
随着视频生成模型的发展,基于DiT架构如 Sora 和 MM-DiT 在单提示视频生成任务中取得了显著进展。然而,这些模型在处理多个顺序提示时面临诸多挑战,难以生成连贯且自然过渡的场景。具体来说:
严格的训练数据要求:多提示视频生成需要大量标注的数据,这增加了训练成本和复杂性。 提示跟随能力弱:现有模型在处理多个提示时,往往无法准确跟随每个提示的变化,导致生成的视频缺乏一致性。 过渡不自然:不同提示之间的过渡通常不够平滑,影响了视频的整体质量。
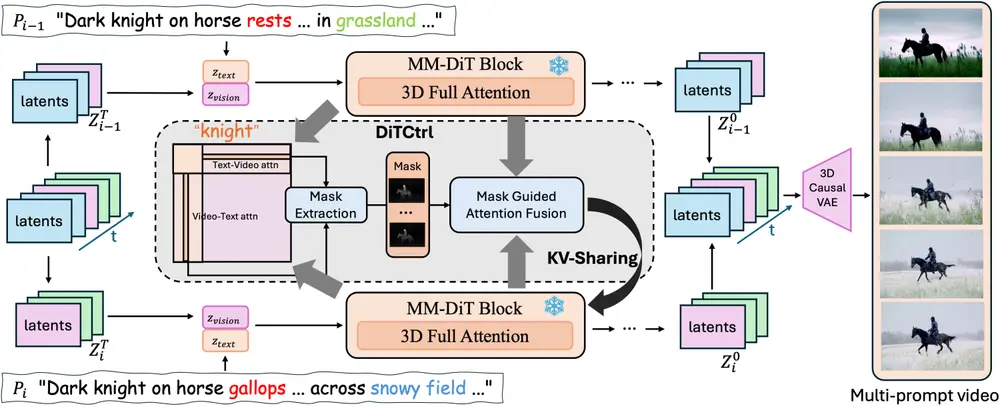
为了解决这些问题,香港中文大学 MMLab、大湾大学 GVC 实验室、腾讯 PCG ARC 实验室和腾讯 AI 实验室的研究人员提出了 DiTCtrl,一种在 MM-DiT 架构下无需额外训练的多提示视频生成方法。该方法的核心思想是将多提示视频生成任务视为具有平滑过渡的时间视频编辑,通过注意力共享实现跨不同提示的精确语义控制。这种方法首次在MM-DiT架构下实现,能够处理复杂的动作和平滑的场景转换,生成更长的视频序列。
例如,我们有两个提示:“一个运动员在海浪上滑翔”和“同一个运动员在沙漠沙丘上滑行”。使用DiTCtrl,我们可以生成一个视频,展示运动员从一个场景平滑过渡到另一个场景,同时保持动作的连贯性和场景的无缝转换。这种能力使得DiTCtrl非常适合用于电影制作、游戏开发和虚拟现实等领域,其中需要创建动态和引人入胜的视频内容。

主要功能和特点:
- 无需额外训练:DiTCtrl是一种无需额外训练的多提示视频生成方法,它可以在预训练的MM-DiT视频生成模型下工作。
- 平滑过渡:DiTCtrl能够生成具有平滑过渡和一致对象运动的多提示视频,即使在面对多个顺序提示时也能做到。
- 注意力控制:通过分析MM-DiT的注意力机制,DiTCtrl利用3D全注意力模块实现类似UNet扩散模型中的跨/自注意力块的功能,从而在不同提示间进行精确的语义控制。
- KV共享机制:DiTCtrl引入了一种键值(KV)共享方法,以保持关键对象的语义一致性。
- 潜在混合策略:为了在不同语义段之间实现平滑过渡,DiTCtrl采用了潜在混合策略。
关键观察与技术细节
注意力机制分析
研究人员对 MM-DiT 的注意力机制进行了深入分析,发现其 3D 全注意力机制与类似 UNet 的扩散模型中的交叉/自注意力块行为相似。具体来说,MM-DiT 中的注意力矩阵可以分解为四个不同的区域:
文本到文本(Text-to-Text) 视频到视频(Video-to-Video) 文本到视频(Text-to-Video) 视频到文本(Video-to-Text)
以提示“一只猫看着一只黑老鼠”为例,研究人员观察到每个文本标记在分析文本到视频和视频到文本区域的平均注意力值时表现出显著的激活模式。这表明 MM-DiT 的注意力机制不仅能够捕捉文本和视频之间的关联,还能在时间维度上建模视频内容的变化。
掩码引导的键值共享策略
为了实现多提示视频生成,DiTCtrl 引入了 掩码引导的键值共享策略。具体来说,在视频合成的去噪过程中,研究人员将全注意力机制转换为掩码引导的键值共享策略,从源视频 ( V_{i-1} ) 中查询视频内容,并在修改后的目标提示 ( P_i ) 下合成内容一致的视频。这一策略确保了不同提示之间的平滑过渡和一致的对象运动。
初始潜在帧假设:假设初始潜在帧为 5 帧,前三帧用于生成前一个提示 ( P_{i-1} ) 的内容,后三帧用于生成当前提示 ( P_i ) 的内容。粉色潜在帧表示重叠帧,而蓝色和绿色潜在帧用于区分不同的提示片段。
MPVBench:多提示视频生成基准
为了评估多提示视频生成的性能,研究人员还提出了 MPVBench,这是一个专门为多提示视频生成设计的新基准。MPVBench 包含多种类型的过渡效果,包括背景过渡、运动过渡、身份过渡和相机视角过渡,用于全面评估模型的提示跟随能力和过渡平滑性。
实验结果与应用
多提示视频生成
DiTCtrl 在生成多提示视频时表现出色,能够在给定多个顺序提示的情况下实现平滑过渡和一致的对象运动。研究人员展示了多种类型的过渡效果,充分体现了该方法的多样性。例如,在描绘男孩骑行序列时,DiTCtrl 展现了电影风格的过渡效果,尽管无需额外训练。
单提示长视频生成
尽管 DiTCtrl 主要针对多提示视频生成任务,但通过将顺序提示设置为相同,该方法也可以应用于单提示长视频生成。这表明 DiTCtrl 能够增强长视频生成中单提示的一致性,确保视频内容在整个时间段内保持连贯。
视频编辑——词语替换
通过去除 DiTCtrl 的潜在混合策略,研究人员实现了词语替换的视频编辑效果。具体来说,仅使用掩码引导的键值共享策略来共享源提示 ( P_{\text{source}} ) 分支的键和值,从而生成一个新视频,既保留原始构图,又响应新提示 ( P_{\text{target}} ) 的内容。
视频编辑——重加权
类似于 prompt-to-prompt 方法,研究人员通过重新加权 MM-DiT 的文本-视频注意力和视频-文本注意力中与指定标记(例如“粉色”和“雪”)对应的特定列和行,实现了重加权的视频编辑效果。这一功能使得用户可以根据需要调整视频中的特定元素,进一步增强了视频编辑的灵活性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











