图森未来今日正式发布了其首款“图生视频”大模型——Ruyi,目前Ruyi-Mini-7B版本已经正式释出。这款模型专为生成高质量的影视级视频而设计,能够在消费级显卡(如 RTX 3090 或 RTX 4090)上无精度损失地支持最小384*384,最大1024*1024分辨率,任意长宽比,最长120帧/5秒的视频生成,支持多种分辨率和时长的视频生成。Ruyi 支持多种分辨率和时长的视频生成,并提供了镜头控制和运动幅度控制等功能,旨在简化动漫和游戏内容的开发流程,降低开发周期和成本。
Ruyi 的核心技术
Ruyi 是基于 DiT 架构 的图生视频模型,由两个主要模块构成:
- Casual VAE 模块:负责视频数据的压缩和解压,确保视频生成过程中的高效处理。
- Diffusion Transformer 模块:负责生成压缩后的视频,通过扩散模型逐步生成高质量的视频帧。
模型的总参数量约为 7.1B,使用了约 200M 个视频片段 进行训练,使其能够生成多样化的视觉效果。
主要功能
- 多分辨率、多时长生成:支持最小 384x384 到最大 1024x1024 分辨率,任意长宽比,最长 120 帧(5 秒)的视频生成。
- 首帧、首尾帧控制生成:支持最多 5 个起始帧和 5 个结束帧的输入,通过循环叠加可以生成任意长度的视频。
- 运动幅度控制:提供 4 档运动幅度控制(1: 基本不运动,2: 正常运动幅度,3: 较大运动幅度,4: 非常大运动幅度),方便用户调整画面变化程度。
- 镜头控制:支持 5 种镜头控制方式(上、下、左、右、静止),帮助用户更好地掌控视频的视角变化。
应用场景
Ruyi 专为简化动漫和游戏内容的开发而设计,能够显著缩短开发周期并降低成本。例如,用户可以输入关键帧,由模型自动生成后续 5 秒的内容,或输入两个关键帧,让模型生成中间的过渡内容。这使得创作者能够更高效地制作高质量的动画和游戏素材。
当前局限与改进方向
尽管 Ruyi 已经具备了强大的功能,但目前仍存在一些问题,如手部畸形、多人时面部细节崩坏、不可控转场等。图森未来表示,这些问题正在积极改进中,并将在未来的更新中修复。
ComfyUI 安装与使用
为了方便用户快速上手,Ruyi 提供了详细的部署说明和 ComfyUI 工作流支持。以下是安装和使用 Ruyi 的步骤:
通过 ComfyUI Manager 安装
主要涉及两个ComfyUI节点ComfyUI-Ruyi和ComfyUI-VideoHelperSuite,你可以手动下载安装,不过推荐大家使用ComfyUI Manager进行安装:
- 启动 ComfyUI 并打开ComfyUI Manager,选择 Custom Nodes Manager,搜索 “Ruyi”,点击 Install 按钮安装。
- 安装 ComfyUI-VideoHelperSuite,以获得更多的辅助工具
插件地址:
- ComfyUI-Ruyi地址:https://github.com/IamCreateAI/Ruyi-Models
- ComfyUI-VideoHelperSuite地址:https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite

