
MAGI-1是由Sand AI研究团队开发的一种新型视频生成模型。该模型通过自回归预测视频块序列来生成视频,每个视频块由固定长度的连续帧组成。MAGI-1的核心目标是实现高保真、实时、因果一致的视频生成,同时支持大规模部署和高效推理。这一研究在视频生成领域具有重要意义,尤其是在需要高时空一致性和实时交互的应用场景中。
MAGI-1的核心在于其对视频片段(固定长度的连续帧段)的处理方式,通过训练对随时间单调增加的每片段噪声进行去噪,实现因果时间建模,并天然支持流式生成。这使得MAGI-1在基于文本指令的图像到视频(I2V)任务中表现出色,提供高时间一致性和可扩展性。

例如,你是一位视频内容创作者,需要为一个广告项目生成一段展示产品功能的视频。使用MAGI-1,你可以上传一张产品的静态图片,并输入一段描述产品功能的文本指令,如“展示产品在不同场景下的使用效果”。MAGI-1将根据这些输入生成一段连贯的视频,展示产品在各种场景中的使用情况,整个过程可以在短时间内完成,且生成的视频具有高质量和高时间一致性。
主要功能
视频生成:MAGI-1能够根据文本指令、静态图像或短视频片段生成高质量的视频内容。 实时流式生成:支持实时视频流式生成,适用于直播、互动媒体等需要低延迟的应用场景。 可控生成:通过块级提示(chunk-wise prompting),用户可以对生成的视频内容进行精细控制。 长视频生成:支持长达数分钟的视频生成,适用于需要长叙事结构的场景。
主要特点
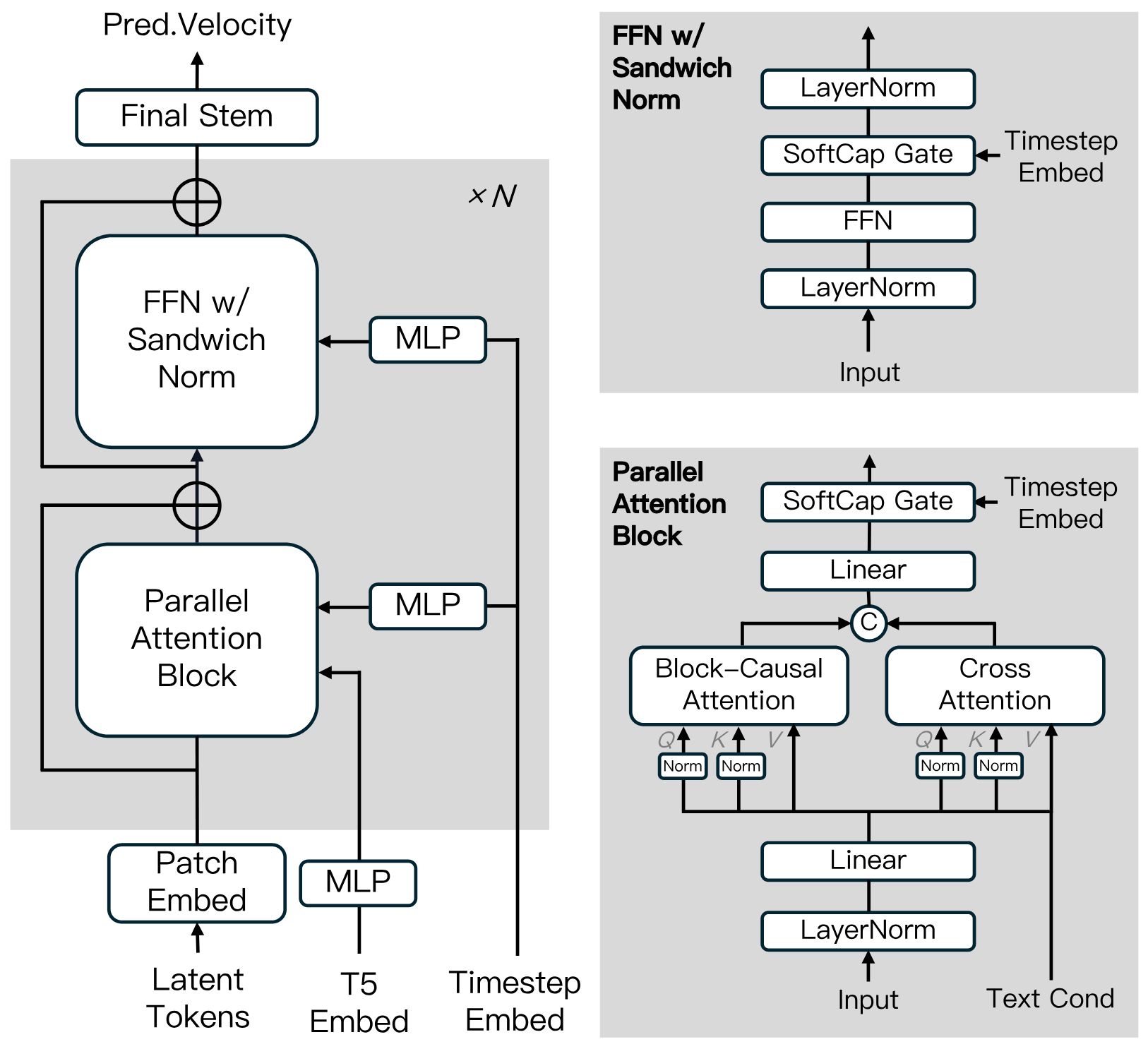
