在AI技术的浪潮中,视频生成技术正逐渐成为新的热点。阿里巴巴集团通义实验室紧跟技术前沿,于2月21日宣布开源其先进的视频生成模型——WanX 2.1。然而,在发布过程中出现了一个小插曲,模型名称由WanX改为Wan,原因是“WanX”在英语俚语中具有不雅含义。
阿里巴巴集团通义实验室于 2 月 25 日正式开源了其最新一代视频生成模型 Wan2.1。这款模型不仅功能强大,还具有广泛的适用性,这款模型早前已在通义万象和阿里百炼平台上线,模型可在Hugging Face和魔塔社区上线。
什么是 Wan2.1?
Wan2.1 是一款由阿里巴巴通义实验室自主研发的先进视觉生成模型。它能够根据文本、图像或其他控制信号生成高质量的视频内容,适用于多种应用场景,包括但不限于创意设计、影视制作和教育领域。
- 项目主页:https://wanxai.com
- GitHub:https://github.com/Wan-Video/Wan2.1
- 模型:https://huggingface.co/Wan-AI
- ComfyUI插件:https://github.com/kijai/ComfyUI-WanVideoWrapper
- Demo:Hugging Face|魔塔
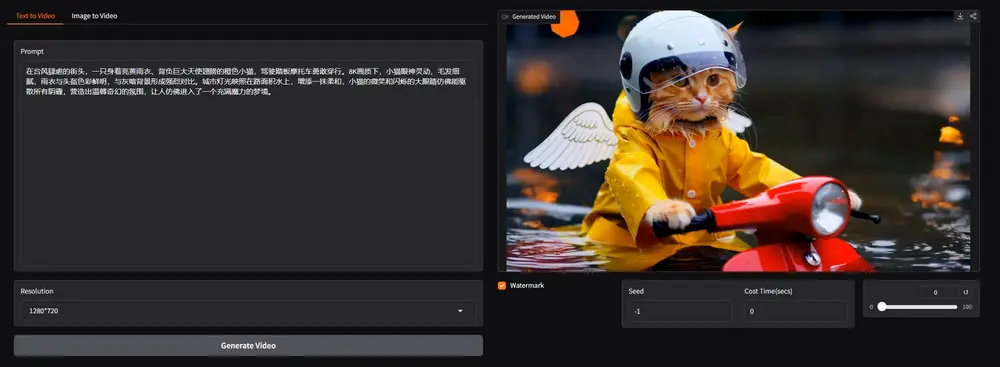
开源内容
Wan2.1 的代码和模型已在开源仓库中发布,这是一个全面且开放的视频基础模型套件,旨在推动视频生成技术的边界。
Wan2.1支持中英文视频,都可以一键生成艺术字,还提供多种视频特效选项,以增强视觉表现力,例如过渡、粒子效果、模拟等等。其还支持复杂运镜,可还原碰撞、反弹、切割、挤压等真实世界的物理规律,例如雨滴落在伞上会溅起水花。

