
腾讯于本月初开源的混元文生视频模型HunyuanVideo,这是一款参数量超过130亿的大型视频生成模型,这款模型由于参数大、生成效果好及未作审查(可生成NSFW内容)等原因,受到开源社区欢迎。ComfyUI社区大神kijai也在第一时间推出了混元模型的ComfyUI节点以及量化模型,可实现文生视频、视频转视频。另有开发者Dango233基于kijai的插件,通过通过视觉语言模型(VLM)实现图像提示到视频的生成。

一、ComfyUI-HunyuanVideoWrapper
kijai推出的ComfyUI节点,需要下载以下模型
模型和 VAE(单文件,无自动下载):
将文件放入通常的 ComfyUI 文件夹(diffusion_models 和 vae)
LLM 文本编码器(支持自动下载):
文件放入 ComfyUI/models/LLM/llava-llama-3-8b-text-encoder-tokenizer
Clip 文本编码器(支持自动下载):
你可以选择以下两种方式之一:
- 使用 ComfyUI 支持的任何
Clip_L模型,通过禁用文本编码器加载器中的clip_model,并将ClipLoader连接到文本编码器节点。 - 允许自动下载器从以下链接获取原始的 Clip 模型:
只需要
.safetensor文件和所有配置文件,放入ComfyUI/models/clip/clip-vit-large-patch14。
显存使用说明:
显存使用完全取决于分辨率和帧数,即使在 24GB 显存的情况下,也不要期望能够处理非常高的分辨率。好消息是,即使在非常低的分辨率下,模型也能生成功能性的视频。kijai还推出了混元模型FP8量化版,12G显存就可以运行。
二、ComfyUI-HunyuanVideoWrapper-IP2V
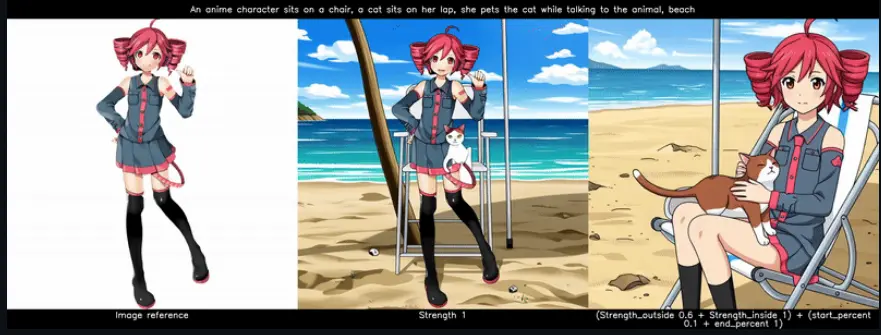
通过是视觉语言模型(VLM)来实现图像提示到视频生成,现在你可以将图像作为生成的条件输入到 VLM 中!这与图像到视频(image2video)不同,后者将图像作为视频的第一帧。IP2V 使用图像作为提示的一部分,提取图像的概念和风格。因此,非常类似于 IPAdapter,但 VLM 会为你完成繁重的工作!
