你是否曾有过这样的经历:想让AI画一组连环画,比如“一只狐狸在森林、舞台、海边、卧室弹吉他”,结果AI生成的四张图里,狐狸变成了四种不同的动物,吉他变了样,画风也从油画突变成了水彩?
这就是AI绘画领域长期存在的“一致性图像生成”难题。现有的主流模型擅长单图创作,却难以在多张图中保持身份(长得一样)、风格(画风统一)和逻辑(叙事连贯)的高度一致。其根源在于缺乏配套的标注数据、人类审美难以量化定义,以及传统训练方法算力成本过高。
- 项目主页:https://x-gengroup.github.io/HomePage_PaCo-RL/
- GitHub:https://github.com/X-GenGroup/PaCo-RL
- 模型:https://huggingface.co/collections/X-GenGroup/paco-rl
近日,来自西安交通大学与新加坡 A*STAR的研究团队提出了突破性解决方案——PaCo-RL。该框架引入强化学习理念,通过独创的“一致性裁判”机制,让AI在“试错”中自动学会如何保持多图像的一致性,无需海量标注数据,即可实现媲美商用模型的生成效果。
🎨 核心能力:从单图到连贯叙事
PaCo-RL 主要赋能两大应用场景,彻底解决“多图崩坏”问题:
1. 精准图像编辑 (Image Editing)
在修改图片局部时,严格保持其他元素不变。
- 示例:输入一张人物照,指令“让他看起来更强壮”。
- 效果:AI不仅增加了肌肉,还确保了人物面部特征、背景环境、光影风格完全一致,仿佛只是给同一个人换了个造型,而非重画了一张图。
2. 文本到图像集生成 (Text-to-ImageSet)
根据一段描述,直接生成一组风格统一的配套图片。
- 示例:指令“设计四个健康饮料标签,都用蜂蜜滴落的字体风格”。
- 效果:AI生成四张标签,虽然文字内容分别为“能量”、“天然”等,但字体设计、配色方案、插画风格高度统一,宛如出自同一位设计师之手。
三大一致性支柱:
- 👤 身份一致性:跨图片的角色长相、服饰细节完全锁定。
- 🎨 风格一致性:整体色调、笔触质感、艺术风格无缝衔接。
- 📖 逻辑一致性:图片间呈现清晰的叙事演变(如叶子从绿变黄再腐烂)。
💡 三大技术创新:更懂行、更省钱、更平衡
相比现有方案,PaCo-RL 引入了三项颠覆性设计:
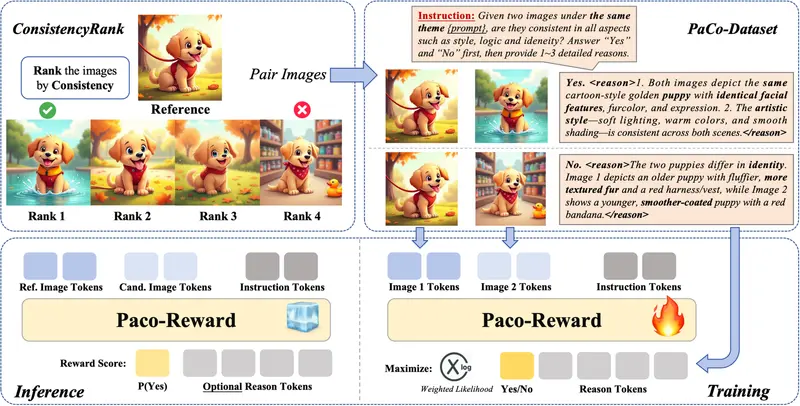
1. 专属“一致性裁判” (PaCo-Reward)
传统AI只判断“图好不好看”或“符不符合提示词”,而 PaCo-RL 专门训练了一个多模态大模型裁判。
- 职责:它的唯一任务就是比较两张图是否“配套”。
- 能力:基于大量“配套/不配套”数据对微调(基于 Qwen2.5-VL),它能像人类专家一样指出:“这两只狐狸颜色一样,但体型差异太大,所以不一致。”
- 效果:实验显示,其评判准确度比通用大模型高出 10% 以上,与人类专家的相关性极高。
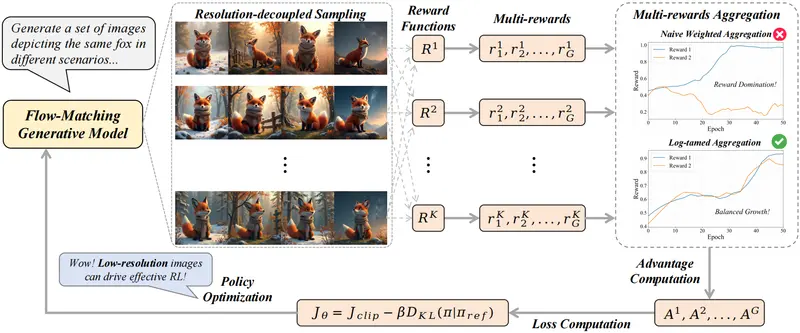
2. 分辨率解耦:小图训练,大图生成
这是极具工程智慧的优化。