Wan2.1 的关键特性包括:
- SOTA 性能:在多个基准测试中,Wan2.1 的性能始终优于现有的开源模型和最先进的商业解决方案。
- 消费级 GPU 支持:T2V-1.3B 模型仅需 8.19 GB 显存,与几乎所有消费级 GPU 兼容,性能可与一些闭源模型相媲美。
- 多任务能力:在文本到视频、图像到视频、视频编辑、文本到图像和视频到音频方面表现出色。
- 视觉文本生成:Wan2.1 是首个能生成中文和英文文本的视频模型,具有强大的文本生成功能。
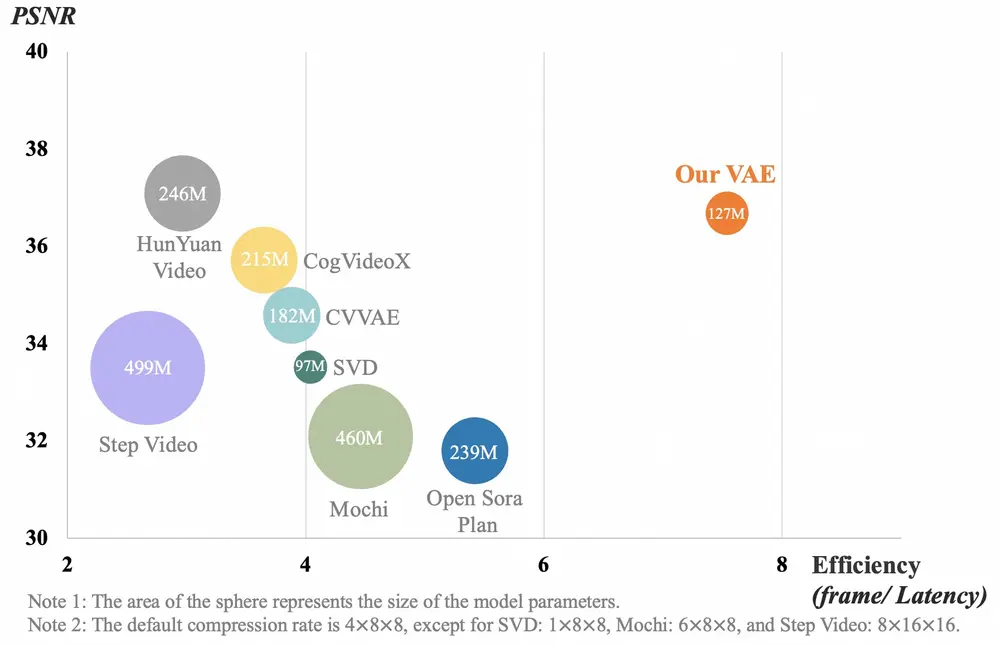
- 强大的视频 VAE:Wan-VAE 提供卓越的效率和性能,编码和解码任何长度的 1080P 视频,同时保留时间信息。
模型系列
Wan2.1 系列包括多个模型,每个模型都有其独特的优势和应用场景:
- Wan2.1-I2V-14B:在文本和图像生成视频方面实现了 SOTA 性能,能够生成展示复杂视觉场景和运动模式的视频。
- Wan2.1-T2V-14B:在开源和闭源模型中都创造了新的 SOTA 性能,展示了其生成具有强大运动动态的高质量视觉效果的能力。
- Wan2.1-T2V-1.3B:支持在几乎所有消费级 GPU 上进行视频生成,仅需 8.19 GB 显存即可生成 5 秒的 480P 视频。
模型下载
| 模型 | 下载地址 | 注释 |
|---|---|---|
| T2V-14B | 🤗 Huggingface 🤖 ModelScope | 支持生成480P和720P |
