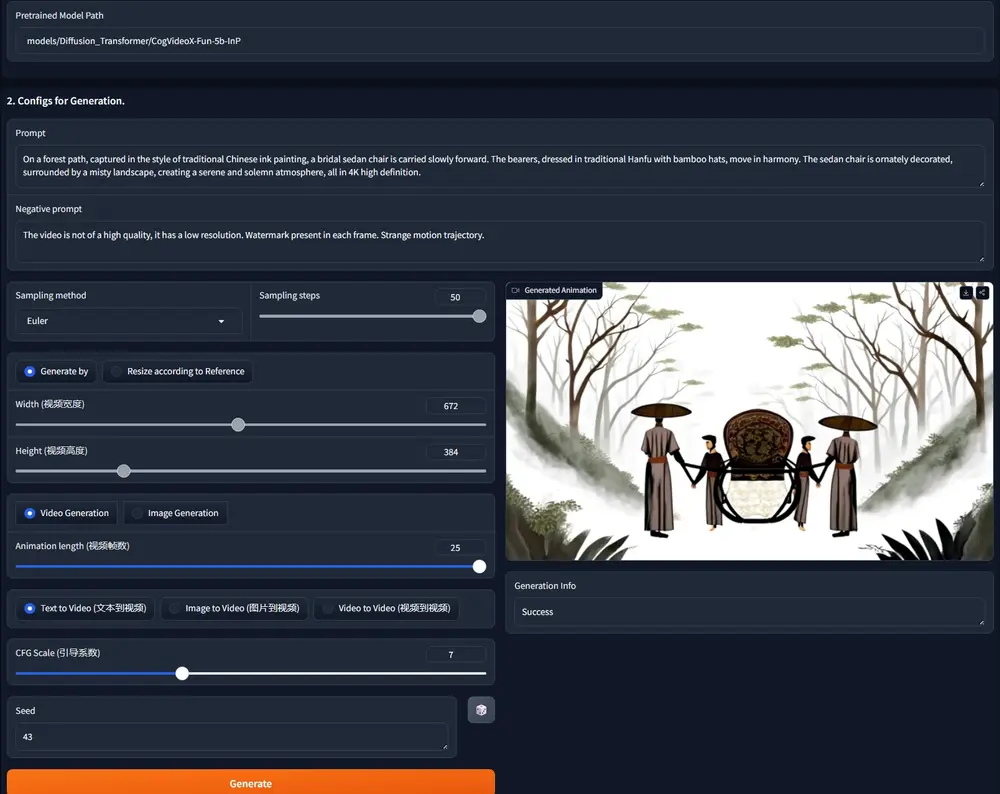
随着高质量视频内容需求的快速增长,如电影级超高清(UHD)制作、沉浸式媒体和短视频创作,对文本到视频(T2V)模型的能力提出了更高要求。
然而,现有公开数据集在分辨率、图像质量及字幕细节方面存在明显不足,严重制约了相关研究与落地应用的发展。
为此,浙江大学、上海交通大学、华中科技大学与南洋理工大学联合推出:
- 一个全新的高质量 4K/8K 超高清视频数据集:UltraVideo
- 基于该数据集训练的高性能视频生成模型:UltraWAN
这套组合不仅填补了当前 T2V 领域在高分辨率内容生成上的空白,也为未来的研究与产业应用提供了坚实基础。
- 项目主页:https://xzc-zju.github.io/projects/UltraVideo
- GitHub:https://github.com/xzc-zju/UltraVideo
- UltraVideo数据集:https://huggingface.co/datasets/APRIL-AIGC/UltraVideo
- UltraWAN模型:https://huggingface.co/APRIL-AIGC/UltraWan
- ComfyUI版本:https://huggingface.co/Alissonerdx/UltraWanComfy
推荐 LoRA 强度
| LoRA 版本 | 推荐强度 |
|---|---|
| ultrawan_1k | 0.25 |
| ultrawan_4k | 0.5 |
| 您可以尝试不同的值,但这些是获得最佳结果的推荐起点。 |
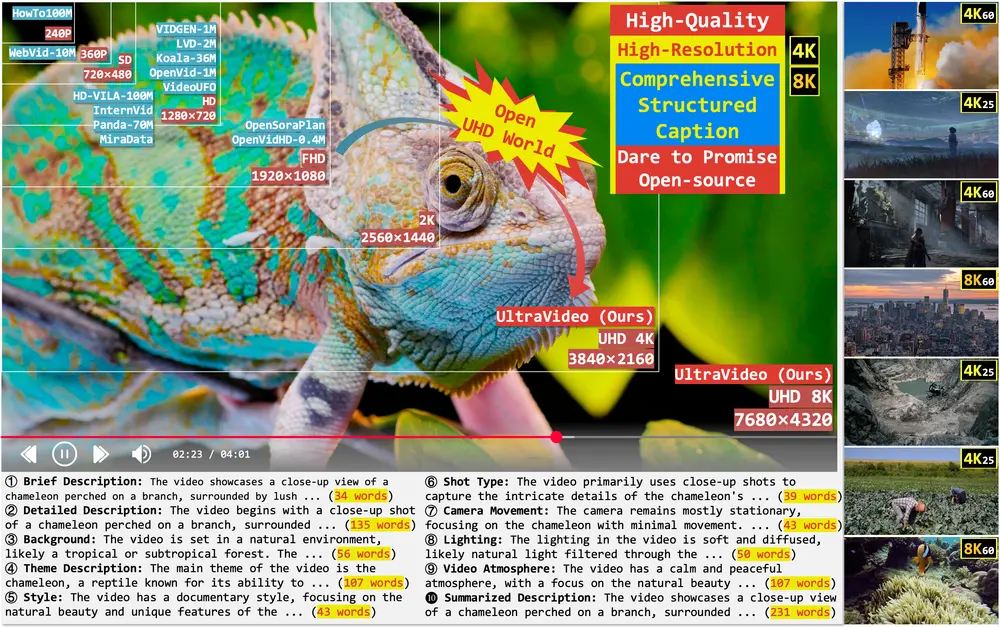
UltraVideo:首个面向 UHD 视频生成的开源数据集
UltraVideo 是目前首个支持 4K/8K 超高清视频生成 的开源数据集,其核心特点包括:
| 特性 | 描述 |
|---|---|
| 🎥 高清视频内容 | 所有视频均为 4K 或 8K 分辨率(其中 22.4% 为 8K),具备丰富纹理与视觉细节。 |
| 📄 结构化字幕系统 | 每个视频配有 9类结构化字幕 + 1个总结性字幕,平均长度达 824 字,支持细粒度语义控制。 |
| 🌍 多样化主题覆盖 | 涵盖超过 100 种主题,适用于多种视频生成任务。 |