- 痛点:用高清大图进行强化学习训练,显存消耗巨大,成本高昂。
- 创新:PaCo-RL 发现,裁判只需看半尺寸小图即可判断一致性。因此,训练时使用 $512 \times 512$ 分辨率,推理生成时直接输出 $1024 \times 1024$ 高清大图。
- 收益:训练时间缩短近 50%,且最终生成质量毫无损失。就像学画画先用草稿练构图,熟练后再画正稿。
3. 对数驯化:聪明的多目标平衡术
训练时需同时兼顾“一致性”、“美观度”和“提示词遵循度”。若某一项(如一致性)信号过强,AI容易“偏科”作弊(例如生成四张完全一样的图来刷高分)。
- 机制:PaCo-RL 引入对数压缩算法,自动抑制波动过大、信号过强的奖励项,提升微弱信号的影响力。
- 效果:防止模型“走火入魔”,确保三个维度齐头并进,生成既一致又多变的优质图像。
⚙️ 工作原理:两步走的强化学习闭环
PaCo-RL 的训练过程模拟了“教练带徒弟”的模式:
第一阶段:培养裁判
研究团队自动构建大规模数据集,将同一描述生成的图片(亲兄弟)与不同描述生成的图片(陌生人)混合配对,邀请人类标注“是否配套”。以此微调 Qwen2.5-VL 模型,使其具备**“看图找茬”和“写出理由”**的能力,成为公正的 PaCo-Reward 裁判。
第二阶段:训练画家 (RL Loop)
- 出题:给生成模型(画家)一个复杂指令(如“画四只狐狸在不同场景弹吉他”)。
- 作画:画家生成一组四张图。
- 多维评判:
- 一致性裁判:随机抽取两张对比,打分“是否配套”。
- 通用裁判 (CLIP):打分“画质如何”、“是否符合描述”。
- 反馈与修正:综合所有得分,通过强化学习算法(PPO/GRPO变体)更新画家参数。
- 迭代:重复成千上万次,画家逐渐掌握“既要各自精彩,又要整体统一”的高超技艺。
📊 测试结果:全面超越 SOTA
论文在多个权威基准测试中取得了显著成果:
| 测试维度 | 指标/基准 | PaCo-RL 表现 | 对比优势 |
|---|---|---|---|
| 裁判准确性 | ConsistencyRank | 44.9% | 比 Qwen2.5-VL (34.4%) 和 CLIP (39.4%) 高出 10%+ |
| 编辑能力 | EditReward-Bench | 0.751 | 超越所有开源模型,接近 GPT-5 (0.755) |
| 生成一致性 | T2IS-Bench | +11.7% | 视觉一致性得分比最强开源 Baseline 高出近 12%,逼近 GPT-4 |
| 编辑综合分 | GEdit-Bench | 7.799 / 8.053 | 一致性与提示词遵循度双重提升,实现“既要又要” |
| 训练效率 | 时间成本 | 6小时 | 相比传统方法 (12小时) 效率翻倍,且效果更好 |
可视化进步轨迹:
在生成“四个阶段的厨师表情包”任务中,初期模型生成的厨师发型、肤色各异;中期开始趋同但细节粗糙;后期则完美实现了同一人物在不同动作下的风格统一,证明了 PaCo-RL 强大的学习能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...