| I2V-14B-720P | 🤗 Huggingface 🤖 ModelScope | 支持生成720P |
| I2V-14B-480P | 🤗 Huggingface 🤖 ModelScope | 支持生成480P |
| T2V-1.3B | 🤗 Huggingface 🤖 ModelScope | 支持生成480P |
注意:1.3B 模型能够生成 720P 分辨率的视频。然而,由于在该分辨率下的训练有限,结果通常不如 480P 稳定。为了获得最佳性能,官方建议使用 480P 分辨率。
技术报告
Wan2.1 基于主流的扩散变换器范式设计,通过一系列创新实现了生成能力的重大进步。这些创新包括新颖的时空变分自编码器(VAE)、可扩展的训练策略、大规模数据构建和自动化评估指标。这些贡献共同增强了模型的性能和多功能性。
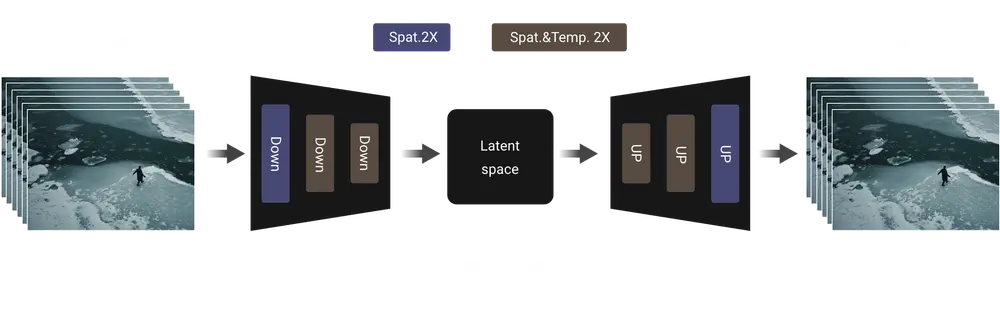
3D 变分自编码器
开发团队提出了一种新的3D因果VAE架构,称为 Wan-VAE,专为视频生成设计。通过结合多种策略,开发团队改进了时空压缩,减少了内存使用,并确保了时间因果性。Wan-VAE 在性能效率方面相比其他开源VAE具有显著优势。此外,Wan-VAE 能够对不限长度的1080P视频进行编码和解码,而不会丢失历史时间信息,使其特别适合视频生成任务。
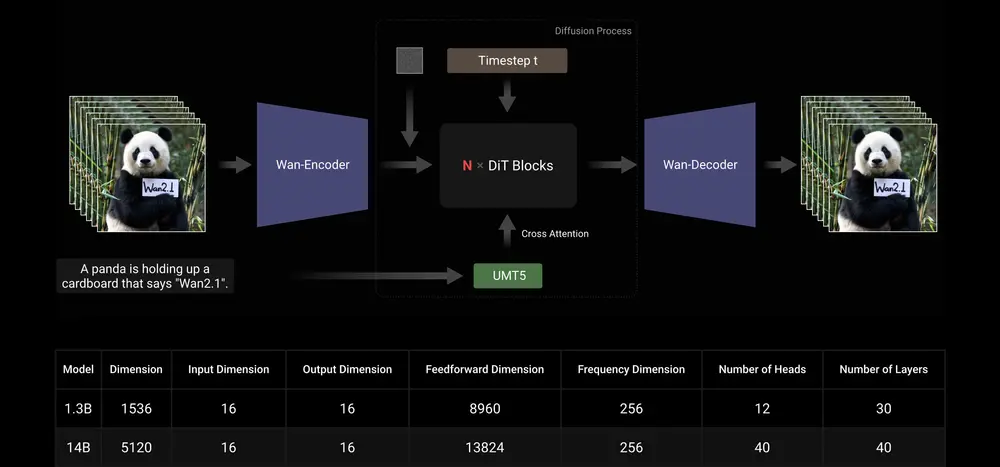
视频扩散 DiT
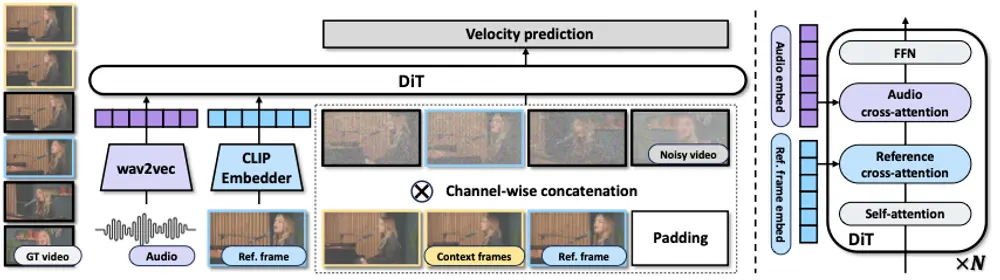