高时间一致性和可扩展性:MAGI-1通过多项算法创新和专用基础设施堆栈,实现了高时间一致性和可扩展性。 可控生成:通过分片提示支持可控生成,实现平滑场景转换、长时域合成和精细的文本驱动控制。 自回归去噪:MAGI-1以逐片段而非整体方式生成视频,每个片段(24帧)被整体去噪,当当前片段达到一定去噪水平后,立即开始生成下一个片段。 流水线设计:这种流水线设计支持最多四个片段的并发处理,以实现高效的视频生成。 基于Transformer的变分自编码器(VAE):采用基于Transformer架构的变分自编码器,具有8倍空间压缩和4倍时间压缩。 快速解码和高质量重建:MAGI-1拥有最快的平均解码时间和极具竞争力的重建质量。 扩散模型架构:基于扩散Transformer构建,融入了多项关键创新,包括块因果注意力、并行注意力块、QK归一化与分组查询注意力(GQA)、前馈网络中的三明治归一化、SwiGLU激活函数和软帽调制。 蒸馏算法:采用快捷蒸馏方法,训练单一基于速度的模型以支持可变的推理预算,实现了高效推理,同时保真度损失最小。
工作原理
MAGI-1的工作原理基于以下关键技术和架构设计:
变分自编码器(VAE):用于将视频压缩到低维的潜在空间,在该空间中进行去噪操作,从而提高训练和推理的效率。 自回归去噪模型:通过逐块预测视频块的去噪轨迹,MAGI-1能够生成具有严格时间一致性的视频。每个块的生成都依赖于前面所有块的信息。 分布式注意力机制(MagiAttention):针对超长序列和异构掩码训练进行了优化,支持高效的并行计算和内存管理。 多任务训练:通过调整训练数据中干净块的比例,MAGI-1能够统一处理文本到视频(T2V)、图像到视频(I2V)和视频续写等多种任务。
