
在虚拟主播(VTuber)、游戏开发和视觉小说制作中,将静态插画转化为可互动的 Live2D 模型 是标准流程。然而,传统制作极其耗时:画师需要手动将图片切割成数十个图层,凭想象“脑补”被头发遮挡的脸部或被衣服遮住的身体,并 painstakingly 排列前后顺序。
- GitHub:https://github.com/shitagaki-lab/see-through
- Demo:https://huggingface.co/spaces/24yearsold/see-through-demo
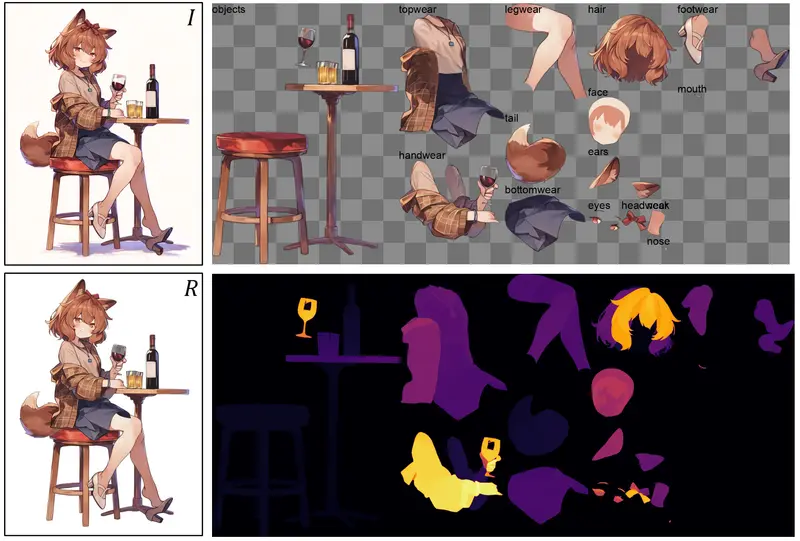
由 圣弗朗西斯大学、宾夕法尼亚大学、Spellbrush 及 Shitagaki 实验室 联合推出的 See-through 框架,彻底颠覆了这一工作流。它仅需 一张静态动漫插画,即可自动分解出 最多 23 个 语义清晰、遮挡区域已自动补全、前后层次排序正确的独立图层,直接生成可用于专业动画制作的 2.5D 模型。
核心突破:从“分割”到“透视重构”
现有的 AI 分割工具(如 SAM)只能切割可见部分,无法处理遮挡。See-through 的核心在于 “看穿” 能力:
- 真正的透视补全 (Inpainting)
- 不仅能抠出头发,还能自动画出被头发遮住的眼睛和脸型。
- 不仅能分离衣服,还能补全被衣服遮挡的躯干和四肢。
- 每个图层都是完整且独立的,无需人工修图。
- 复杂穿插处理
- 完美解决动漫中常见的发丝交错、刘海与脸部穿插、围巾与衣服层叠等复杂逻辑。
- 自动将同一物体(如长发)根据前后关系拆分为多个子图层。
- 智能深度排序
- 基于像素级伪深度推断,自动计算 19-23 个图层 的正确前后顺序(Z-order)。
- 无需人工调整,直接导出即可导入 Live2D Cubism 进行绑定。
- 全局一致性
- 独有的 身体部位一致性模块 确保所有图层拼合后,与原图在像素级完全一致,无色差、无错位、无缺失。
技术原理:如何做到“看穿”?
See-through 的成功源于其巧妙的数据构建与两阶段训练策略:
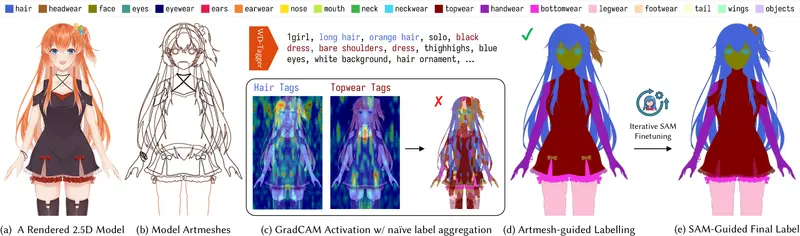
1. 数据引擎:从 Live2D 逆向挖掘
由于缺乏“单图 + 完整分层”的训练数据,团队构建了一个可扩展引擎:
- 来源:从商业级 Live2D 模型中提取源文件。
- 标注:自动将碎片映射到 19 个标准身体部位(头发前/后、眼睛、眉毛、脸、鼻子、嘴、衣服、手臂等)。
- 真值生成:利用 Live2D 源文件的天然分层特性,生成包含遮挡区域的完美 Ground Truth 数据。
2. 两阶段扩散模型
- 阶段一:语义提取
训练扩散模型学会从单图中精准提取每个部位的掩码(Mask)和纹理,同时预测透明区域。 - 阶段二:全局一致性优化
引入 Body-Part Consistency Module,强制所有提取的图层在重组时必须完美还原原图。这防止了模型“幻觉”出错误的细节或丢失特征。
3. 深度与补全
- 利用 像素级伪深度推断 机制,为每个像素分配深度值,解决复杂的遮挡排序。
- 结合修复(Inpainting)技术,根据上下文逻辑“画”出被遮挡的部分。
实测表现:专业画师认可的“生产级”工具
在与主流模型(如 SAM, Qwen-Image-Layered)的对比中,See-through 展现了压倒性优势:
| 维度 | 传统 AI 分割 | See-through |
|---|---|---|
| 遮挡处理 | ❌ 仅分割可见部分,遮挡处透明 | ✅ 自动补全遮挡区域,图层完整 |
| 复杂穿插 | ❌ 容易将前后发丝合并 | ✅ 精准拆分交错发丝与衣物 |
| 图层数量 | 少且粗糙 | 19-23 层,语义精细 |
| 一致性 | 拼合后有色差或缺失 | 像素级完美还原原图 |
| 可用性 | 需大量人工修整 | 接近生产可用,画师仅需微调 |
用户反馈:6 位专业动漫画师测试后评价,See-through 输出的文件“几乎可以直接用于生产”,将原本需要数小时甚至数天的分层工作缩短至几分钟。
应用场景
- VTuber 快速出道:只需一张立绘,几分钟内生成 Live2D 素材,大幅降低虚拟主播制作门槛。
- 游戏开发:快速将概念图或宣传图转化为游戏内的动态角色资源。
- 视觉小说 (Visual Novel):让静态 CG 中的角色眨眼、微笑、转头,增强演出效果。
- 辅助创作:画师可利用其快速分层功能,方便地对角色的特定部位(如只改衣服颜色、只换发型)进行修改和二创。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











