
昆仑万维近日开源了国内首个面向 AI 短剧创作的视频生成模型 SkyReels-V1,以及国内首个 SOTA 级别基于视频基座模型的表情动作可控算法 SkyReels-A1,这款模型已在昆仑万维海外AI平台SkyReels上线。
- SkyReels-V1:https://github.com/SkyworkAI/SkyReels-V1
- SkyReels-A1:https://github.com/SkyworkAI/SkyReels-A1
- 模型:https://huggingface.co/collections/Skywork/skyreels-v1-67b34676ff65b4ec02d16307
- Demo:https://huggingface.co/spaces/Skywork/skyreels-a1-talking-head

SkyReels-V1:影视级视频生成模型
模型背景与训练
SkyReels-V1 是基于腾讯开源的混元视频生成大模型 HunyuanVideo 微调而成,训练数据集包含超过 1000 万段高质量影视片段。这些数据经过精心筛选,涵盖好莱坞级别的表演细节、情绪、场景和表演诉求等,确保生成的视频具备“电影级质感”。

功能亮点
SkyReels-V1 支持多种生成方式和功能,包括:
- 影视级人物微表情表演生成:支持 33 种人物表情与 400 + 种自然动作组合,能够还原真人情感表达,生成大笑、怒吼、惊讶、哭泣等微表情。
- 影视化表情识别体系:涵盖 11 种影视戏剧中的人物表情,如不屑、不耐烦、无助、厌恶等。
- 人物空间位置感知:基于人体三维重建技术,理解视频中多人的空间相对关系,助力生成影视级人物站位。
- 行为意图理解:构建超过 400 种行为语义单元,精准理解人物行为。
- 表演场景理解:关联人物、服装、场景和剧情,生成更具连贯性的视频。
此外,SkyReels-V1 不仅支持文生视频(Text-to-Video),还支持图生视频(Image-to-Video),在开源视频生成模型中参数量最大,支持图生视频功能。在同等分辨率下,各项指标均达到开源 SOTA(State-of-the-Art)水平。
性能优化
SkyReels-V1 配备了自研推理优化框架 SkyReels-Infer,显著提升了推理速度和效率:
- 在 544p 分辨率下,单台 4090 GPU 推理用时仅需 80 秒。
- 支持分布式多卡并行,包括 Context Parallel、CFG Parallel 和 VAE Parallel。
- 通过 fp8 quantization 和 parameter-level offload,满足低显存用户级显卡运行需求。
- 支持 flash attention 和 SageAttention 等优化技术,进一步降低延迟。
推理框架优势
SkyReels-Infer 是一个高效的视频生成推理框架,具备以下特点:
- 多 GPU 推理支持:通过上下文并行、CFG 并行和 VAE 并行,实现快速无损的视频制作,满足在线环境低延迟需求。
- 用户级 GPU 部署:采用模型量化和参数级卸载策略,显著降低 GPU 内存需求,适配消费级显卡。
- 卓越的推理性能:与 HunyuanVideo XDiT 相比,端到端延迟降低 58.3%,设定新的推理速度基准。
- 出色的可用性:基于开源框架 Diffusers 构建,采用非侵入式并行实现方法,确保无缝且用户友好的体验。
SkyReels-A1:表情动作可控算法
为了实现更加精准可控的人物视频生成,昆仑万维开源了 SOTA 级别的表情动作可控算法 SkyReels-A1。该算法对标 Runway 的 Act-One,支持视频驱动的电影级表情捕捉。
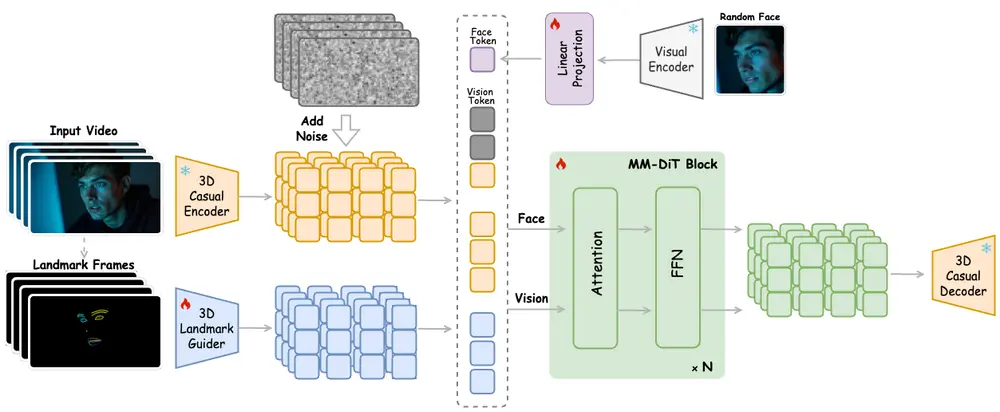
功能亮点
SkyReels-A1 的核心优势包括:
- 增强面部表情传递的精确性:确保生成的表情自然且连贯。
- 身份保持的稳定性:避免生成过程中的人物身份失真。
- 时间连贯性:解决背景不稳定和面部表情不自然的问题。
- 支持任意人体比例:包括肖像、半身及全身构图,生成高质量人物动态视频。
通过将参考人物图片和驱动视频作为输入,SkyReels-A1 能够将驱动视频中的面部表情和表演细节“移植”到给定参考图片的人物身上,生成全新的视频内容。
基准测试结果
SkyReels-V1 在开源文本到视频(T2V)模型中的性能表现出色。根据 VBench 基准测试结果,SkyReels-V1 实现了 82.43 的总分,高于其他开源模型,如 VideoCrafter-2.0 VEnhancer(82.24)和 CogVideoX1.5-5B(82.17)。
此外,SkyReels-V1 在动态度和多个对象等关键指标上取得最高分,表明其在处理复杂视频生成任务方面具有卓越能力。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