Wan2.1 采用主流扩散变换器范式中的流匹配框架设计。模型架构使用T5编码器对多语言文本输入进行编码,并在每个变换器块中通过交叉注意力将文本嵌入到模型结构中。
此外,开发团队使用一个包含线性层和SiLU层的MLP来处理输入的时间嵌入,并单独预测六个调制参数。该MLP在所有变换器块之间共享,每个块学习一组不同的偏差。实验结果表明,在相同参数规模下,这种方法显著提高了性能。
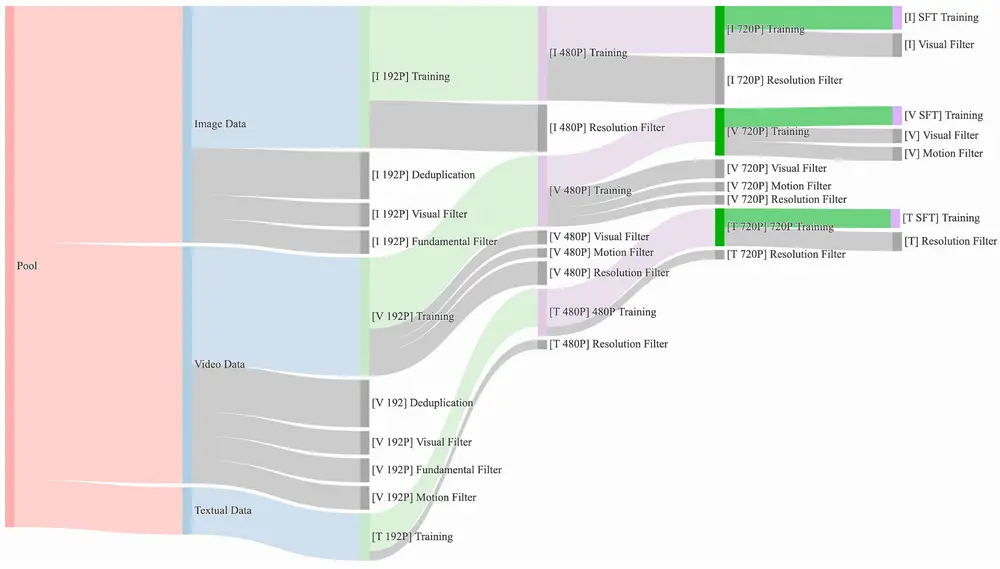
数据
开发团队精心策划并去重了一个包含大量图像和视频数据的候选数据集。在数据整理过程中,开发团队设计了一个四步数据清洗流程,重点在于基础维度、视觉质量和动态质量。通过强大的数据处理管道,开发团队可以轻松获得高质量、多样化且大规模的图像和视频训练集。
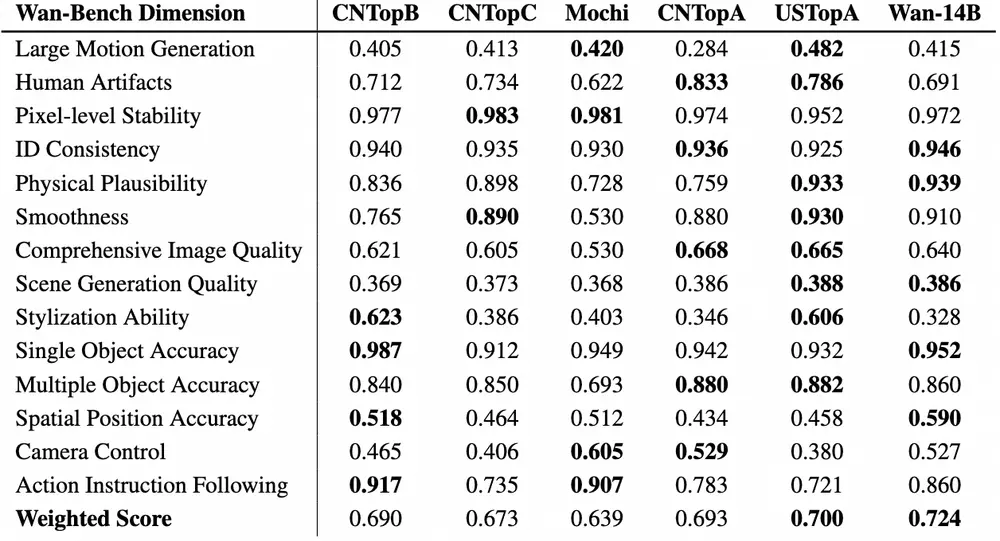
与SOTA的比较
为了评估性能,开发团队将Wan2.1与领先的开源和闭源模型进行了比较。使用开发团队精心设计的一组1,035个内部提示,开发团队在14个主要维度和26个子维度上进行了测试。
然后,根据每个维度的重要性,通过加权平均计算总分。详细结果如下表所示。这些结果表明,Wan2.1相较于开源和闭源模型具有更优的表现。
许可协议
Wan2.1 模型遵循 Apache 2.0 许可证发布。用户可以自由使用这些模型,但需确保遵守许可证的相关规定。同时,用户需对其生成的内容负责,不得涉及任何违法或有害行为。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