| 🔍 严格筛选流程 | 采用四阶段自动化处理流程,确保数据质量与可用性。 |
四阶段构建流程详解:
- 视频收集:从 YouTube 精选高分辨率视频,排除低质量或非 UHD 内容;
- 统计过滤:通过检测黑边、曝光异常、灰度图等问题帧,剔除不合格片段;
- 模型净化:使用 Qwen2.5-VL-72B 等大型多模态模型评估美学质量与运动一致性;
- 字幕生成:利用开源多模态语言模型自动生成结构化描述,涵盖动作、场景、时间线等多个维度。
UltraWAN:基于 UltraVideo 训练的高性能视频生成模型
在 UltraVideo 数据集的基础上,研究人员进一步扩展 WAN 架构,推出支持 原生 1K / 4K 视频生成 的模型:UltraWAN-1K / UltraWAN-4K。
相比传统 T2V 模型,UltraWAN 在多个关键指标上表现出显著优势:
✨ 核心能力亮点:
- 原生支持 UHD 分辨率:无需后处理即可直接输出 1K 和 4K 视频。
- 更强的文本可控性:得益于结构化字幕的支持,生成结果与提示词匹配更精准。
- 更高的视觉质量:生成画面细节更清晰、动态表现更自然、色彩还原更真实。
技术实现要点
UltraWAN 的训练策略经过精心设计,以充分利用 UltraVideo 的高质量数据资源:
| 方法 | 说明 |
|---|---|
| 随机字幕采样 | 在训练过程中,随机选择不同类型的字幕作为输入提示,提升模型对多样化指令的理解能力。 |
| 子视频采样机制 | 从每个视频中均匀采样帧序列,保证生成内容与对应字幕的一致性。 |
| LoRA 参数高效微调 | 使用 LoRA 插件进行轻量级训练,降低计算成本与显存占用,同时保持模型性能。 |
实测效果对比
在多个测试基准与实际案例中,UltraWAN 表现出优于现有主流模型的表现:
📊 定量评估(VBench 基准)
| 指标 | UltraWAN-1K 相比 Wan-T2V-1.3B 提升幅度 |
|---|---|
| 背景一致性 | ⬆️ 显著提升 |
| 动态程度 | ⬆️ 更加自然流畅 |
| 美学质量 | ⬆️ 细节更丰富,色彩更真实 |
👥 定性评估(人类偏好实验)
在视频美学质量、时间稳定性与文本一致性方面,UltraWAN-1K 均获得用户更高评分,展现出更强的实用潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











