Inception是一家在加州帕洛阿尔托成立的新创公司,由斯坦福大学计算机科学教授 Stefano Ermon 创立。Inception 宣布开发出一种基于“扩散(diffusion)”技术的新型LLM(大语言模型),声称在性能和成本上都取得了重大突破。

背景:传统 LLM 与扩散模型的区别
目前,生成式 AI 模型主要分为两类:
- 大语言模型(LLM) :如 GPT、Llama 等,主要用于文本生成,基于Transformer,是自回归逻辑。
- 扩散模型(Diffusion Models) :如 Midjourney 和 OpenAI 的 Sora,专注于图像、视频和音频生成,而结合Transformer的扩散模型叫DiT,利用Transformer的机制来生成图片或视频。
传统 LLM 是自回归的,逐个 token 生成文本,这种顺序生成方式限制了速度和效率。而扩散模型通过“粗到细”的生成过程,从噪声中逐步提炼输出,能够并行处理数据,显著提升生成速度和质量。
Inception 的创新:将扩散技术应用于文本
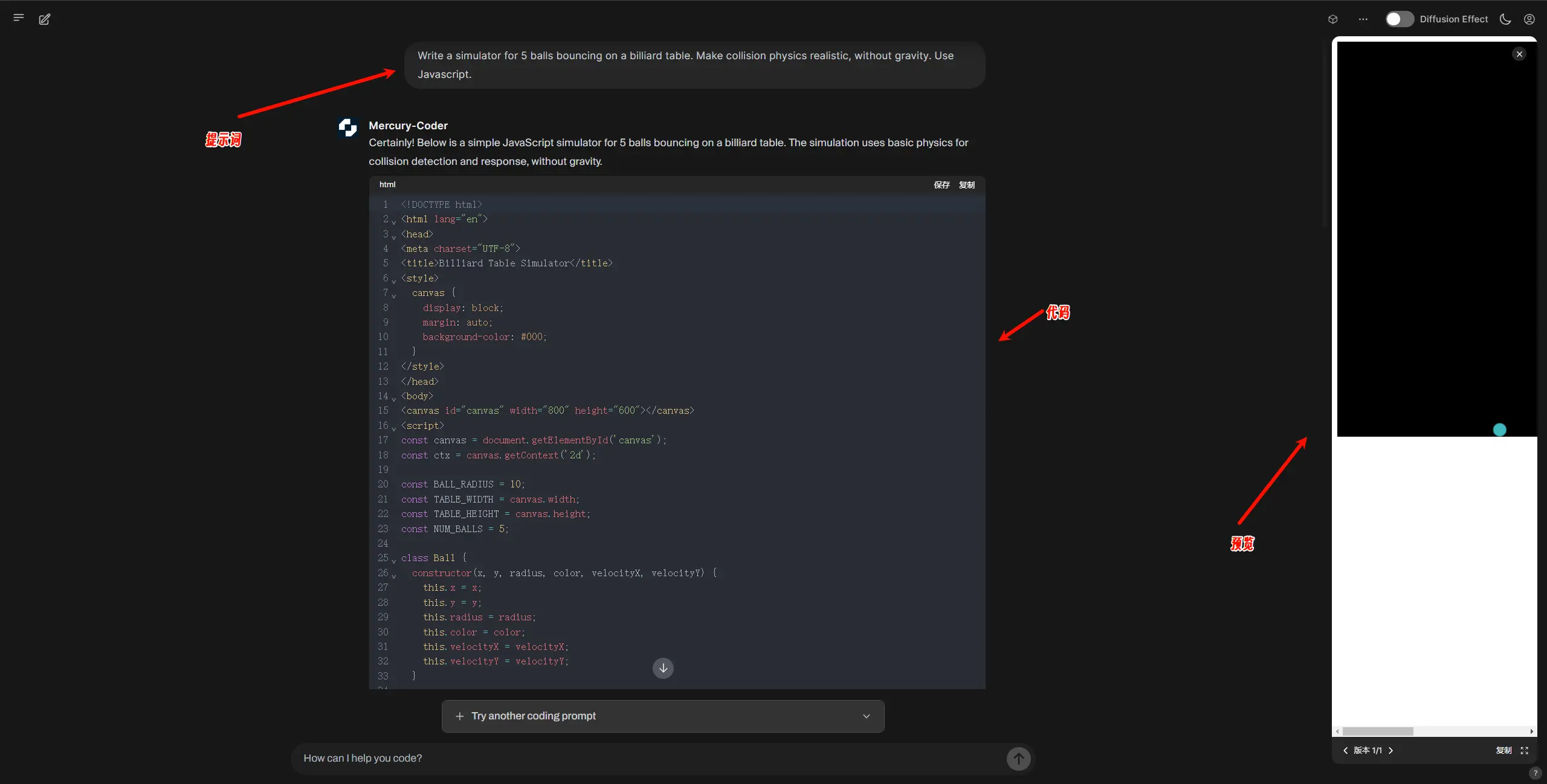
经过多年的尝试,Ermon 和他的团队在去年发表的研究论文中详细介绍了这一技术突破。他们成功将扩散模型应用于文本生成,开发出 Mercury 系列扩散大语言模型(dLLM),并推出了首个商业化的模型——Mercury Coder。
Mercury Coder 的优势
1. 性能提升
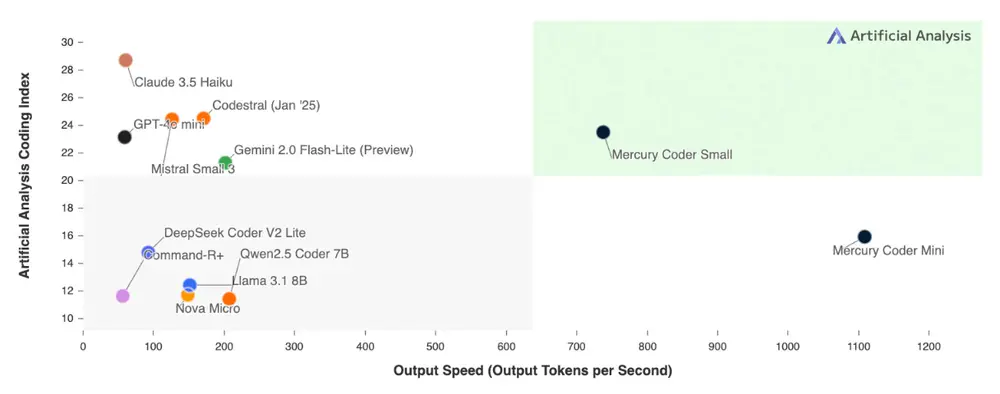
- 速度 :Mercury Coder 比现有 LLM 快 5-10 倍 ,在英伟达H100 上以超过 1000 tokens/秒 的速度运行。相比之下,许多前沿 LLM 的速度仅为每秒几十到几百个 tokens。
- 成本 :计算成本降低 10 倍 ,使得高质量 AI 解决方案更易于普及。
