视频扩散模型是一种强大的生成模型,能够生成高质量的视频内容。然而,传统的视频扩散模型在生成视频时需要大量的迭代去噪步骤,这使得生成过程非常缓慢且计算成本高昂。例如,HunyuanVideo 模型在单个英伟达 A100 GPU 上生成一段 5 秒、720×1280 分辨率、24fps 的视频需要 3234 秒。
- 项目主页:https://aejion.github.io/accvideo
- GitHub:https://github.com/aejion/AccVideo
- 模型:https://huggingface.co/aejion/AccVideo
为了解决这一问题, 北京航空航天大学、上海人工智能实验室和香港大学的研究人员提出了一种名为 AccVideo 的方法,通过知识蒸馏技术,将生成速度提高了 8.5 倍,同时保持了与原始模型相当的生成质量。

主要功能
- 加速视频生成:AccVideo 方法通过减少采样步骤,将视频生成速度提高了 8.5 倍。例如,原本需要 3234 秒生成的视频,现在仅需 380 秒左右。
- 保持生成质量:在加速的同时,AccVideo 生成的视频质量与原始模型相当,甚至在某些方面(如颜色和空间关系)表现更好。
- 支持高分辨率视频生成:AccVideo 能够生成高质量的高分辨率视频,例如 720×1280 分辨率的视频,而不仅仅是低分辨率视频。
主要特点
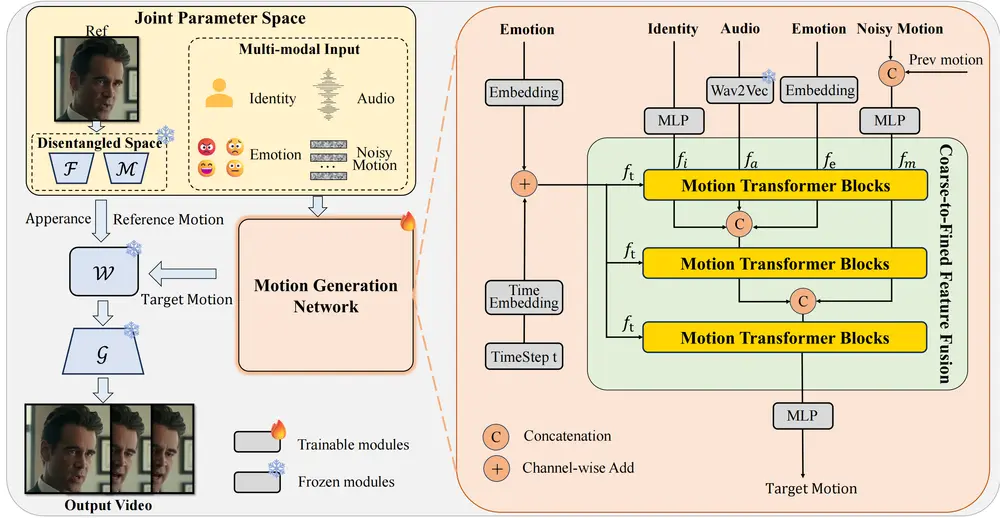
- 合成数据集(SynVid):AccVideo 使用预训练的视频扩散模型生成的合成数据集进行蒸馏,避免了在蒸馏过程中使用无用数据点的问题。这些数据点都是有效的去噪轨迹上的中间结果,从而提高了蒸馏效率。
- 轨迹引导的少步指导(Trajectory-based Few-step Guidance):通过选择关键数据点,AccVideo 设计了一种少步指导机制,使学生模型能够在更少的步骤内学习从噪声到视频的映射关系。
- 对抗训练策略(Adversarial Training Strategy):利用合成数据集捕获的每个扩散时间步的数据分布,AccVideo 引入了对抗训练策略,进一步提升生成视频的质量。
- 轻量级训练:AccVideo 的训练过程仅需 8 块 A100 GPU,训练 12 天即可完成,相比其他方法更加高效。
工作原理
- 合成数据集构建:AccVideo 使用预训练的视频扩散模型(如 HunyuanVideo)生成 110K 条去噪轨迹和高质量视频,这些数据构成了合成数据集 SynVid。这些数据点都是有效的去噪轨迹上的中间结果,避免了无用数据点的干扰。
- 轨迹引导的少步指导:AccVideo 从每条去噪轨迹中选择关键数据点,构建一个从噪声到视频的短路径。通过这种少步指导机制,学生模型能够在更少的步骤内学习到去噪过程。
- 对抗训练策略:AccVideo 利用合成数据集捕获的每个扩散时间步的数据分布,通过对抗训练策略对齐学生模型的输出分布,从而提升生成视频的质量。
- 整体训练过程:AccVideo 的训练过程包括轨迹引导的少步指导损失(Ltraj)和对抗训练损失(Ladv)。通过结合这两种损失,AccVideo 在加速生成的同时,保持了高质量的视频输出。
应用场景
- 内容创作:AccVideo 可以快速生成高质量的视频内容,适用于视频制作、广告创作等领域。例如,可以根据文本提示快速生成一段描述特定场景的视频。
- 娱乐产业:在电影制作、视频游戏开发等领域,AccVideo 可以快速生成高质量的视频片段,提高内容创作效率。
- 个性化媒体生成:AccVideo 可以根据用户输入的文本描述,快速生成个性化的视频内容,例如生成用户描述的虚拟场景或角色动画。
- 视频编辑:AccVideo 可以快速生成视频片段,用于视频编辑中的过渡、特效等部分,提高视频编辑的效率和灵活性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











