由 Meta Reality 实验室、南洋理工大学 和 上海人工智能实验室 联合提出的新模型 EdgeTAM 引起了广泛关注。该模型是对 Segment Anything Model 2(SAM 2)的轻量化改进版本,专为在移动设备上高效运行而设计,且在保持准确性的前提下,实现了显著的速度提升。
- GitHub:https://github.com/facebookresearch/EdgeTAM
- Demo:https://huggingface.co/spaces/facebook/EdgeTAM
模型背景与目标
Segment Anything Model 2(SAM 2) 是 Meta 推出的一款强大的通用图像和视频分割模型,能够根据用户提示(如点击或框选)精确地分割图像或视频中的对象。然而,由于其计算复杂度较高,在移动端部署时面临性能瓶颈。
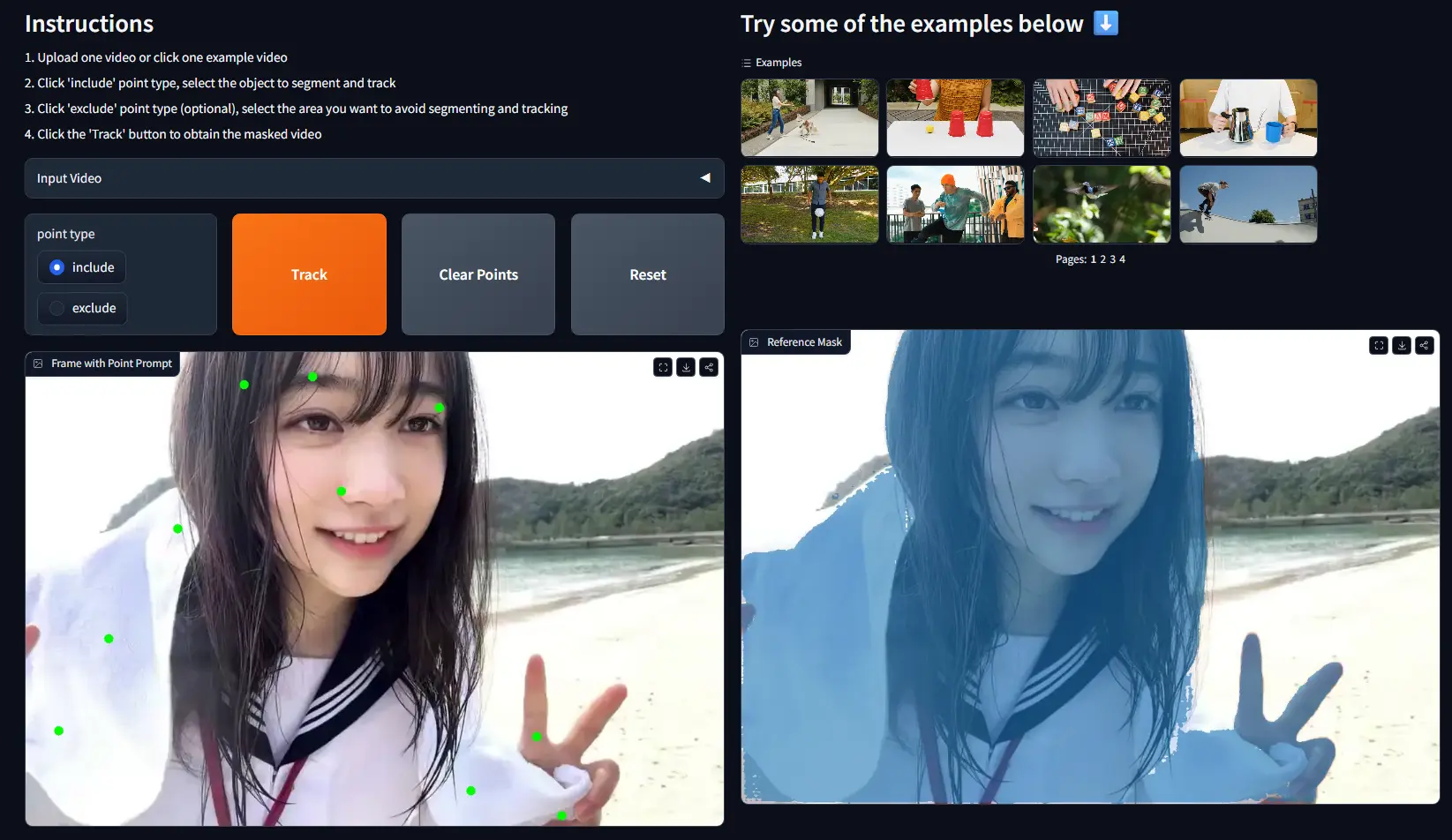
为此,研究团队提出了 EdgeTAM —— 一个面向边缘设备(如智能手机)的轻量级替代方案。EdgeTAM 不仅能够在 iPhone 15 Pro Max 上实现 无量化情况下 16 FPS 的实时推理速度,而且相比 SAM 2,在移动设备上的运行速度提升了 22 倍。
核心功能
EdgeTAM 主要用于以下任务:
- 视频对象分割(VOS)
- 可提示视频分割(PVS)
- 图像对象分割(SA)
它支持通过点击、框选等方式指定感兴趣对象,并在视频中进行持续跟踪和分割,适用于多种交互式应用场景。
技术亮点
1. 2D Spatial Perceiver 模块
EdgeTAM 引入了一种新颖的模块,将帧级别的记忆特征图压缩为更小的标记集,同时保留二维空间结构。这大大降低了注意力机制的计算开销,使模型更适合移动端部署。
2. 知识蒸馏流程
为了弥补轻量化带来的精度损失,研究人员采用知识蒸馏方法,将 SAM 2 的强大能力迁移到 EdgeTAM 中。这一过程不会增加推理负担,但能有效提升最终效果。
3. 两阶段训练策略
EdgeTAM 的训练分为两个阶段:
- 第一阶段:在图像分割任务上预训练
- 第二阶段:在视频分割任务上微调
这种策略确保了模型既能继承 SAM 2 的泛化能力,又能适应视频序列处理的需求。
📊 性能测试结果
| 数据集 | J & F 分数 |
|---|---|
| DAVIS 2017 | 87.7 |
| MOSE | 70.0 |
| SA-V val | 72.3 |
| SA-V test | 71.7 |
这些结果显示,尽管 EdgeTAM 是轻量化版本,但在多个主流视频分割数据集上仍表现优异,甚至在某些指标上超越了原版 SAM 2。
此外,在 iPhone 15 Pro Max 上的实测显示,EdgeTAM 可以在不使用量化的情况下达到 16 FPS 的稳定帧率,满足大多数实时应用的需求。
🎯 应用场景
EdgeTAM 的轻量化与高性能特性使其非常适合以下场景:
- 📱 移动端视频编辑:快速添加特效、更换背景、对象抠图等。
- 📹 视频监控系统:实时检测并跟踪可疑目标,提高安防效率。
- 👓 增强现实(AR)应用:实时识别和分割物体,增强用户交互体验。
- 🚗 自动驾驶辅助:处理车载摄像头视频流,帮助识别道路障碍物。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











