在视频生成领域,画面与声音的同步一直是难以攻克的“最后一公里”。传统的视频转音频(Video-to-Audio)模型往往采用“端到端”的黑箱模式:输入视频,直接输出音频。这种“直觉式”生成容易导致声音与画面内容不符、节奏错位、音质单调或空间感缺失。
- 项目主页:https://prismaudio-project.github.io
- GitHub:https://github.com/FunAudioLLM/ThinkSound/tree/prismaudio
- Hugging Face :https://huggingface.co/FunAudioLLM/PrismAudio
- ModelScope:https://www.modelscope.cn/models/iic/PrismAudio
- Demo:https://huggingface.co/spaces/FunAudioLLM/PrismAudio
- Demo:https://www.modelscope.cn/studios/iic/PrismAudio
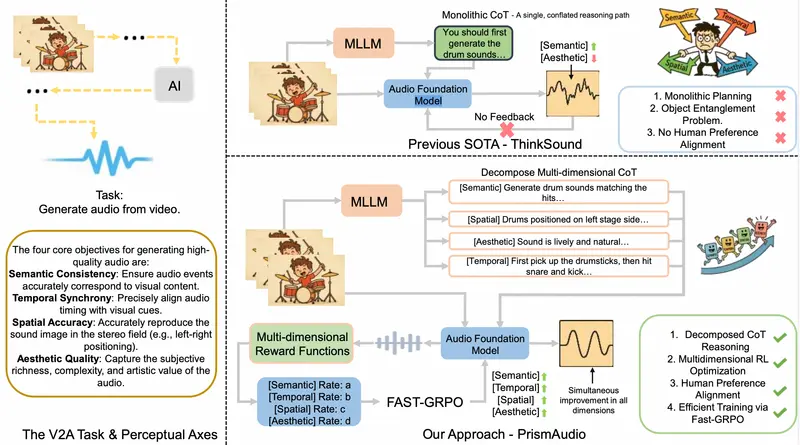
阿里巴巴通义实验室正式发布了 PrismAudio —— 全球首个将 强化学习 (RL) 与 思维链 (Chain-of-Thought, CoT) 紧密结合的视频生成环境音框架。它不再让模型“瞎蒙”,而是教会 AI “先思考,再发声”,通过结构化的推理过程,生成高保真、强贴合的立体声环境音效。
核心理念:像人类一样“先写笔记,再干活”
PrismAudio 的最大创新在于打破了传统模型的“黑箱”操作,引入了分解式思维链。在生成声音之前,模型必须先完成一份详细的“行动指南”,回答四个关键问题:
- 语义(是什么?):画面里有马蹄还是鸟叫?是金属敲击还是风雨声?
- 时序(何时发生?):声音何时开始、结束?节奏快慢如何?顺序怎样排列?
- 美学(什么质感?):声音是清脆还是低沉?是否有层次感?是否自然悦耳?
- 空间(来自哪里?):声源在左还是右?是否有移动轨迹?远近关系如何?
只有当这四份“笔记”拼接完成后,音频生成模型才会依据这份结构化指令执行。这种可解释性的推理过程,确保了每一步生成都有据可依。
训练机制:四位“虚拟老师”的联合打分
为了解决“顾此失彼”的难题(例如声音好听但不同步,或同步但内容错误),PrismAudio 引入了四位独立的“老师”,每位老师配备专属的奖励函数 (Reward Function),对生成结果进行多维度打分:
| 老师角色 | 考核维度 | 打分工具 | 职责描述 |
|---|---|---|---|
| 语义老师 | 内容匹配 | MS-CLAP | 盯着画面,确保“弹吉他出吉他声”,杜绝张冠李戴。 |
| 时序老师 | 音画同步 | Synchformer | 拿着秒表,监督声音与动作严丝合缝,误差控制在毫秒级。 |
| 美学老师 | 音质听感 | Meta Audiobox Aesthetics | 挑剔音质,要求声音自然、动态丰富、无机械刺耳感。 |
| 空间老师 | 立体声定位 | StereoCRW | 听声辨位,验证左右声道信息与画面声源位置完全一致。 |
模型的目标是最大化这四个分数的综合总和。这意味着它不能偏科,必须同时在内容、节奏、音质和空间感上达到高标准。
效率突破:Fast-GRPO 算法
将强化学习应用于扩散模型通常面临训练慢、成本高的问题。为此,通义实验室提出了 Fast-GRPO (Group Relative Policy Optimization) 高效训练算法:
- 混合采样策略:只在生成过程的关键步骤引入随机性探索,其余时间走“快速通道”(确定性计算)。
- 性能飞跃:实验显示,在单独优化某项指标时,Fast-GRPO 仅需 200 步 即可达到传统方法 600 步 的性能水平,大幅降低了算力成本和时间消耗。
核心功能与效果
PrismAudio 专为环境音/音效合成设计(如马蹄声、风雨声、金属撞击声),而非人物配音。其核心能力包括:
- 内容精准匹配:彻底解决“画面敲桌出鸟叫”的幻觉问题,物体与声音一一对应。
- 时序完美同步:声音的起停、节奏与画面动作精准契合,无提前或滞后。
- 听觉质感出色:生成的音频自然清晰,具有丰富的层次感和动态范围,告别单调机械音。
- 空间定位准确:作为立体声模型,能精准还原声源的左右方位及移动轨迹,提供沉浸式空间感知。
- 复杂场景适配:能同时处理多事件并发场景(如:人声 + 杯子碰撞 + 窗外雨声),并合理融合各音轨。
技术架构详解
PrismAudio 的工作流分为三个核心阶段:
第一阶段:基础模型构建
- 视频编码器:采用先进的 VideoPrism,精准捕捉视频中的物体、动作及场景上下文,而非孤立帧。
- 文本编码器:使用 T5-Gemma,增强对结构化推理指令的理解能力。
- 预训练:在海量视频 - 音频数据上进行基础能力训练。
第二阶段:结构化思维链生成
- 利用 Gemini 2.5 Pro 分析视频,生成包含语义、时序、美学、空间四维度的详细推理数据。
- 微调 VideoLLaMA2 模型,使其能独立为任意无声视频生成这份“结构化设计方案”。
第三阶段:强化学习优化 (Fast-GRPO)
- 基于四维奖励函数,利用 Fast-GRPO 算法对模型进行迭代优化。
- 通过群体相对优势计算,寻找四个维度的最优平衡点,最终输出高质量音频。
测试结果:全面超越 SOTA
研究团队构建了包含 300 类单一事件、501 个复杂多事件样本的 AudioCanvas 基准数据集,并在 VGGSound 和 AudioCanvas 上进行了广泛测试:
- 同领域顶尖:在 VGGSound 测试集中,PrismAudio 在语义、时序、美学、空间四个维度均达到 SOTA (State-of-the-Art) 水平。相比前最优模型 ThinkSound,其空间定位误差大幅降低,人类主观评分显著更高。
- 跨领域稳健:在 AudioCanvas 的复杂场景中,其他模型性能大幅衰退,而 PrismAudio 依然保持稳定,甚至在语义匹配和时序同步上超越了真实原始音频的表现,证明其真正掌握了音画对应的底层规律,而非死记硬背。
- 消融实验验证:证实了“多维度思维链”、“多维奖励机制”及“Fast-GRPO 算法”缺一不可,共同构成了模型的高性能基石。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...