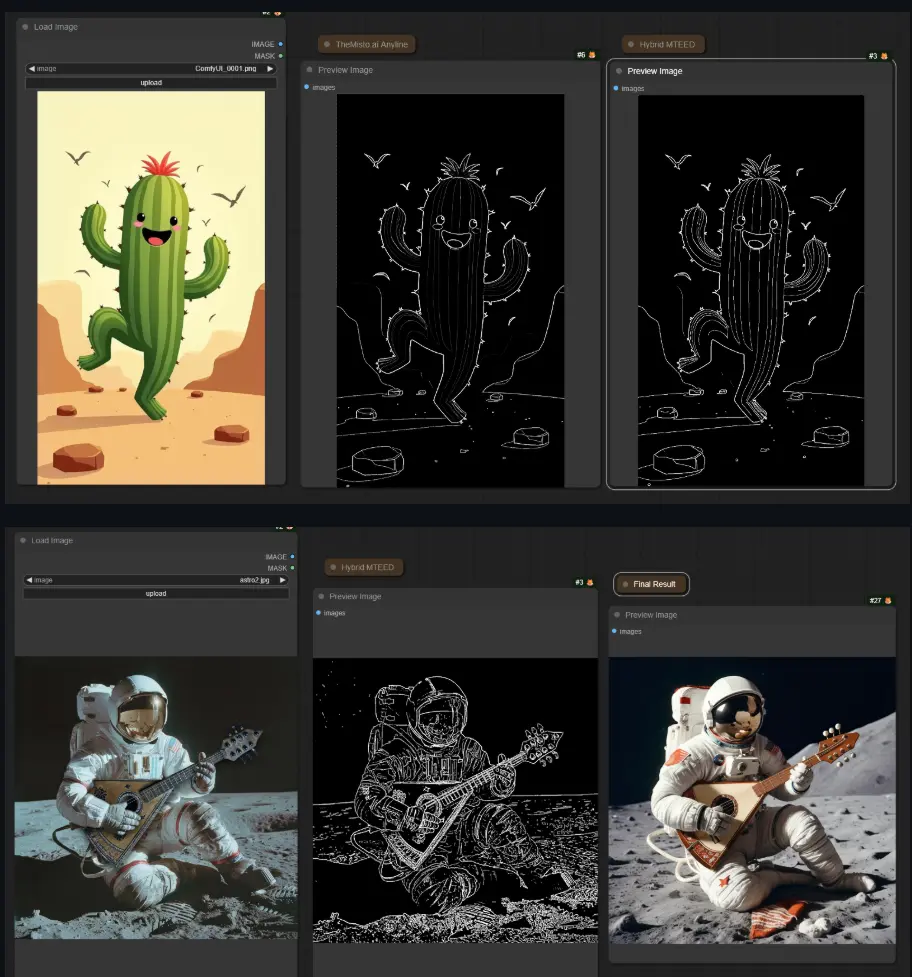
ComfyUI官方在第一时间就宣布支持混元图生视频模型HunyuanVideo-I2V,基于之前的文本到视频(Text-to-Video)实现,这一强大的新功能允许您将静态图像转换为流畅、高质量的视频。现在,这个 13B 模型可以在您的本地显卡上运行。

HunyuanVideo I2V 亮点
图像条件支持:HunyuanVideo I2V 扩展了 13B 开源视频基础模型的能力,增加了对图像条件的支持。 媲美顶级闭源模型的质量:新模态保持了与顶级闭源模型相当甚至更优的质量,缩小了行业能力与公开资源之间的差距。 LoRA 训练:Hunyuan 还发布了用于定制特效的 LoRA 训练代码,可用于创建更有趣的视频效果。
在 ComfyUI 中开始使用 HunyuanVideo I2V
1、更新 ComfyUI 或 ComfyUI Desktop 至最新版本。
2、下载示例工作流:下载工作流并将其拖入 ComfyUI(工作流将引导您将所需模型下载到正确的文件夹中)
