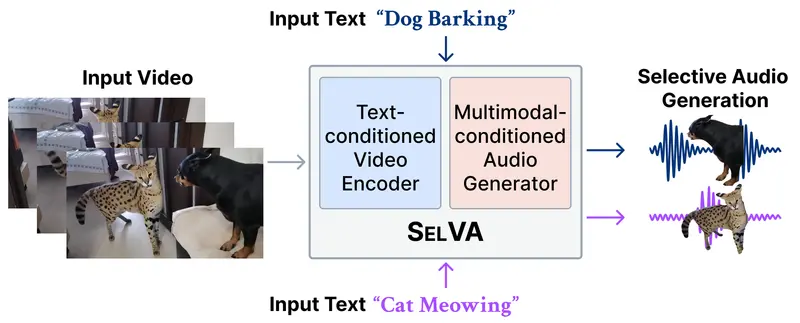
新SelVA:基于文本指令的视频选择性配音技术韩国科学技术院(KAIST)MAC 实验室与梨花女子大学 MMAI 实验室的研究人员共同提出了一项新任务:基于文本条件的选择性视频到音频生成(Text-Conditioned Selective Vi...视频模型# SelVA# 配音2天前040
新Netflix 推出 VOID:能理解物理交互的视频物体移除技术Netflix 联合保加利亚索菲亚大学团队,发布了一项视频编辑技术——VOID (Video Object and Interaction Deletion)。 GitHub:https://gith...视频模型# Netflix# VOID# 物体移除2天前040
阿里发布全模态可控视频生成模型Wan2.7-Video:不仅是生成器,更是你的“AI 导演套件”阿里巴巴今日正式发布 视频生成模型Wan2.7-Video 。这不仅是一个文生视频工具,更是一套全模态、全链路的智能视频创作系统。Wan2.7 打破了传统 AI 视频“抽卡式”生成的局限,真正实现了让...早报视频模型# Wan2.7-Video# 阿里巴巴4天前0200
OmniWeaving:开源视频生成的“全能王”,首个具备推理与自由组合能力的统一模型OmniWeaving 是由 腾讯混元、浙江大学 和 南洋理工大学的研究人员推出的基于HunyuanVideo-1.5的视频生成模型。它填补了开源社区与闭源顶尖系统(如 Seedance-2.0)之间...视频模型# HunyuanVideo-1.5# OmniWeaving# 腾讯4天前0130
谷歌推出 Veo 3.1 Lite:最具成本效益的视频生成模型,助力开发者大规模应用谷歌今日正式宣布推出 Veo 3.1 Lite,这是其 Veo 3.1 系列中最具成本效益的视频生成模型。该模型现已通过 Gemini API 和 Google AI Studio 向开发者开放,旨在...早报视频模型# Veo 3.1 Lite# 谷歌6天前0140
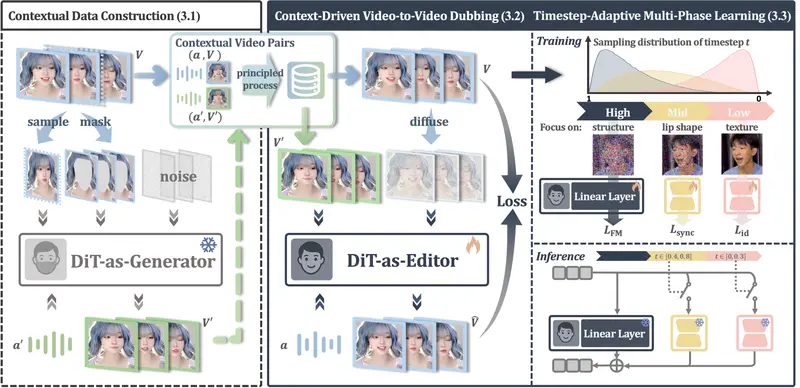
X-Dub:告别“面具式”配音,AI 让视频唇同步更自然逼真在影视翻译、虚拟人互动和短视频创作中,音频驱动的视觉配音(Visual Dubbing)技术至关重要。然而,传统方法长期受困于一个核心难题:缺乏完美的成对训练数据(即除了嘴型不同,其他完全一致的视频...视频模型# X-Dub# 数字人# 配音1周前0160