模型库
MAGI-1提供了预训练权重,包括24B和4.5B模型,以及相应的蒸馏和蒸馏+量化模型。这些模型的权重链接可以在表格中找到。
| 模型 | 地址 | 硬件要求 |
|---|---|---|
| T5 | T5 | - |
| MAGI-1-VAE | MAGI-1-VAE | - |
| MAGI-1-24B | MAGI-1-24B | H100/H800 * 8 |
| MAGI-1-24B-distill | MAGI-1-24B-distill | H100/H800 * 8 |
| MAGI-1-24B-distill+fp8_quant | MAGI-1-24B-distill+quant | H100/H800 * 4 or RTX 4090 * 8 |
| MAGI-1-4.5B | MAGI-1-4.5B | RTX 4090 * 1 |
评估
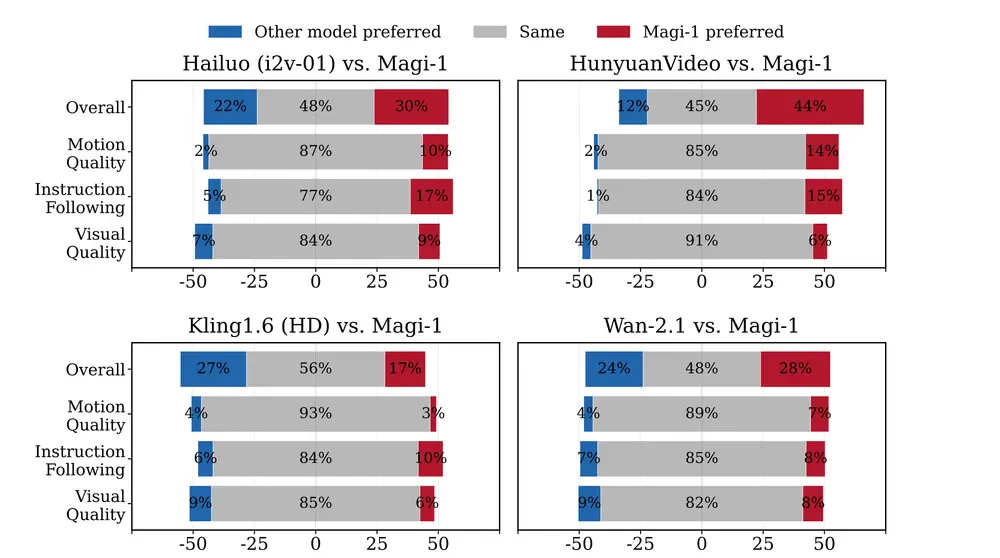
内部人类评估:MAGI-1在开源模型中实现了最先进的性能,超越了Wan-2.1,显著优于Hailuo和HunyuanVideo。尤其在指令遵循和运动质量方面表现出色,使其成为闭源商业模型(如Kling)的有力潜在竞争者。
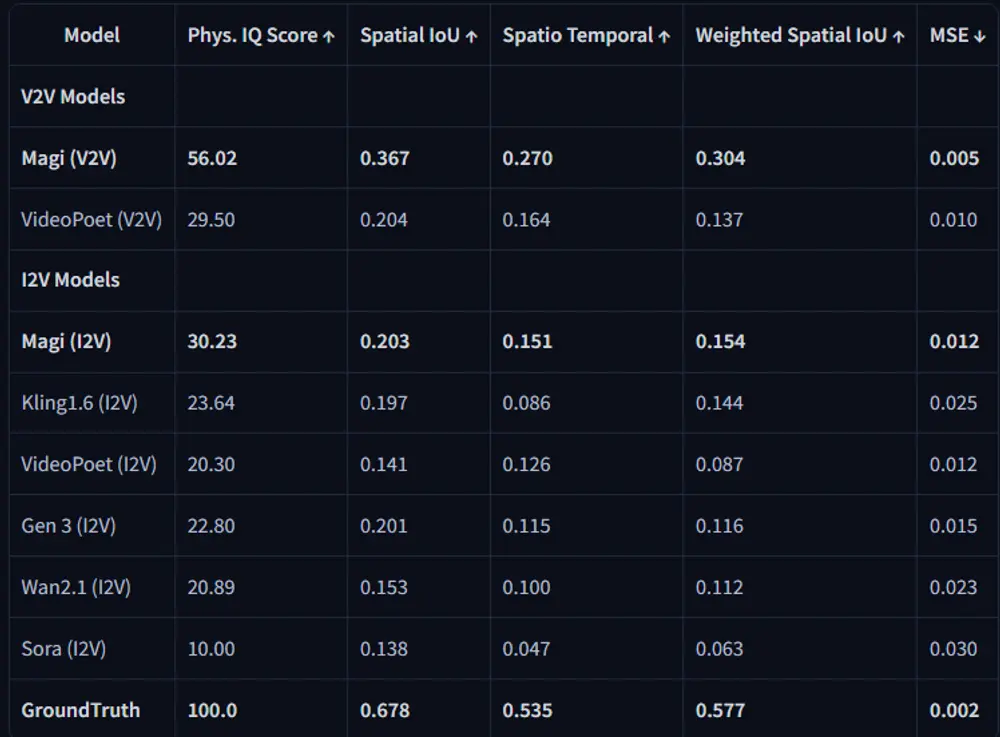
物理评估:得益于自回归架构的天然优势,MAGI-1在通过视频续接预测物理行为时,精度远超所有现有模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











