英伟达在前段时间推出Cosmos 平台,该平台包含先进的世界基础生成模型、高级分词器、防护栏和加速视频处理管道,旨在推动自动驾驶汽车(AV)和机器人等物理 AI 系统的发展。虽然被称为“世界模型”,但实际上它现阶段就完全是个视频生成模型,目前ComfyUI已经宣布原生支持该模型(7B 和 14B 两个版本),你需要将ComfyUI升级到最新版(3.12版)。(相关:英伟达推出世界基础模型平台NVIDIA Cosmos :帮助物理 AI 开发人员更好、更快地构建物理 AI 系统)
推荐模型与硬件要求
Cosmos拥有7B 和 14B 两个版本的文生视频和图生视频模型,对于大多数用户来说,推荐使用7B模型。这款模型可以在拥有24GB显存的显卡上以全16位精度运行而无需卸载数据,同样也能够在12GB显存的显卡上通过ComfyUI提供的自动模型卸载功能来运行。
新采样器
此次更新还引入了一个新的采样器——res_multistep,该采样器已集成在你常用的采样器节点中。这是英伟达在其Cosmos实现中采用的采样方法,可以与ComfyUI支持的所有模型兼容,并且据说在其他视频模型上也有出色的表现。
性能优势
- 高效的 VAE:其 VAE 是目前计算/内存效率最高的视频 VAE。非常高效,你可以在 12GB 显存的显卡上编码/解码 1280x704 的 121 帧视频,而无需任何分块技巧,同时保持非常高的质量。这使得它的内存效率比混元视频模型 VAE 高出约 50 倍。
- 非蒸馏模型:负向提示词将起作用,并且应该比像混元视频模型这样的蒸馏模型更容易训练。
- 图像到视频效果出色:图像到视频模型的行为类似于修复模型,因此你可以从最后一帧而不是第一帧生成视频,或者在两张图像之间生成视频。
- 运动幅度:如果生成了所需的 121 帧,该模型总是会生成有运动幅度的视频。官方测试从未见过它生成没有运动幅度的视频。(PS:LTX模型经常会出现生成视频无运动)