下载模型
- 可选步骤:下载 Ruyi 模型并将其保存到指定路径。建议将模型保存到
ComfyUI/models/Ruyi/文件夹中 - 自动下载:ComfyUI 支持自动下载模型功能,用户可以通过设置
auto_download选项来自动下载模型
节点介绍
Load Model
用于加载模型,并提供自动下载模型(通过 auto_download 选项设置)的功能
- model: 选择使用哪个模型,目前只有 Ruyi-Mini-7B 一个选项
- auto_download: 是否自动下载,默认为 yes,检测到模型不存在(或不完整)时,将自动下载模型到 ComfyUI/models/Ruyi 路径

Load LoRA
用于加载 LoRA 模型,LoRA 模型需要放在 ComfyUI/models/loras 路径下,目前还没有Lora推出
- lora_name: 需要加载的 LoRA,将自动搜索并显示 ComfyUI/models/loras 路径下所有模型文件。
- strength_model: LoRA 的影响程度,根据经验通常设置在 1.0 ~ 1.4 效果较好。
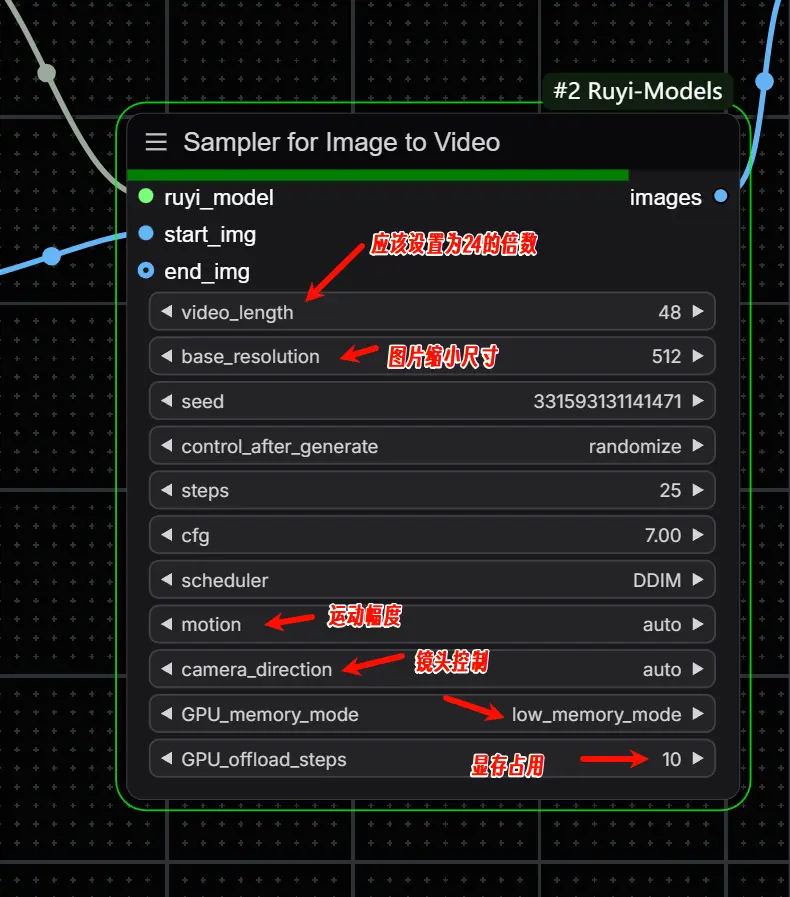
Sampler for Image to Video
用于根据输入图片生成视频,首帧图片(start_img)为必须输入,尾帧图片(end_img)为可选输入。同时,该节点支持镜头控制(camera_direction)与视频主体的运动幅度控制(motion)。
- start_img: 首帧图片。
- end_img: 尾帧图片,可选输入。
- video_length: 视频长度,必须能被 8 整除,最大支持 120 帧,这还要看视频的帧率,默认帧率是24,如果设置120 帧,那么生成的视频就是5秒,因此长度应该设为帧率的倍数。
- base_resolution: 视频分辨率,模型将根据输入图片的长宽比自动选择最接近的输出视频长宽。
- 512 表示生成的视频像素数接近 512 * 512
- 768 表示生成的视频像素数接近 768 * 768
- seed: 随机种子,用于控制随机数生成器产生随机数的序列。不同的随机种子通常能生成不同的视频,当生成的视频不符合需求时候,可调整此值以尝试其他的生成可能。
- control_after_generate: 每次生成后随机种子的变化方式。
- Fixed 表示随机种子固定不变。
- Increment 表示随机种子每次增加一。
- Decrement 表示随机种子每次减少一。
- Randomize 表示随机种子运行后随机设置。
- steps: 视频生成的迭代次数,迭代次数越多,需要的时间越久,通常 25 次能够得到较好的结果。
- cfg: 指令(如输入图片)的遵循程度,数值越大遵循程度越好,取值 7 ~ 10 通常能取得较好的生成效果。
- motion: 控制视频主体的运动幅度。
- 1 基本不运动,适用于静态场景。
- 2 正常运动幅度,适用于谈话、转头等常见场合。
