
ComfyUI-See-through 是一个将 See-through 算法集成到 ComfyUI 的实用插件。它的主要功能是输入一张静态动漫角色插画,自动将其分解为多个语义图层(如头发、五官、衣物等),补全被遮挡的区域,并按正确的前后顺序导出为 PSD 文件。
- GitHub:https://github.com/jtydhr88/ComfyUI-See-through
生成的素材可以直接导入 Live2D Cubism 进行骨骼绑定,或者用于制作简单的视差动画,从而省去了人工手动抠图和补全背景的繁琐步骤。
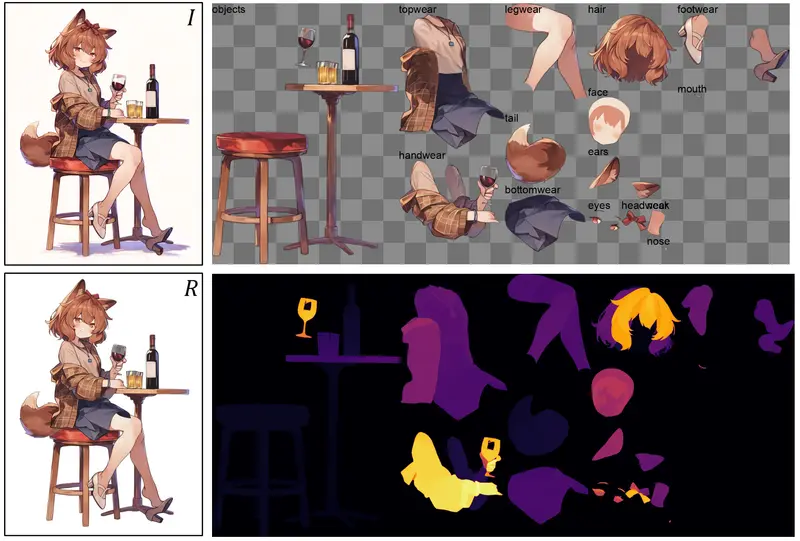
核心功能
1. 自动语义分层
基于 LayerDiff (SDXL) 模型,插件能识别并分离出约 24 个 常见部位:
- 头发:自动区分前发和后发。
- 五官:独立提取眼睛(含虹膜/眼白/睫毛)、眉毛、嘴巴、鼻子、耳朵。
- 身体与服饰:分离面部、颈部、上衣、下装、手套、鞋子等。
- 透明补全:利用生成式 AI 补全被遮挡的部分(例如被刘海遮住的眼睛),输出完整的独立图层。
2. 深度排序与智能拆分
集成 Marigold 深度估计模型 来处理图层关系:
- 自动排序:根据计算出的深度信息,自动排列图层的上下顺序(Z-order)。
- 智能拆分:
- 前后拆分:将长发等连续物体根据深度拆分为前、后多层。
- 左右拆分:自动将眼睛、耳朵、手套等对称部位拆分为左/右独立图层,方便后续做表情变形。
3. 一键导出 PSD
- 浏览器端生成:利用
ag-psd库在前端直接生成 PSD 文件,无需服务器端额外处理。 - 标准格式:导出的 PSD 包含图层名称、位置、透明度信息,可在 Photoshop 或 Live2D Cubism 中直接打开编辑。
- 深度通道:可选导出包含深度信息的 PSD,用于后期视差效果制作。
4. 轻量化部署
- 自动下载模型:首次运行时自动从 HuggingFace 下载所需模型。
- 依赖简单:仅需
diffusers,accelerate,opencv-python,scikit-learn四个常用库。
安装与使用
安装步骤
- 克隆仓库:
cd ComfyUI/custom_nodes git clone https://github.com/dmMaze/ComfyUI-See-through.git - 安装依赖:
cd ComfyUI-See-through pip install -r requirements.txt - 重启 ComfyUI:重启后节点将出现在
SeeThrough分类下。
基本工作流
- 加载模型:添加
SeeThrough Load LayerDiff Model和SeeThrough Load Depth Model节点。 - 执行分解:添加
SeeThrough Decompose节点,连接图片输入和两个模型。resolution: 设置处理分辨率(默认 1280)。tblr_split: 开启后可拆分左右对称部位。
- 导出文件:连接
SeeThrough Save PSD节点,运行完成后点击节点上的 "Download PSD" 按钮下载文件。 - 预览:连接
Preview Image查看合成效果。
预设工作流
插件内置了三个 JSON 工作流(位于 workflows/ 目录):
seethrough-basic.json: 推荐。1280 分辨率,30 步,包含左右拆分,平衡速度与质量。seethrough-highres.json: 2048 分辨率,50 步,适合需要更高细节的场景。seethrough-fast.json: 1024 分辨率,15 步,不含左右拆分,适合快速测试。
输出内容
生成的 PSD 文件通常包含以下命名规范的图层(视图片内容而定):
- 头部:
hair_front,hair_back,face,eye_L/R,eyebrow_L/R,mouth,nose,ear_L/R等。 - 身体:
neck,top_clothes,glove_L/R,bottom_clothes,shoes等。 - 其他:
tail,wings,head_accessory等。
所有图层均带有 Alpha 通道,并已按深度顺序排列。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











