在 AI 辅助编程领域,有一个长期存在的痛点:当任务变得非常复杂、步骤多达数百步时,AI 往往会因为“记不住”前面的内容而迷失方向,或者因为上下文太长导致成本高昂、响应变慢。
- 官方介绍:https://cursor.com/cn/blog/self-summarization
为了解决这个问题,Cursor推出了专为代理编码(Agentic Coding)打造的全新 AI 模型——Composer。这款模型的核心突破在于它学会了一项新技能:自我总结。
核心突破:像人类一样“记笔记”
传统的 AI 模型在处理长任务时,通常依赖冗长的提示词(Prompt)来强行塞入更多上下文,或者简单地截断旧信息,这往往导致关键逻辑丢失。
Composer 则不同。它通过一种名为强化学习(Reinforcement Learning)的训练过程,学会了在运行过程中主动对过去的信息进行“自我总结”:
- 自动提炼:在任务进行中,Composer 会实时判断哪些信息是关键的,哪些是冗余的,并自动生成简短的总结。
- 压缩上下文:通过这些自我生成的总结(平均仅需约 1000 Token),模型能够将原本漫长的对话历史压缩成精炼的“笔记”,既保留了核心逻辑,又腾出了宝贵的上下文空间。
- 持续推理:这使得 Composer 能够在远超传统上下文窗口限制的序列中,保持连贯的推理能力,轻松应对需要数百个步骤的复杂编程挑战。
简单来说:以前的 AI 像是“过目就忘”或者“死记硬背”,而 Composer 学会了像资深程序员一样,边写代码边记“开发日志”,确保走到第 100 步时,依然清楚第 1 步的目标是什么。
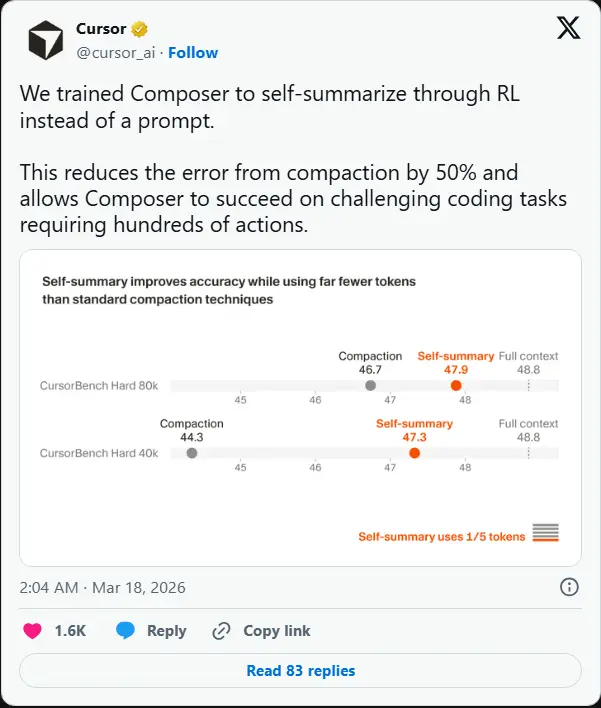
性能实测:更准、更快、更省
目前,Composer 正在通过 CursorBench 和 Terminal-Bench 2.0 进行严格的内部评估。初步数据显示,相比现有的基于提示词的压缩方法,Composer 表现优异:
| 指标 | 传统方法 | Composer (自我总结) | 优势 |
|---|---|---|---|
| 上下文保留 | 容易丢失关键细节 | 高度精准,关键信息不丢失 | 逻辑更连贯 |
| Token 消耗 | 随任务长度线性激增 | 显著降低,平均总结仅占 1000 Token | 成本更低,速度更快 |
| 依赖程度 | 依赖人工编写冗长提示 | 自主学习,无需手工干预 | 使用更简单 |
早期测试中,Composer 成功解决了一些曾让其他大型模型“卡壳”的复杂问题,证明了其在处理多步骤、高难度编程任务上的巨大潜力。
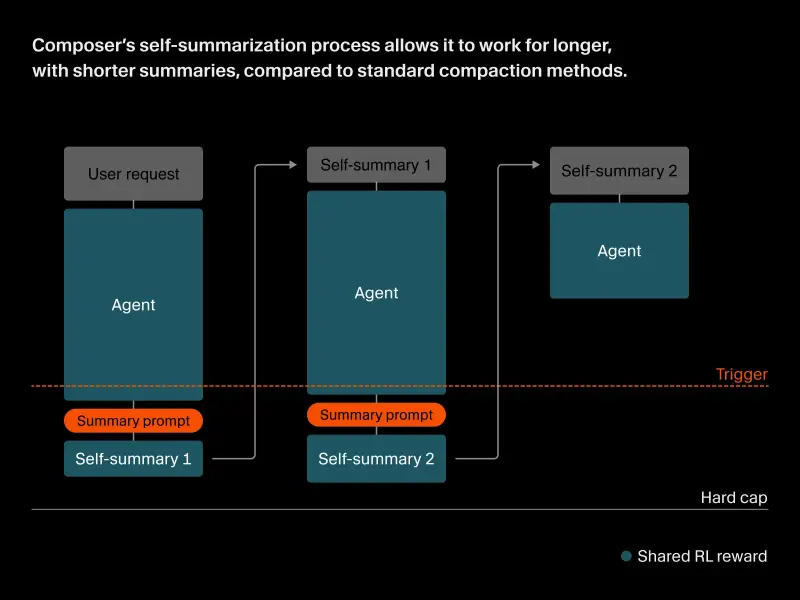
技术原理:将压缩融入训练循环
Cursor 团队的做法并非简单地给模型加一个“总结插件”,而是将压缩能力直接整合到了模型的训练循环中。
- 强化学习奖励机制:在训练过程中,如果模型生成的总结既短小又能帮助后续任务成功完成,它就会获得奖励;反之,如果总结丢失了关键信息导致任务失败,则会受到惩罚。
- 学习“什么最重要”:通过这种机制,Composer 逐渐学会了识别代码上下文中哪些变量、函数定义或逻辑判断是必须保留的“黄金信息”,哪些是可以舍弃的临时状态。
- 替代手工提示:这彻底改变了以往依赖工程师手工编写复杂提示词来管理上下文的局面,让 AI 真正具备了自主管理记忆的能力。
未来展望:重新定义代理编码
Composer 的推出,标志着 Cursor 在代理 AI(Agentic AI)领域迈出了坚实的一步。
对于开发者和研究人员而言,这意味着:
- 更复杂的任务:你可以放心地让 AI 去重构整个项目、迁移大型代码库或开发全栈应用,不用担心它做到一半就“失忆”。
- 更低的成本:高效的上下文压缩意味着更少的 Token 消耗,直接降低了使用成本。
- 更流畅的体验:无需再绞尽脑汁设计复杂的提示词来维持上下文,只需下达指令,剩下的交给 Composer 自己去规划和记录。
随着未来版本的迭代,Composer 有望处理更加棘手的多步骤编程挑战,成为开发者身边真正靠谱的“超级搭档”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...