2. 技术优势
- 粗到细生成 :Mercury 不是逐个 token 生成,而是通过多步去噪过程并行生成和修改文本,从而大幅提升效率。
- 纠错能力 :扩散模型可以不断优化输出,纠正错误和幻觉问题,提供更可靠的响应。
- 可控生成 :用户可以指定生成顺序或格式,使输出更加灵活且符合需求。
3. 应用场景
- 代码生成:Mercury Coder 是专为代码生成优化的 dLLM,在标准编码基准测试中表现优异,甚至超越了 GPT-4o Mini 和 Claude 3.5 Haiku 等速度优化模型,同时速度快 10 倍 。
- 聊天应用 :专为聊天设计的模型正在进行封闭测试,未来将进一步拓展应用场景。
产品功能与部署选项
Inception 提供多种访问方式,满足不同企业的需求:
- API 调用 :开发者可通过 API 集成 Mercury 模型。
- 本地部署 :支持本地和边缘设备部署,适合对延迟敏感的应用。
- 微调支持 :兼容现有硬件、数据集和微调管道,包括监督微调(SFT)和对齐(RLHF)。
未来展望
Mercury 系列的推出不仅提升了生成式 AI 的速度和效率,还解锁了一系列新功能:
- 改进的代理应用 :dLLM 的高效性能使其非常适合需要大量规划和长时间生成的代理任务。
- 高级推理 :通过纠错机制,dLLM 可以修复幻觉并优化答案,同时保持快速响应。
- 边缘部署 :由于其高效性,dLLM 在手机、笔记本电脑等资源受限的环境中表现出色。
- 用户体验提升 :早期采用者报告称,Mercury 模型显著降低了延迟,同时提高了生成质量。
创始团队
Inception 的创始团队由三位顶尖学者组成:
- Stefano Ermon :斯坦福大学教授,主导扩散模型的研究。
- Aditya Grover :加州大学洛杉矶分校教授。
- Volodymyr Kuleshov :康奈尔大学教授。