提示:如果显存不足,请在“加载扩散模型”节点中选择 fp8 weight_dtype- 网盘下载:https://www.123865.com/s/hyQyTd-v0hDv 提取码:xAoX
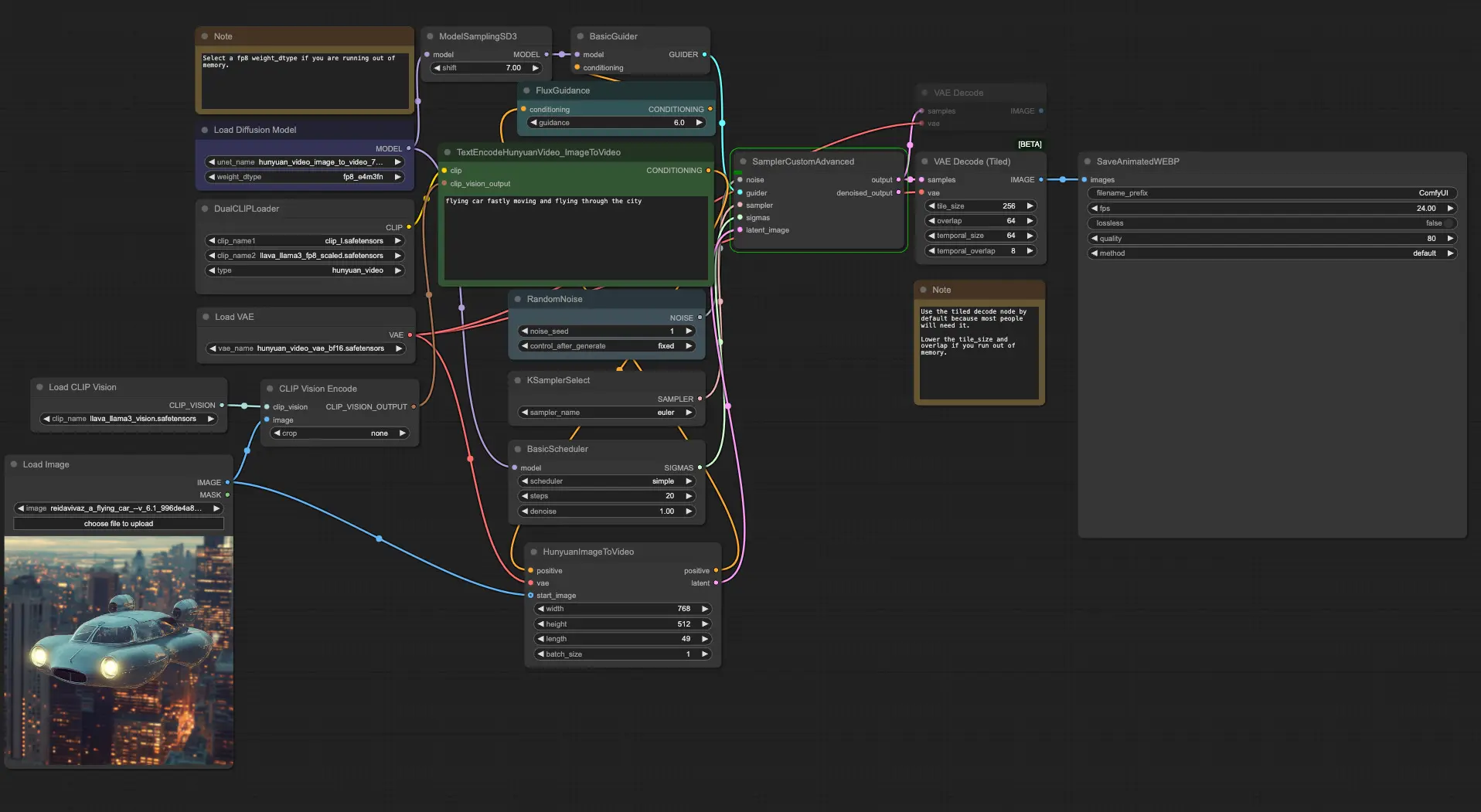
运行要求
下载以下模型并将其放置在指定位置:
- 模型地址:Hugging Face|魔塔
├── clip_vision/
│ └── llava_llama3_vision.safetensors
├── text_encoders/
│ ├── clip_l.safetensors
│ ├── llava_llama3_fp16.safetensors
│ └── llava_llama3_fp8_scaled.safetensors
├── vae/
│ └── hunyuan_video_vae_bf16.safetensors
└── diffusion_models/
└── hunyuan_video_image_to_video_720p_bf16.safetensors
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











