在虚拟试衣技术持续发展的背景下,如何在视频中实现自然、真实、连贯的服装模拟,依然是一个极具挑战性的课题。
浙江大学、vivo 和博维智慧科技的研究团队提出了一种全新的视频虚拟试衣(Video Virtual Try-On, VVT)框架——MagicTryOn。该模型基于大规模视频扩散 Transformer 架构(Wan2.1),该方法能够模拟服装在连续视频帧中的动态变化,并捕捉服装与人体运动的复杂交互。
- 项目主页:https://vivocameraresearch.github.io/magictryon
- GitHub:https://github.com/vivoCameraResearch/Magic-TryOn
- 模型:https://huggingface.co/LuckyLiGY/MagicTryOn
挑战:现有方法存在三大瓶颈
当前主流的视频虚拟试衣方法仍面临以下核心问题:
- 表达能力有限:多采用基于 U-Net 的扩散模型,难以重建复杂服装细节;
- 时空一致性不足:空间与时间注意力分离建模,导致帧间不连贯、服装抖动;
- 服装信息保留弱:纹理、轮廓等关键特征易丢失,影响视觉真实感,尤其在动态运动场景下更为明显。
这些问题严重制约了虚拟试衣技术在电商、影视、游戏等实际场景中的落地。
MagicTryOn:以扩散 Transformer 重构视频试衣范式
为应对上述挑战,研究团队提出了 MagicTryOn,其核心创新包括:
1. 使用大规模视频扩散 Transformer 替代传统 U-Net
MagicTryOn 引入了基于 Wan2.1 的扩散 Transformer 架构,具备更强的特征建模能力和多尺度融合机制,从而更有效地捕捉服装在连续帧中的动态变化。
2. 设计从粗到细的服装保留策略
- 粗粒度保留:在嵌入阶段整合服装语义标记(如服装类别、颜色等),提供全局指导;
- 细粒度保留:在去噪阶段引入语义引导交叉注意力(SGCA)和特征引导交叉注意力(FGCA),分别注入服装的全局语义和局部细节信息。
3. 引入掩码感知损失函数
通过引入专门针对服装区域的掩码感知损失(Mask-Aware Loss),增强对服装细节的生成质量控制,提升最终输出的真实感和稳定性。
技术流程详解
MagicTryOn 的整体架构如下:
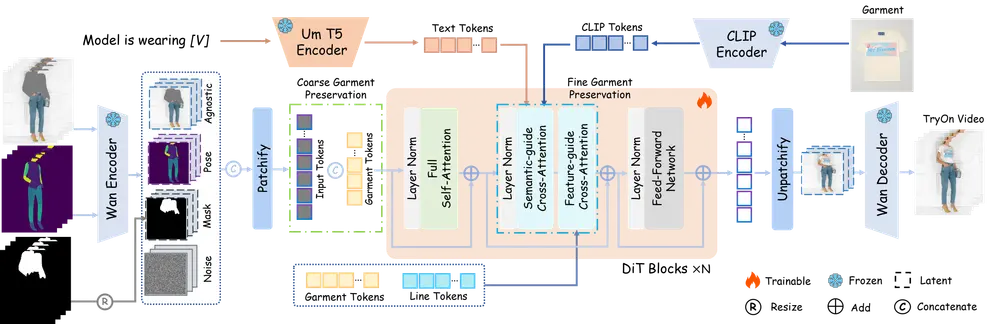
输入组成:
- 人物视频序列
- 姿态表示(如骨骼点)
- 服装无关区域的掩码
- 目标服装图像
处理流程:
- 编码阶段
- 人物视频和姿态信息通过 Wan 视频编码器映射为潜在空间表示;
- 掩码图像被调整为掩码潜在表示;
- 目标服装图像提取多级特征,包括文本、CLIP、服装和线条令牌。
- 粗粒度服装保留
- 将服装令牌拼接到输入序列中,并调整旋转位置嵌入(RoPE)网格大小,以便在全自注意力机制下建模服装与人体的关系。
- 细粒度服装保留
- 在扩散 Transformer 的每个去噪块中,通过 SGCA 提供语义层面的服装描述;
- 通过 FGCA 注入服装局部特征,确保生成结果在动态过程中依然保留原始服装细节。
- 去噪与解码
- 经过多轮去噪迭代后,生成试穿结果的潜在表示;
- 最终由 Wan 视频解码器还原为高质量的视频输出。
实验验证:多项指标超越 SOTA
研究人员在多个主流数据集上进行了广泛测试,包括:
- VITON-HD(高分辨率图像数据集)
- DressCode(多样化服装数据集)
- ViViD(视频虚拟试衣基准)
图像任务表现优异:
MagicTryOn 在以下关键评估指标上均优于当前最先进的方法(SOTA):
| 指标 | 表现 |
|---|---|
| SSIM | 更高 |
| LPIPS | 更低 |
| FID | 更低 |
| KID | 更低 |
视频任务优势显著:
- VFID-I3D:显著优于现有方法,表明在视频动态一致性方面更具优势;
- VFID-ResNeXt:同样领先,说明在动作交互建模方面效果更佳。
特殊场景下的鲁棒性:
在跳舞、行走等复杂运动场景下,MagicTryOn 能够稳定保留服装细节并维持良好的时空一致性,展现出强大的泛化能力。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...