一些缺点
- 帧数限制:该模型非常喜欢 121 帧,如果生成更少或更多的帧,它就会开始出现问题。
- 分辨率限制:模型可以处理的最低分辨率为 704x704。
- 长提示需求:需要长提示词。如果提示词太短,模型将不会遵循提示词。
- 速度较慢:在 4090 上生成 1280x704 的 121 帧视频需要超过 10 分钟。本人的4070显卡则需要36分钟。
使用指南
需要下载的文件
1、文本编码器和 VAE:
oldt5_xxl_fp8_e4m3fn_scaled.safetensors放在:ComfyUI/models/text_encoders/cosmos_cv8x8x8_1.0.safetensors放在:ComfyUI/models/vae/
注意:oldt5_xxl 与 flux 和其他模型中使用的 t5xxl 不同。oldt5_xxl 是 t5xxl 1.0 版本,而 flux 和其他模型中使用的是 t5xxl 1.1 版本。
2、视频模型:
- 视频模型可以在这里找到 safetensors 格式的文件
- 本页的工作流程使用以下文件:
这些文件放在:ComfyUI/models/diffusion_models
注意:“Text to World” 表示文本到视频,“Video to World” 表示图像/视频到视频。
文生视频
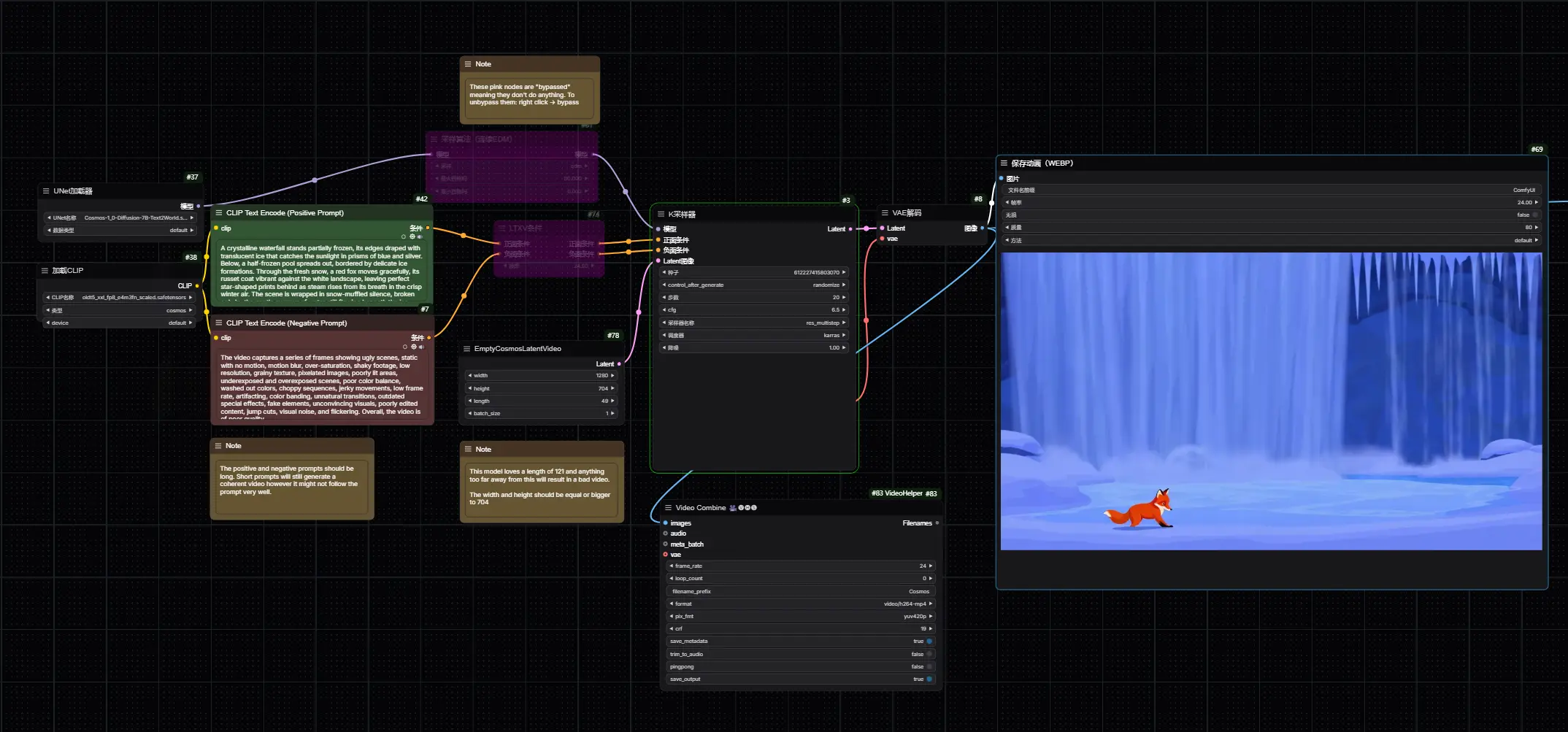
这个工作流程需要你可以在上面下载的 7B 文本转视频模型
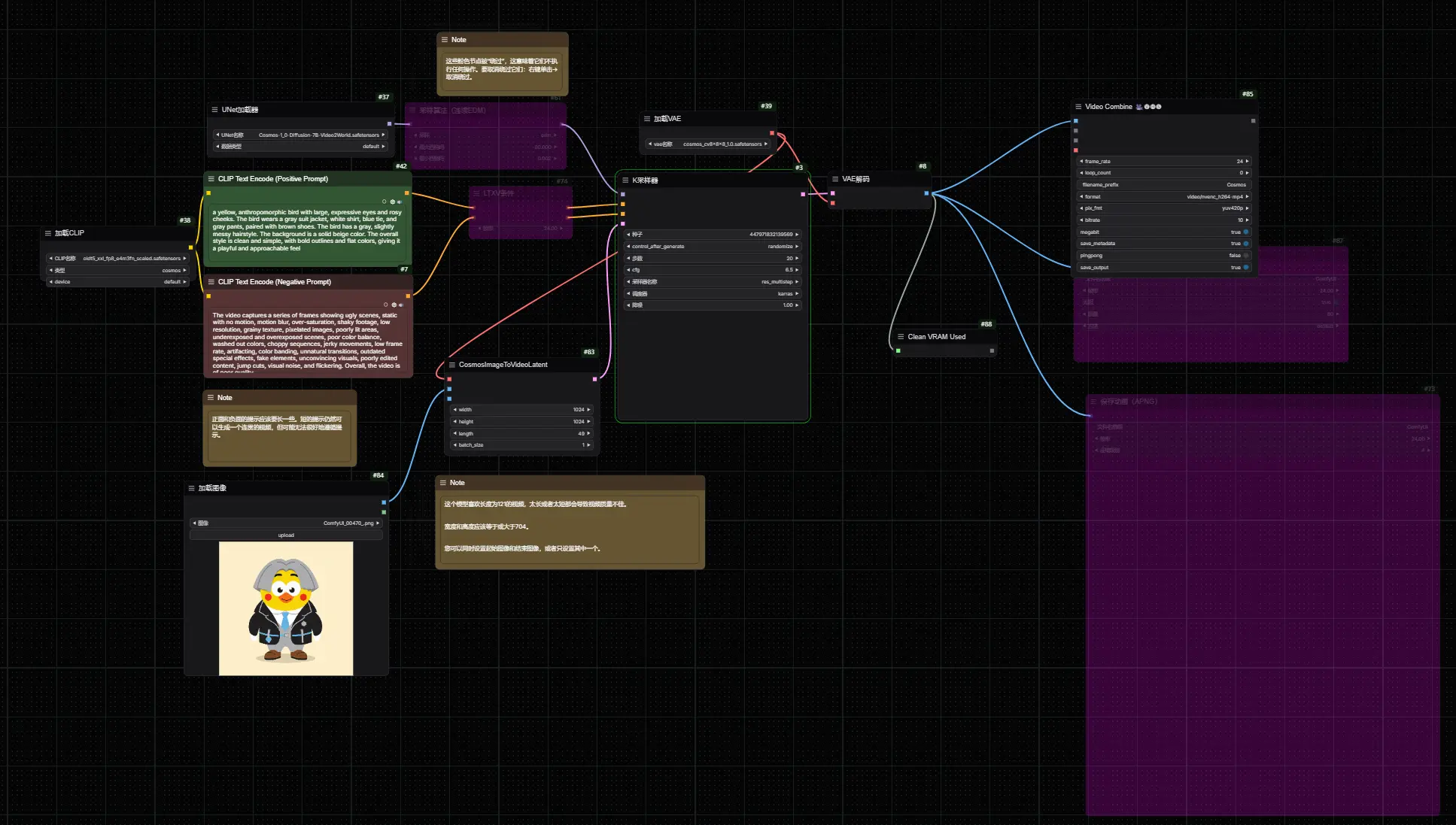
图生视频
这个工作流程需要你可以从上面下载的 7B 图像到视频模型。这个模型主要在现实视频上进行训练,但在这个例子中,你可以看到它在动漫上也表现不错
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