- 3 运动幅度较大,可能出现转身、走动等情况。
- 4 运动幅度非常大,可能出现视频主体离开画面的情况。
- Auto 表示模型自动判断运动幅度大小。
- camera_direction: 镜头运动。
- Static 表示静止镜头。
- Left 表示镜头向左移动。
- Right 表示镜头向右移动。
- Up 表示镜头向上移动。
- Down 表示镜头向下移动。
- Auto 表示模型自动判断镜头运动方向。
- GPU_memory_mode:
- normal_mode 是默认模式,使用显存较多,生成速度较快。
- low_memory_mode 是低显存模式,能大幅降低显存用量,但严重影响生成速度。
- GPU_offload_steps: 用于优化显存占用,通过将部分临时变量从显存移动到内存而实现,会增加内存的占用并降低生成速度。
- 0 表示不优化。
- 1 - 10,1 显存占用最小,生成速度最慢;10 显存占用最多(少于不优化情况),生成速度最快。
- 通常情况下,24G 显存可以使用 7 生成 512 分辨率,120 帧视频。
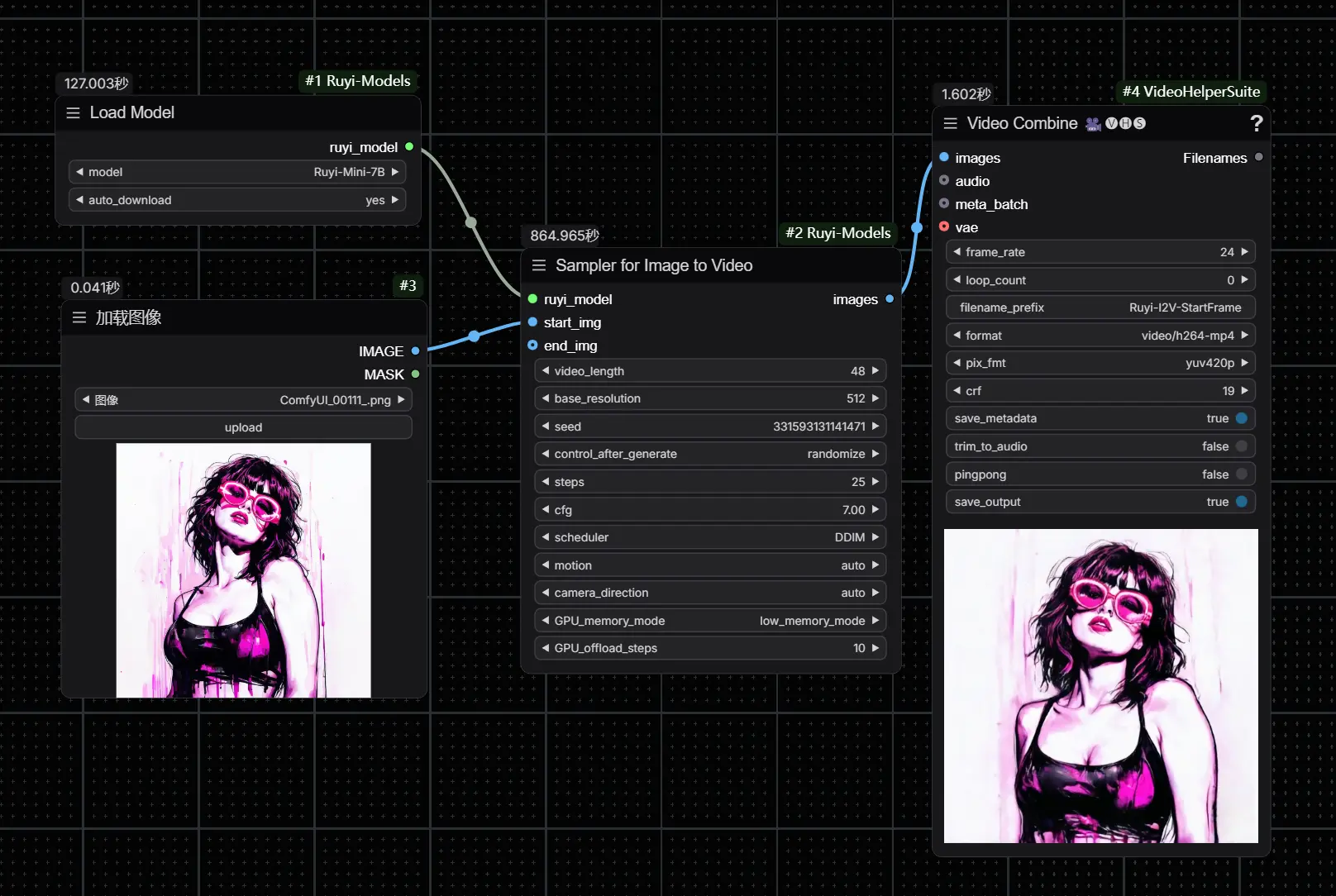
工作流样例
工作流位于 Ruyi-Models\comfyui\workflows目录下,直接将工作流拖入ComfyUI即可。
- 图生视频(首帧):对应
workflow-ruyi-i2v-start-frame.json文件,适用于仅输入首帧的情况。对于显存较大的用户,也可以使用 workflow-ruyi-i2v-start-frame-80g.json 以提高生成速度。 - 图生视频(首尾帧):对应
workflow-ruyi-i2v-start-end-frames.json文件,适用于输入首帧和尾帧的情况。对于显存较大的用户,也可以使用 workflow-ruyi-i2v-start-end-frames-80g.json 以提高生成速度。
常见问题
- 模型加载错误:
通常是网络问题导致 huggingface_hub 下载失败,网络正常的情况下,再次运行 LoadModel 节点即可解决
- 视频生成速度慢:
请检查是否开启了 GPU_memory_mode 的 low_memory_mode,此模式会大幅降低生成速度。此外,确保使用最新版本的 PyTorch(2.2 版本支持 FlashAttention-2,能大幅提升计算效率)
- 显存占用及生成时间:
以本人英伟达4070 12G显卡为例,按照上图选择low_memory_mode,生成1秒视频大概需要6分钟;如果选择normal_mode就会爆显存

- 图片比例问题
使用此模型生成视频,需要注意图片的比例问题,因为训练素材的问题,如果是非常规尺寸图片,生成的视频会在视频左侧出现蓝色大竖条;建议大家使用的图片比例1:1、9:16、16:9等这样的视频常用比例,比如使用1024X1024尺寸的图片。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