daVinci-MagiHuman:单流架构重塑音视频生成,1080p 仅需 38 秒的开源新标杆在 AI 生成内容(AIGC)领域,音视频联合生成一直被视为“皇冠上的明珠”。然而,现有的开源方案往往陷入两难:要么采用复杂的多流架构导致推理缓慢、难以优化,要么为了速度牺牲了人物表情与语音的自然度...视频模型# daVinci-MagiHuman# 视频生成2周前01260
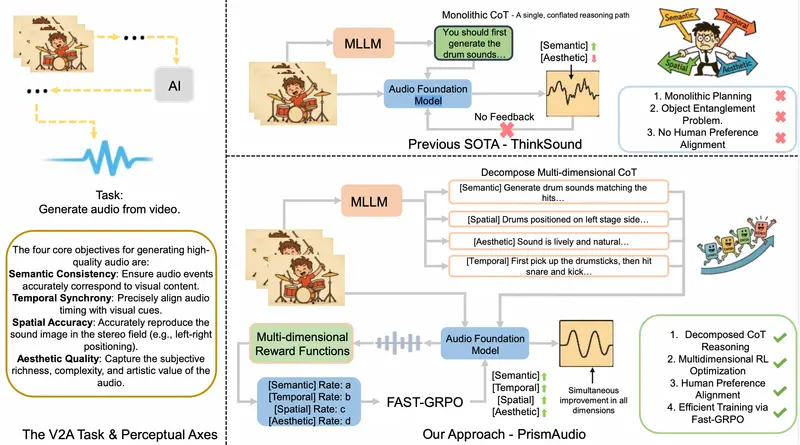
PrismAudio:阿里通义首创“思维链+强化学习”视频音效框架,让AI学会“先思考再发声”在视频生成领域,画面与声音的同步一直是难以攻克的“最后一公里”。传统的视频转音频(Video-to-Audio)模型往往采用“端到端”的黑箱模式:输入视频,直接输出音频。这种“直觉式”生成容易导致声音...视频模型# PrismAudio# 视频音效2周前0210
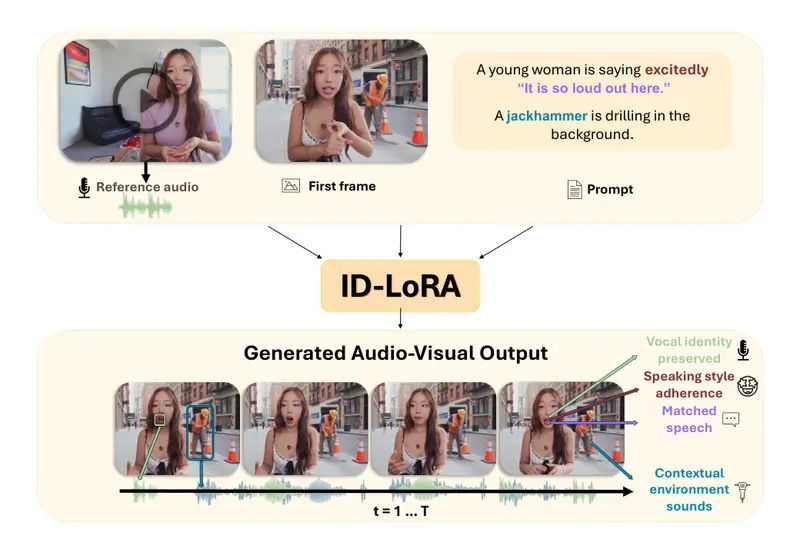
ID-LoRA:让AI同时“克隆”你的长相和声音,还能配合场景表演你有没有想过,如果AI能根据一张照片和一段声音,就能生成一个“数字分身”,让这个分身在任何场景中说话、表演,而且声音和口型都能完美匹配,这会带来什么可能? 这正是特拉维夫大学等研究机构最新发布的 ID...视频模型# ID-LoRA# 数字人3周前0280
EffectMaker:腾讯混元新作,无需微调即可“克隆”电影级特效,让普通人也能做 VFX 大师“好莱坞大片里那些令人震撼的火焰、冰霜、能量波,曾经需要数百万美元和数年训练才能制作。现在,只需一段参考视频和一张照片,AI 就能为你‘克隆’出同样的奇迹。” 由 腾讯混元 (Tencent HunY...视频模型# AI特效# EffectMaker4周前0300
Lightricks 双重重磅发布:LTX-2.3 模型进化与 LTX Desktop 开源编辑器,本地视频生成时代正式来临Lightricks 今日宣布同步推出两项里程碑式产品:LTX-2.3,一个经过实战打磨、架构全面升级的视频生成模型;以及 LTX Desktop,一款直接构建于该引擎之上的生产级本地视频编辑器。 这...早报视频模型# Lightricks# LTX Desktop# LTX-2.31个月前02070
Helios:北大与字节联手打造 14B 实时长视频模型,单卡 19.5 FPS 刷新生成速度纪录在 AI 视频生成领域,长期存在一个“不可能三角”:生成速度快、视频时长长、画面质量高,三者往往难以兼得。主流模型要么只能生成几秒的短视频,要么需要数十分钟才能渲染出几秒钟的画面,且长视频极易出现人物...视频模型# Helios# 实时长视频模型1个月前01860