注意:
- 最低需要 20GB 显存(VLM 量化尚未实现)
- 这改变了 @kijai 原始节点的行为。因此,如果你想测试此功能,请在 PR 合并到 Kijai 的仓库之前,将你的 git 指向此分支并拉取更新,或者简单地删除原始仓库并拉取此仓库。
使用 xtuner/llava-llama-3-8b-v1_1-transformers 进行图像-文本任务的指南
步骤 1:模型选择
使用原始的 xtuner/llava-llama-3-8b-v1_1-transformers 模型,该模型包含视觉塔。你有两个选择:
- 下载模型并将其放置在
models/LLM文件夹中。 - 依赖自动下载机制。
注意: 建议卸载文本编码器,因为视觉塔需要额外的显存。
步骤 2:设置模型类型
将 lm_type 设置为 vision_language。
步骤 3:加载并连接图像
使用 Comfy 原生节点加载图像。
将加载的图像连接到 Hunyuan TextEncode 节点。
你可以将最多 2 张图像连接到此节点。
步骤 4:使用图像进行提示
在你的提示中通过包含 <image> 来引用图像。<image> 标签的数量应与提供给采样器的图像数量匹配。
示例提示:详细描述这张 <image>。
你也可以选择给 CLIP 一个不单独引用图像的提示。
步骤 5:高级配置 - image_token_selection_expression
此表达式适用于高级用户,作为布尔掩码,用于选择图像隐藏状态的哪一部分将用于条件生成。以下是一些详细信息和建议:
- LLaVA-LLaMA-3 中每张图像的隐藏状态序列长度(或令牌数量)为 576。
- 默认设置为
::4,意味着每四个令牌中有一个令牌用于条件生成,交错进行,每张图像产生 144 个令牌。 - 通常,更多的令牌更倾向于条件图像。
- 然而,过多的令牌(尤其是当总令牌数超过 256 时)会降低生成质量。建议不要使用超过一半的令牌(
::2)。 - 交错令牌通常表现更好,但你也可以尝试以下表达式:
:128- 前 128 个令牌。-128:- 后 128 个令牌。:128, -128:- 前 128 个令牌和后 128 个令牌。
通过适当的提示策略,即使不传递任何图像令牌(将表达式留空),也可以产生不错的效果。
三、ComfyUI-HunyuanVideo-Nyan
ComfyUI-HunyuanVideo-Nyan 是一个专为 ComfyUI 设计的自定义节点包,旨在扩展 CLIP(对比语言-图像预训练模型)和 LLM(大型语言模型)在视频生成中的应用。通过引入两个不同的 "Nyan 节点" 和一个极客风格的 Transformer 洗牌节点,该工具包为用户提供了更多的创意和实验性功能。
安装与配置
1、文件夹放置:
仅需将此仓库中的 ComfyUI... 文件夹放入 ComfyUI/custom_nodes 中。 确保只有这个文件夹 位于 ComfyUI/custom_nodes 中,而不是整个仓库的内容。 ComfyUI/custom_nodes/ComfyUI-HunyuanVideo-Nyan 文件夹中应该包含一个 init.py 文件。如果看到 README.md,则说明放置错误。
2、依赖项:
需要安装 kijai/ComfyUI-HunyuanVideoWrapper。 如果某些功能因 WIP(正在进行中)而损坏,可以暂时回退到我的 fork 以确保兼容性。
3、加载器节点:
加载器节点是必要的,因为修改会改变模型缓冲区;如果不重新加载,更改会累积。 你可以选择从文件重新加载或从 RAM 深度复制(更快,但可能需要 >64 GB RAM)。
主要功能
1、扩展 CLIP 和 LLM 的影响力:
CLIP 模型的重要性:对于默认的 Hunyuan Video 来说,CLIP 模型似乎不太重要,但在使用此节点时,CLIP 模型变得至关重要。 推荐的 CLIP 模型: huggingface.co/zer0int/CLIP-SAE-ViT-L-14:支持 248 个 token,稍微不可预测。 huggingface.co/zer0int/LongCLIP-GmP-ViT-L-14:支持更长的文本输入,适合复杂的提示。
2、Factor 参数:
Factor 是用于扩展 CLIP 和 LLM 影响力的参数。它可以增强或减弱 CLIP 和 LLM 在视频生成中的作用。 示例提示:高质量的自然视频,一只红熊猫在竹竿上保持平衡,一只鸟落在熊猫的头上,背景中有瀑布。 SAE 模型:使用 SAE 模型时,鸟至少会飞(尽管起飞),熊猫的脚更好(对比 OpenAI)。这些细节展示了 SAE 模型在处理复杂场景时的优势。
3、极客风格的 Transformer 洗牌节点:
洗牌层:随机打乱 Transformer 中的层顺序,创造出独特的视觉效果。 跳过层:跳过某些层,减少计算量,同时可能产生意想不到的效果。 应用场景:这些操作可以为视频生成带来更多的创意和实验性效果,适合那些喜欢探索和尝试新技术的用户。
注意事项
RAM 要求:从 RAM 深度复制模型时,可能需要 >64 GB RAM,具体取决于模型大小和视频分辨率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











