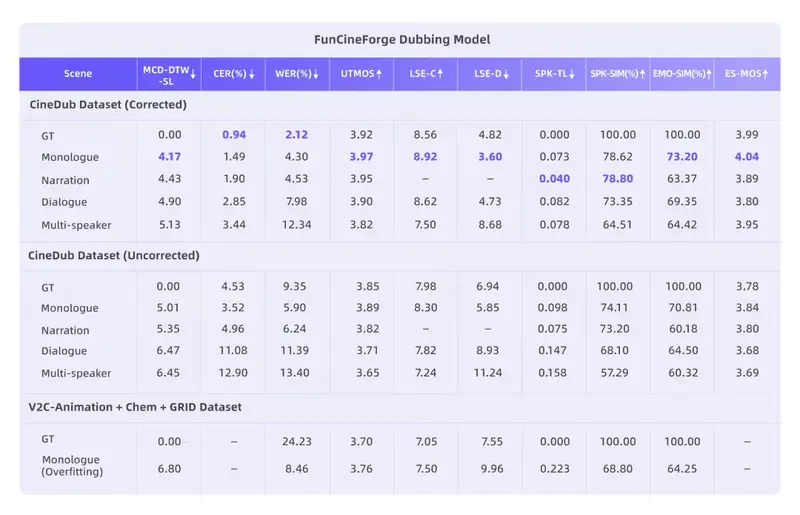
实测表现:全面超越开源基线
在自建 CineDub 数据集上的评估显示,Fun-CineForge 在各项关键指标上均优于 DeepDubber-V1、InstructDubber 等现有模型:
| 指标 | 表现 | 说明 |
|---|---|---|
| 字/词错率 | 极低 | 独白场景 CER 仅 1.49%,旁白 1.90% |
| 唇形同步 | 精准 | LSE-C/D 指标显著领先,口型自然逼真 |
| 时间对齐 | 毫秒级 | 即使在镜头切换和遮挡场景下,语音起止依然精准 |
| 音色相似度 | 高保真 | 多角色切换时音色稳定,克隆效果好 |
| 情感表达 | 拟人化 | 能精准执行“愤怒”、“哭泣”等复杂情感指令 |
| 场景覆盖 | 最广 | 首次支持稳定的双人及多人对话场景 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...