
Flex.2-preview 是一款开源的文本到图像扩散模型,具有 80 亿参数,支持通用控制和图像修复功能。它基于 Flux.1 Schnell 微调而成,旨在为用户提供更灵活、更强大的图像生成能力。
- 地址:https://huggingface.co/ostris/Flex.2-preview
- Demo:https://huggingface.co/spaces/ostris/Flex.1-alpha

特性
- 80 亿参数:模型具有强大的生成能力,能够生成高质量的图像。
- 指导嵌入器:生成速度比传统方法快 2 倍,提升效率。
- 内置图像修复:支持图像修复功能,可以直接在模型中使用。
- 通用控制输入:支持线条、姿势、深度等通用控制输入,增强生成图像的多样性和准确性。
- 可微调:模型支持微调,用户可以根据自己的需求进行定制。
- 符合 OSI 标准的许可:采用 Apache 2.0 许可,用户可以自由使用和修改。
- 512 token 长度输入:支持较长的文本输入,提供更丰富的描述能力。
- 16 通道潜在空间:提供更复杂的图像生成能力。
- 社区驱动:由社区创建,为了社区,所有工具和模型都是免费和开放的。
开发历程
Flex.2 的开发历程经历了多个阶段,从 Flux.1 Schnell 到 OpenFlux.1,再到 Flex.1-alpha,最终推出了 Flex.2-preview。每一步都进行了无数改进,而 Flex.2 是迄今为止最大的一步。它由一位完全依赖社区支持的开发者训练,旨在通过社区的力量维持开发和训练所需的高昂计算成本。
使用方法
ComfyUI
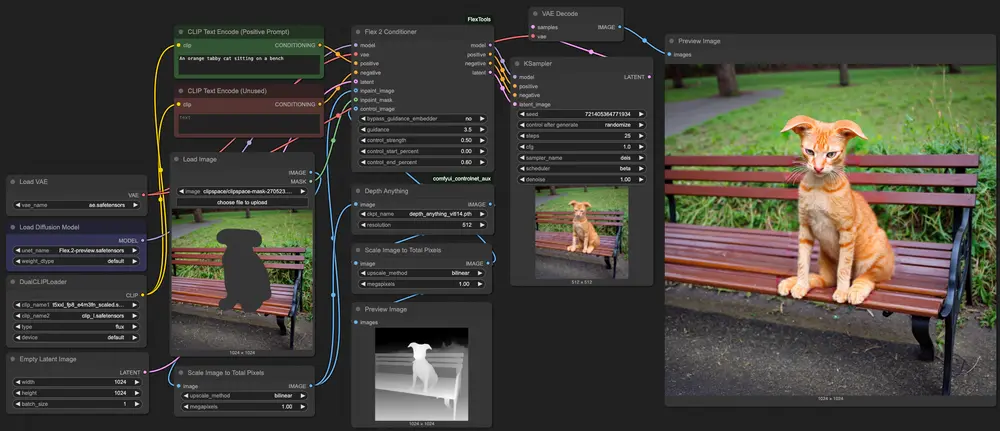
Flex.2 在 ComfyUI 中受到支持,通过 ComfyUI-FlexTools 提供的 Flex2 Conditioner 节点实现。建议使用 comfyui_controlnet_aux 来生成控制图像(姿势和深度)。
- 安装模型:
- 按照 ComfyUI 示例中的说明,安装 flux 的 vae 和文本编码器模型。
- 将
Flex.2-preview.safetensors下载到ComfyUI/models/diffusion_models/Flex.2-preview.safetensors。 - 重启 ComfyUI。
- 使用示例工作流程:
- 使用提供的工作流程作为控制和图像修复的入门示例。
局限性
Flex.2-preview 仍处于实验阶段,正在积极开发中。当前版本存在一些局限性:
- 解剖结构和文本问题:模型在解剖结构和文本生成方面存在一些问题。
- 图像修复功能仍在开发中:图像修复功能仍在完善中,可能存在一些不稳定的情况。
微调
Flex.2 被设计为可微调的,尽管最佳实践仍在探索中。用户可以直接在模型上训练传统的 LoRA,Flex.1-alpha 的 LoRA 也与之兼容。AI-Toolkit 提供了 LoRA 训练支持,用户可以参考示例配置文件 train_lora_flex2_24gb.yaml 进行微调。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











